-
-
Save navyxliu/9c325d5c445899c02a0d115c6ca90a79 to your computer and use it in GitHub Desktop.
| // -Xcomp -Xms16M -Xmx16M -XX:+AlwaysPreTouch -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC -XX:-UseOnStackReplacement -XX:CompileOnly='Example1.ivanov' -XX:CompileCommand=dontinline,Example1.blackhole | |
| class Example1 { | |
| private Object _cache; | |
| public void foo(boolean cond) { | |
| Object x = new Object(); | |
| if (cond) { | |
| _cache = x; | |
| } | |
| } | |
| // Ivanov suggest to make this happen first. | |
| // we don't need to create JVMState for the cloning Allocate. | |
| public void ivanov(boolean cond) { | |
| Object x = new Object(); | |
| if (cond) { | |
| blackhole(x); | |
| } | |
| } | |
| static void blackhole(Object x) {} | |
| public void test1(boolean cond) { | |
| //foo(cond); | |
| ivanov(cond); | |
| } | |
| public static void main(String[] args) { | |
| Example1 kase = new Example1(); | |
| // Epsilon Test: | |
| // By setting the maximal heap and use EpsilonGC, let's see how long and how many iterations the program can sustain. | |
| // if PEA manages to reduce allocation rate, we expect the program to stay longer. | |
| // Roman commented it with a resonable doubt: "or your code slow down the program..." | |
| // That's why I suggest to observe iterations. It turns out not trivial because inner OOME will implode hotspot. We don't have a chance to execute the final statement... | |
| long iterations = 0; | |
| try { | |
| while (true) { | |
| kase.test1(0 == (iterations & 0xf)); | |
| iterations++; | |
| } | |
| } finally { | |
| System.err.println("Epsilon Test: " + iterations); | |
| } | |
| } | |
| } |
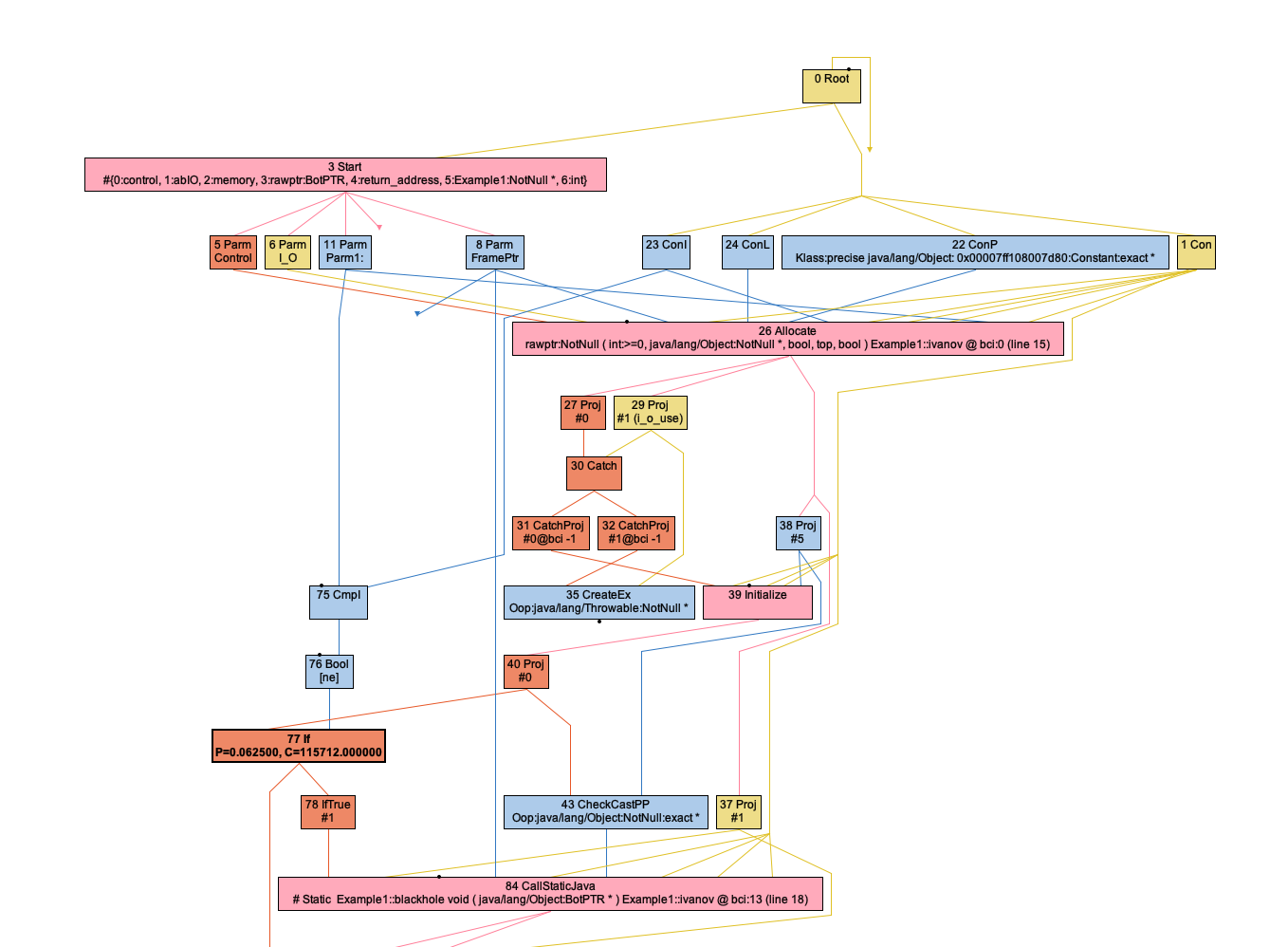
This the IR after parse, without PEA.
