Partial Escape Analysis (PEA) is a flow sensitive analysis. It eagerly defers an object to the point where its object identity is required. This optimization avoids allocating the object on the paths where the object identity is not required.
Previously, we proposed to implement Stadler’s PEA algorithm 1 in OpenJDK HotSpot C2 2. We still stick with the algorithm and our high-level design. We are going to describes how we track allocation state and conduct materialization in C2 parser. The contribution of this paper is that we put forward piggybacking PEA on the parsing phase which lowers program from high-level IR to low-level IR. No extra pass is required in this approach.
PEA is flow-sensitive. Allocation state is the knowledge of objects the compiler has seen at any given program point. PEA tracks only objects created in the compilation unit. It assigns an identifier ObjID for each tracking object. For simplicity, we use the pointer of AllocateNode as its ObjID. ObjIDs are valid before renumbering phase. C2 does not renumber nodes until parsing phase and late-inlining phase are completed. It is safe because we do not encounter any new object after renumbering phase.
Allocation State answers the following two queries:
| Query | IN | OUT | Description |
|---|---|---|---|
| is_alias | Node* | ObjID | return a valid ObjID if the input points to a tracking object, or NULL |
| get_object_state | ObjID | ObjectState* | return the object state of ObjID |
Objects existing before current compilation unit such as arguments or global variables are not present in allocation state. is_alias() returns NULL for them. Therefore, they are intact throughout our PEA.
The state of an tracking object is binary. An object is virtual when it is born in current compilation unit. It remains virtual until it is materialized. PEA only materializes an object when its object identity is required. It happens at an escaping and merging point. If an object remains virtual after PEA, it neither has escaped nor merged with any materialized object. Therefore, it is eligible for scalar replacement. Our PEA purposely leaves it to C2 Escape Analysis and MacroExpansion phases. A virtual object is either completely eliminated or will be scalar-replaced.
Beside queries, allocation state also tracks all fields of a virtual object for materialization (will explain later). This is recursive because a field may be a reference to yet another tracking object.
PEA tracks the allocation state of an individual basic block. It diverges and merges allocation states along control flowgraph (CFG). C2 parser lowers a program from Java bytecode to low-level ideal graph (also referred to as sea-of-nodes). The CFG in bytecode and reverse post-order (RPO) are available before parsing phase.
Our first attempt was to merge a basic block for the allocation state all at once. This requires access to all its predecessors. Starting from the number of predecessors, path number or pnum of a basic block decrements when we merge an ordinary path. When pnum is 1, it suggests that we have seen all predecessors and it would be good time to merge allocation state. Unfortunately, this scheme doesn’t work! It turns out that the CFG established in bytecode isn’t exactly same as the CFG in ideal graph. Pnum increments when C2 merges an exception path or a new path spanning from bytecode tableswitch. I.e., pnum isn’t monotonic and thus can’t be used as a signal. We cannot merge allocation state when we are about to parse the basic block either. It is because C2 may keep merging through backedges after it has been parsed. To illustrate this problem, we model a basic block in parsing phase using Finite State Machine (FSM). The final state Done is fictional. I.e., we do not know when a block will stop seeing a new block.

It is possible to start PEA after parsing phase. That would require a new pass and we have to build CFG and RPO in ideal graph.
These constraints lead us to give up the merge processor described in 1. Instead, we decide to merge allocation state incrementally in C2 Parser. We embed allocation state in JVMState. One SafePointNode is bound to at least one JVMState. The youngest JVMState contains the current allocation state. We merge allocation state when we merge SafePointNodes.
Initially, C2 merges a basic block to an empty basic block, which has never been merged before. In figure, SAVE block merges to TARGET block over path pnum. A SafepointNode map is associated with SAVE.
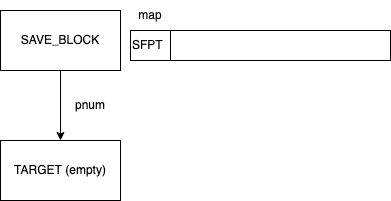
After merging, map of SAVE just passes to TARGET. The allocation state in JVMState of map is also moved. The state of TARGET changes from Empty to Merged in the FSM.

As illustrated above, a merged block TARGET now is associated with SafePointNode map. When we merge SAVE block to it again, we need to merge two SafePointNodes. At any merging point, they from two sources are aligned. With a given offset, node n from newin and node m from map refer to the same variable. If n and m are identical, merging is trivial. If they are different, C2 creates a PhiNode to merge them. If either m or n is tracked in any allocation state, we update the allocation state of map to phi. If the object states are different, we perform passive materialization. We are going to explain the term in next section.
Here is the illustration. Red lines are control edges.
