| Technique | Goal | Key Characteristic |
|---|---|---|
| Unit Testing | Verify individual functions/modules work correctly. | Pass/Fail is binary (10 + 5 = 15). |
| Integration Testing | Ensure components work together as expected (APIs, databases). | Checks for communication failures and data consistency. |
| Stress/Load Testing | Determine maximum performance under heavy usage. | Focuses on speed, stability, and resource limits. |
| AI Challenge | Failure Point | Example |
|---|---|---|
| Non-Deterministic Answers | The model can produce a great answer in 10 different ways. Binary comparison fails. | A summary might use different synonyms but convey the same meaning. |
| Subjectivity & Nuance | Cannot objectively grade qualities like tone, creativity, or effective use of jargon. | A simple script can't grade if the answer is "polite" or "professional." |
| Semantic Equivalence | Two different answers can be semantically identical (mean the same thing). | "The sun is hot" vs. "High temperature characterizes the star." |
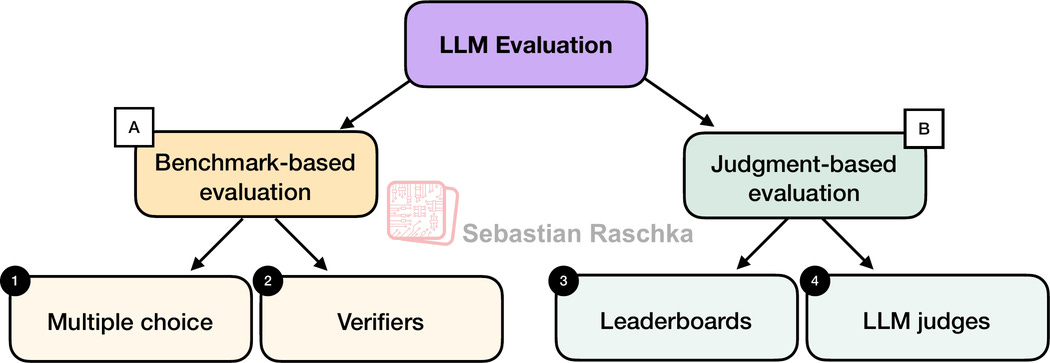
| Technique (Actor) | How it Works | Strength & Purpose |
|---|---|---|
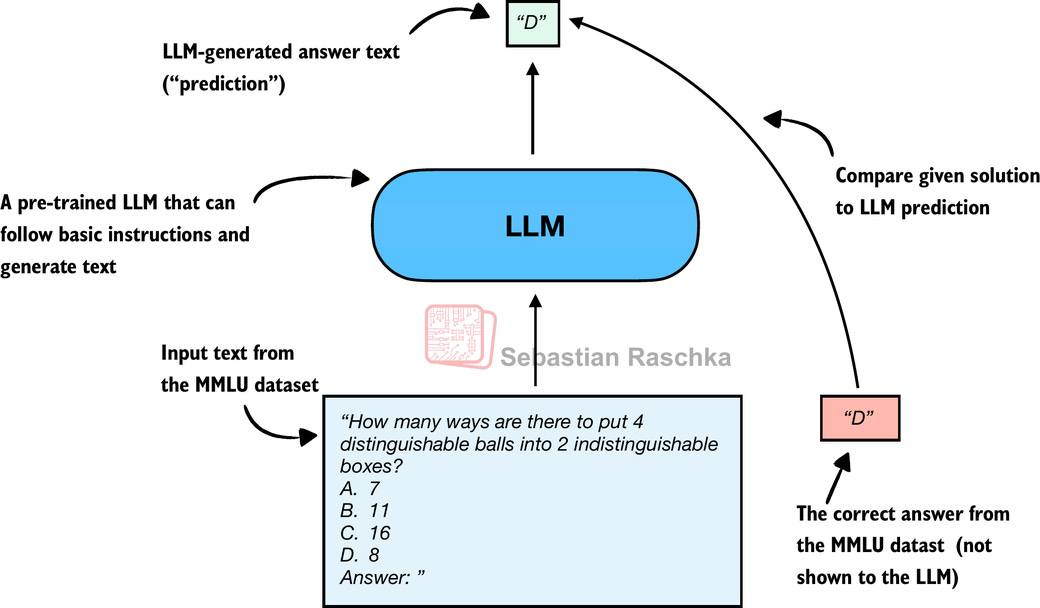
| MMLU - Massive Multitask Language Understanding (Multiple-Choice Benchmarks) | Forces the AI to spit out deterministic answers (A, B, C, or D) that a computer can compare to a known ground truth. | Fast, Scalable, Objective. Best for checking fundamental knowledge and reasoning abilities. |