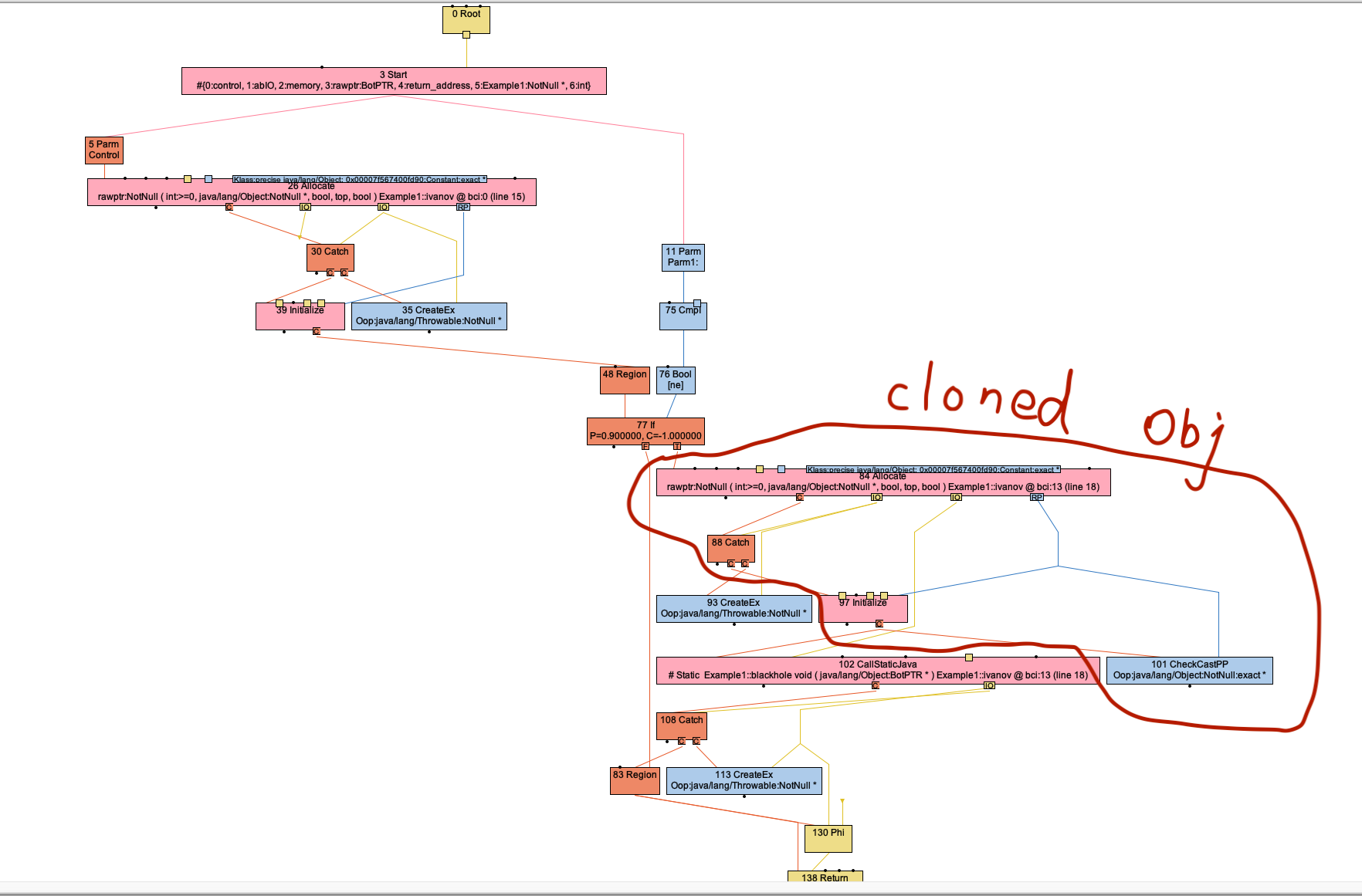
Here is the IR after parse with PEA. Please note that we clone the object. It's a cluster of nodes. 101 CheckCastPP is the argument of 102 CallStaticJava/Example1::blackhole. It's hid by the filter 'Simplify graph' of IGV.
