-
-
Save nikhilweee/24cae428f68c153afda495dc17ef43d6 to your computer and use it in GitHub Desktop.
| # This script is designed to convert bank statements from pdf to excel. | |
| # | |
| # It has been tweaked on HDFC Bank Credit Card statements, | |
| # but in theory you can use it on any PDF document. | |
| # | |
| # The script depends on camelot-py, | |
| # which can be installed using pip | |
| # | |
| # pip install "camelot-py[cv]" | |
| import os | |
| import argparse | |
| import camelot | |
| import pandas as pd | |
| from collections import defaultdict | |
| def extract_df(path, password=None): | |
| # The default values from pdfminer are M = 2.0, W = 0.1 and L = 0.5 | |
| laparams = {'char_margin': 2.0, 'word_margin': 0.2, 'line_margin': 1.0} | |
| # Extract all tables using the lattice algorithm | |
| lattice_tables = camelot.read_pdf(path, password=password, | |
| pages='all', flavor='lattice', line_scale=50, layout_kwargs=laparams) | |
| # Extract bounding boxes | |
| regions = defaultdict(list) | |
| for table in lattice_tables: | |
| bbox = [table._bbox[i] for i in [0, 3, 2, 1]] | |
| regions[table.page].append(bbox) | |
| df = pd.DataFrame() | |
| # Extract tables using the stream algorithm | |
| for page, boxes in regions.items(): | |
| areas = [','.join([str(int(x)) for x in box]) for box in boxes] | |
| stream_tables = camelot.read_pdf(path, password=password, pages=str(page), | |
| flavor='stream', table_areas=areas, row_tol=5, layout_kwargs=laparams) | |
| dataframes = [table.df for table in stream_tables] | |
| dataframes = pd.concat(dataframes) | |
| df = df.append(dataframes) | |
| return df | |
| def main(args): | |
| for file_name in os.listdir(args.in_dir): | |
| root, ext = os.path.splitext(file_name) | |
| if ext.lower() != '.pdf': | |
| continue | |
| pdf_path = os.path.join(args.in_dir, file_name) | |
| print(f'Processing: {pdf_path}') | |
| df = extract_df(pdf_path, args.password) | |
| excel_name = root + '.xlsx' | |
| excel_path = os.path.join(args.out_dir, excel_name) | |
| df.to_excel(excel_path) | |
| print(f'Processed : {excel_path}') | |
| if __name__ == '__main__': | |
| parser = argparse.ArgumentParser() | |
| parser.add_argument('--in-dir', type=str, required=True, help='directory to read statement PDFs from.') | |
| parser.add_argument('--out-dir', type=str, required=True, help='directory to store statement XLSX to.') | |
| parser.add_argument('--password', type=str, default=None, help='password for the statement PDF.') | |
| args = parser.parse_args() | |
| main(args) |
The code is not working, kindly check...
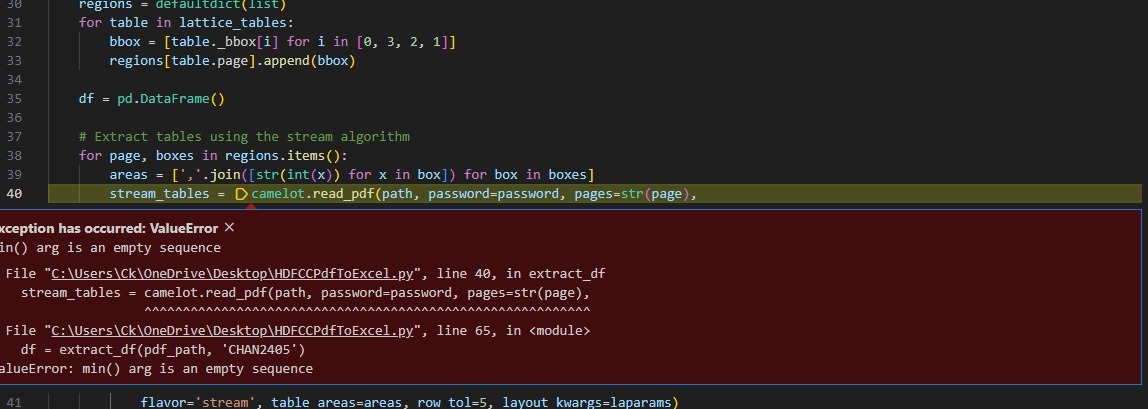
Looks like the method append has been removed from the pandas module a long time ago
$ python3 ~/scripts/statement-to-excel.py --in-dir . --out-dir .
Processing: ./2024-04.PDF
Traceback (most recent call last):
File "/Users/nowalekar/scripts/statement-to-excel.py", line 68, in <module>
main(args)
File "/Users/nowalekar/scripts/statement-to-excel.py", line 54, in main
df = extract_df(pdf_path, args.password)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/nowalekar/scripts/statement-to-excel.py", line 42, in extract_df
df = df.append(dataframes)
^^^^^^^^^
File "/Users/nowalekar/scripts/hdfc-cc-statement/lib/python3.12/site-packages/pandas/core/generic.py", line 6299, in __getattr__
return object.__getattribute__(self, name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'DataFrame' object has no attribute 'append'. Did you mean: '_append'?
Fix on line #42:
df = pd.concat([df, dataframes])
Hello Nikhil, I'm amateur user of mint linux. recently moved from Windows. I was looking for this code for long time as I wanted to move all my HDFC credit card transaction moved to moneymanager for tracking my expense. Tried running your code from the command promont however I got below error. Appreciate any guidance on the same
python3 /home/vivek/Downloads/HDFC_St/statement-to-excel.py --in-dir /home/vivek/Documents/Statements --out-dir /home/vivek/Documents/Excels --password V%$&*Ghe
/home/vivek/.local/lib/python3.10/site-packages/pypdf/_crypt_providers/_cryptography.py:32: CryptographyDeprecationWarning: ARC4 has been moved to cryptography.hazmat.decrepit.ciphers.algorithms.ARC4 and will be removed from cryptography.hazmat.primitives.ciphers.algorithms in 48.0.0.
from cryptography.hazmat.primitives.ciphers.algorithms import AES, ARC4
Processing: /home/vivek/Documents/Statements/April2025.PDF
Traceback (most recent call last):
File "/home/vivek/Downloads/HDFC_St/statement-to-excel.py", line 68, in
main(args)
File "/home/vivek/Downloads/HDFC_St/statement-to-excel.py", line 54, in main
df = extract_df(pdf_path, args.password)
File "/home/vivek/Downloads/HDFC_St/statement-to-excel.py", line 38, in extract_df
stream_tables = camelot.read_pdf(path, password=password, pages=str(page),
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/io.py", line 134, in read_pdf
tables = p.parse(
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/handlers.py", line 257, in parse
t = self._parse_page(
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/handlers.py", line 301, in _parse_page
tables = parser.extract_tables()
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/parsers/base.py", line 238, in extract_tables
cols, rows, v_s, h_s = self._generate_columns_and_rows(bbox, user_cols)
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/parsers/stream.py", line 135, in _generate_columns_and_rows
text_x_min, text_y_min, text_x_max, text_y_max = bbox_from_textlines(
TypeError: cannot unpack non-iterable NoneType object
Thanks a lot, @nikhilweee for this! Been using it from the last three years.
While running on a new system, got the following error:
Refer camelot-dev/camelot#339
What worked for me