embulkが動作しているEC2やローカルのマシンからRedshiftにロードする。
https://github.com/embulk/embulk-output-jdbc/tree/master/embulk-output-redshift でのソースコードを確認する限り、
- ローカルからS3にファイルを分割アップロードする。
- ローカルからRedshiftのマスターノードにCOPY文を発行する
- RedshiftクラスタがS3からファイルを指定したテーブルにロードする。 というフローになっている。

ここでは、ローカルからS3にアップロードするときには分割アップロードを実施することで アップロード速度が上がっているが、S3からRedshiftにロードするところは、通常のファイル転送が行われていると推測される。 そのため、Redshiftクラスタへのロードがボトルネックになる可能性がある。 (S3からRedshiftへのロードはAWS内で行われているためあくまでも推測であるが、 RedshiftはS3にあるクライアントサイド暗号を実施したファイルもロードできるため、ファイル内で並列化ロードは行われていないと推測される。 AES-CBCモードは前から順番にデータを暗号・復号する必要が有るため、並列処理は難しい) 当然、ひとつのテーブルに複数のCOPY文を走らせてもテーブルロックがかかるのであまり意味が無い。テーブルを分けてロードしてからRedshift上でETL処理をするのだろう。ただ、Redshiftはひとつのクラスタにつき9900個しか永続テーブルを持てないので、気をつける必要がある。 http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/r_CREATE_TABLE_usage.html
Redshiftで、S3から並列にCOPYを行うことはもちろん可能である。 ひとつは、S3のファイルを指定する所に*などを使って分割ファイルを使う方法。 もう一つは、S3上のファイルのパス一覧を記載したmanifestファイルを作成し、そのファイルを指定する方法である。 http://docs.aws.amazon.com/ja_jp/redshift/latest/dg/loading-data-files-using-manifest.html
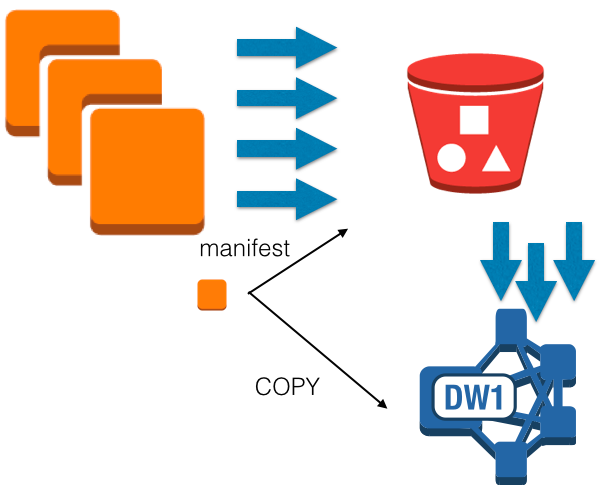
この場合、S3にアップロードが完了しても、ある程度ファイルが貯まらないとCOPYが走らないようになるため、 スループットは上がるがレイテンシは下がる。なので使い分けが必要と考える。