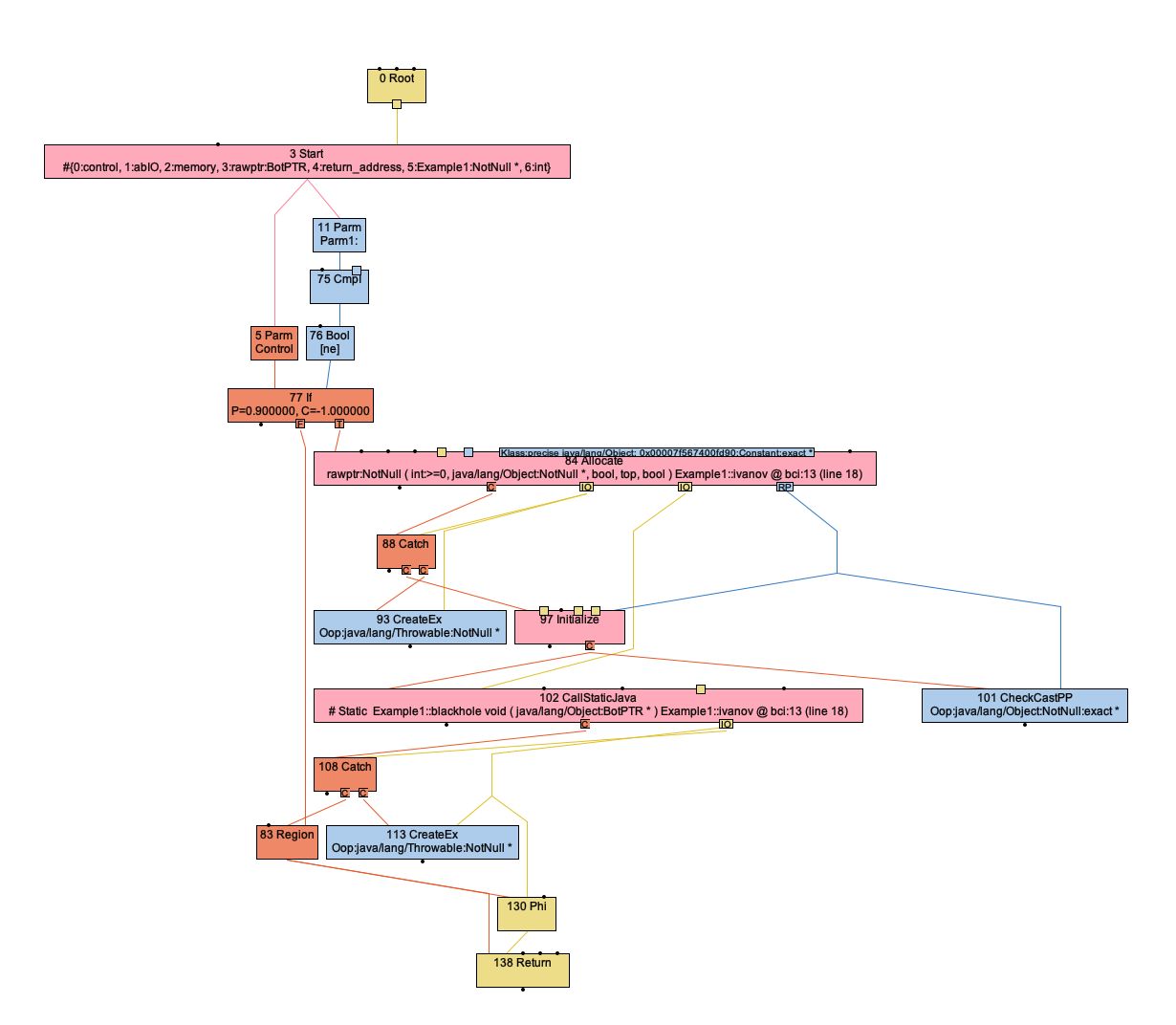
Even though it looks like we leave behind a redundancy, C2 EA/SR will eliminate the obsolete 26 Allocate! Here is the IR after Iterative EA. It is as if our PEA optimization moves the object under IfTrue.
the source code of my experimental PEA: https://github.com/navyxliu/jdk/tree/PEA_parser
I believe that JMH has prof:gc to acquire the allocation rate per iteration, maybe you can somehow use it for allocation rate of PEA. Thanks.
I believe that JMH has
prof:gcto acquire the allocation rate per iteration, maybe you can somehow use it for allocation rate of PEA. Thanks.
yes, I will convert this to a JMH. thanks!
This is a developing story.
if you are still interested, please follow it up -> Example2
The following code creates a phi node to merge 2 objects.
I believe RAM of JDK-8289943 can make the NonEscape object be replace in
public Object merge_node(boolean cond) {
Object x = new Object();
if (cond) {
_cache = x;
}
return x;
}
The is the generated code (-XX:+PrintOptoAssembly) for Example1::ivanov with DoPartialEscapeAnalysis.
please note that object allocation(B6) and initialization(B4) are both subject to
'testl RDX, RDX' on B1.