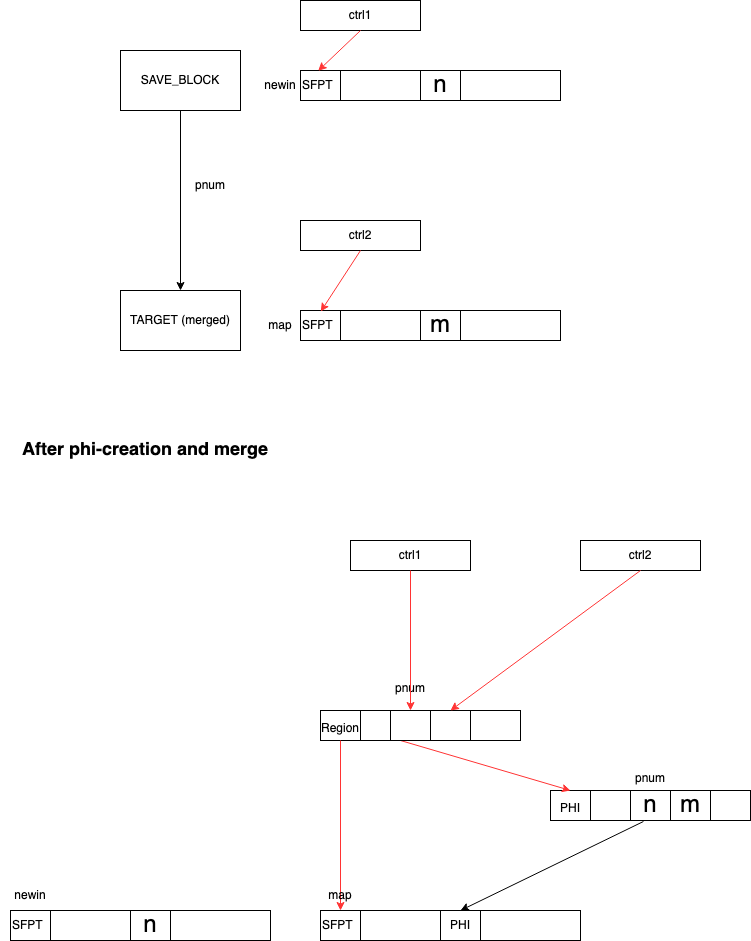
It is worth noting that it is not that we only merge the nodes appearing on SafePointNode newin and map. Only live variables on Locals and JVM Stack are on the SafePointNodes. C2 has purged dead variables. Live objects form a graph and a SafePointNode map is like the root-set in Garbage Collection. As long as we visit object references using DFS, we track all live objects.
Materialization is the process of converting a virtual object to a materialized object in the allocation state. A materialized object never converts back to virtual. By analogy with chemistry, it is an irreversible reaction.
Don’t confuse materialization with Rematerializaton, which takes place during deoptimization and resumes object identity on Java heap. Rematerialization only applies to those objects which have been eliminated by C2 Scalar replacement. In contrast, materialization may happen on any tracking object at compile-time.
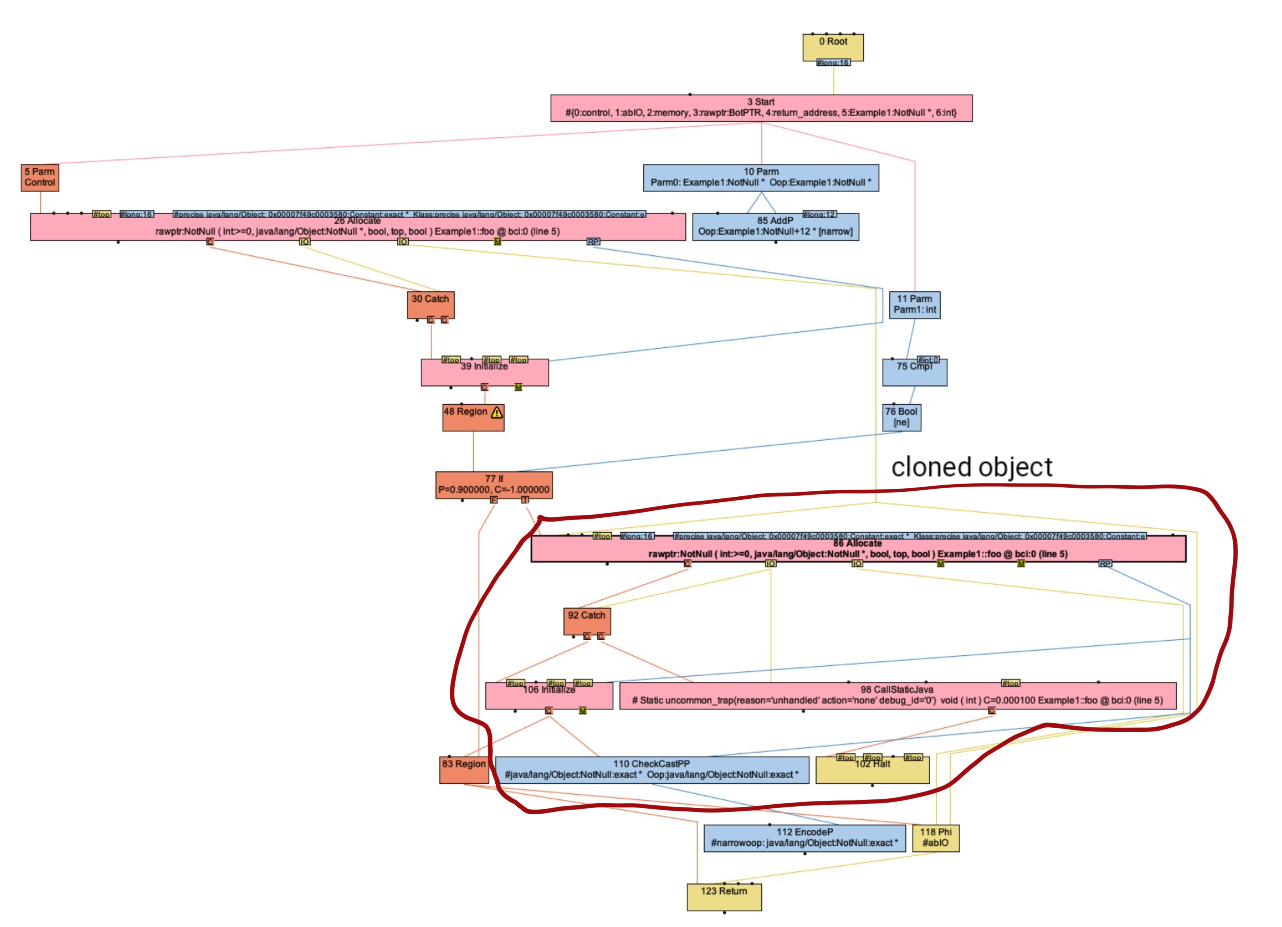
In our implementation, we clone the object and initialize its fields during materialization. All fields of a virtual object at current program point are tracked in the allocation state. In the following figure is the IR of Exmaple1.java after parser. The highlighted nodes are from materialization. They as a group clone the original object represented as 26 AllocateNode.
There are two types of materialization. The first is “escaping” materialization and it only occurs where the object is escaping. We intercept escaping points at bytecode put_field and invoke etc. The second type is “passive” materialization and it takes place only at a merging point. Passive materialization can further break down into 2 cases. We illustrate them in the following figure.
- At PHI-creation time, m is virtual in the current allocation state but has materialized in a prior predecessor. We can safely assume that all previous values are identical, or we would have created the PHINode before.