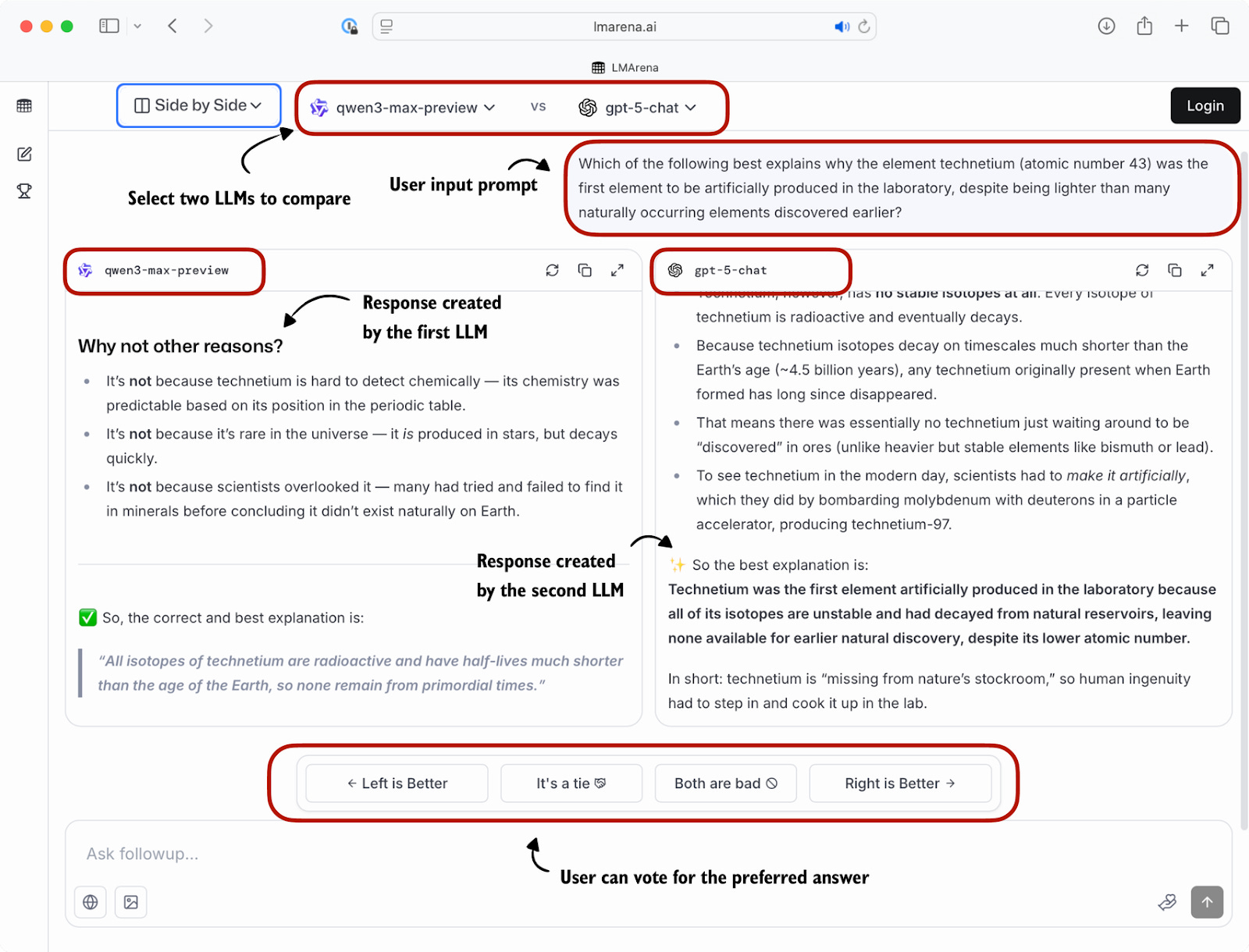
| Leaderboards (Human Judgment) | Humans (or crowdsourced judges) review model responses, often in a "pairwise comparison" format (which model is better: A or B?). | Highest Fidelity. Captures true human preference, nuance, and subjective quality (e.g., tone). |
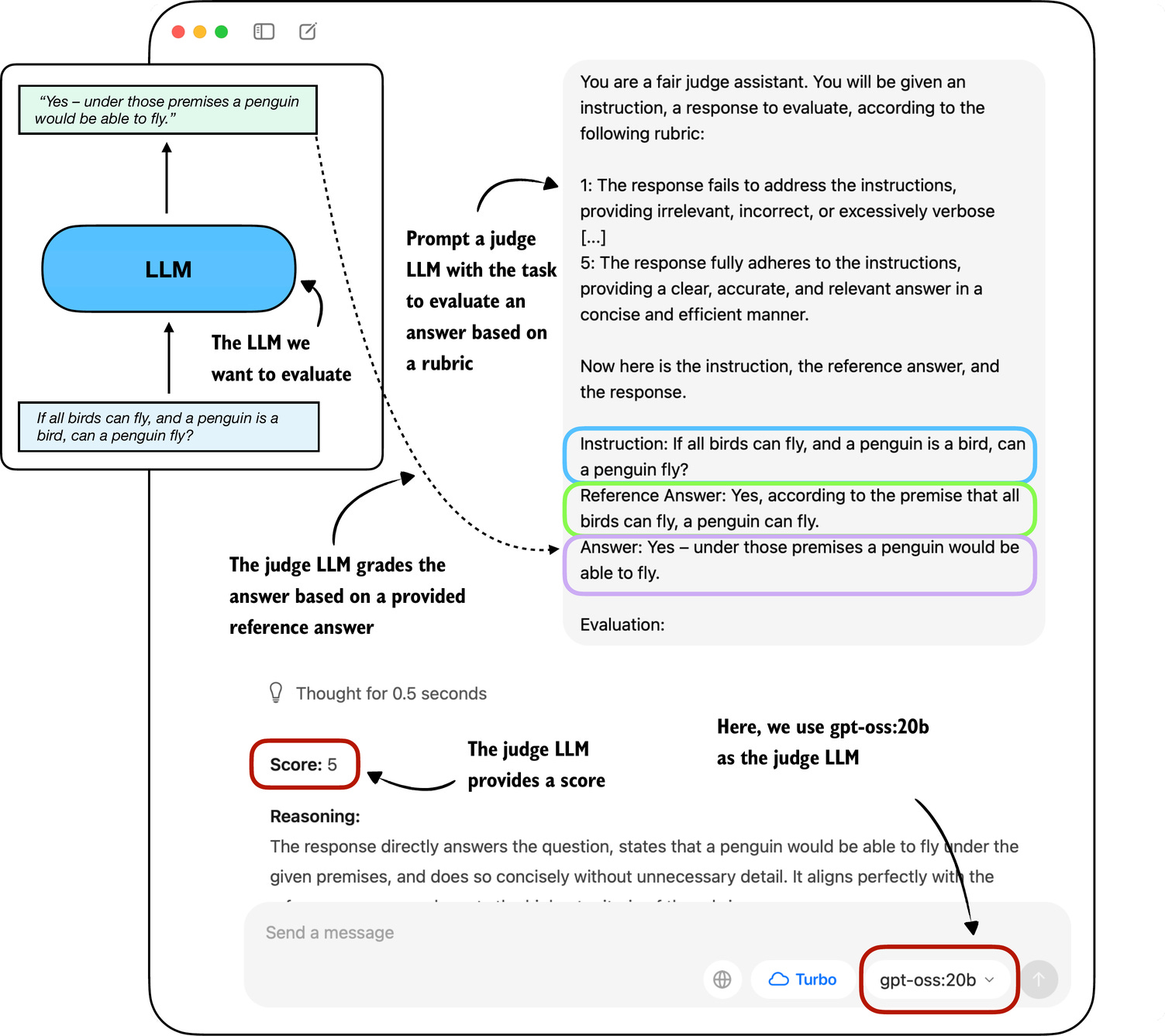
| LLM as a Judge | A powerful, stable LLM is given the output, the prompt, and a rubric, then asked to grade the tested model's response. | Fast, Affordable at Scale. Bridges the gap between cheap-but-basic automated metrics and slow-but-accurate human judges. |