- n is a virtual object but has materialized in the allocation state of map.

When PEA materializes a virtual object, it emits a cluster of nodes. Unlike ordinary "floating" nodes, AllocateNode is a subclass of SafePointNode so it is dependent on JVMState. The position of passive materialization is arbitrary and sometimes the JVMState isn’t fit to emit an AllocateNode. To make thing more complicated, an AllocateNode yields an exception. We have seen that the Catch_All exception (or I_O in C2’s jargon) edge is mistakenly wired to the exception handler in current scope.
To ensure we can safely emit nodes of materialization, we copy debug edges and JVMState from the original AllocateNode for the cloned object. We also prefer deoptimization rather than the real exception. Those measures decouple the new AllocateNode from current context and make materialization always position-agnostic.
Here is the recipe of materialization:
- Create a new AllocateNode with the same type and arguments as the original AllocateNode.
- Clone JVMState of the original AllocateNode and assign it to the new AllocateNode.
- Copy debug edges from the original AllocateNode to the new AllocateNode.
- Create outputs for the new AllocateNode. Use deoptimization for the exception.
- Emit stores for the fields which have non-trivial values.
We manage to perform Stadler PEA in C2 parser. By leveraging CFG and RPO in bytecode, we piggyback both tracking of allocation state and materialization on C2 parsing phase. No additional pass is required.
Footnotes
-
Stadler, Lukas, Thomas Würthinger, and Hanspeter Mössenböck. "Partial escape analysis and scalar replacement for Java." Proceedings of Annual IEEE/ACM International Symposium on Code Generation and Optimization. 2014. ↩ ↩2
-
Liu, Xin, “RFC: Partial Escape Analysis in HotSpot C2", https://gist.github.com/navyxliu/62a510a5c6b0245164569745d758935b ↩