- what
@ExceptionHandler 뒤에 작성한 예외가 발생했을 때, 그 예외를 잡아서 하나의 메서드에서 처리할 수 있게 해주는 어노테이션. - when
예외를 처리할 때, 각 예외가 발생하는 시점에서 try-catch로 처리하거나 밖으로 throw해서 처리해야한다. 이렇게 하는 경우, 중복되는 코드도 많아지고 관리해야하는 포인트도 많아지게 된다. 따라서 @ExceptionHandler 어노테이션을 이용해 특정 예외에 대한 처리를 공통으로 처리할 수 있도록 책임을 넘겨주고 싶을 때 사용한다. - why
- 특정 예외에 대한 처리를 한 곳에서 담당하도록 할 수 있다.
- 특정 예외에 대한 응답이 어떻게 수행되는지 파악하기 쉽다.
- 예외에 대한 관리가 용이하다. (특히 @ControllerAdvice와 함께 사용된다면 더욱 용이하다.)
- how
특정 컨트롤러에서 발생하는 예외만 잡기 위해서는 해당 컨트롤러 내부에 메서드로서 작성할 수도 있고, 전역적으로 모든 컨트롤러에서 발생하는 특정 예외에 대한 처리를 하기 위해서는 @ControllerAdvice 내부 메서드로서 작성할 수 있다.
사용 예시는 다음과 같다.
@ExceptionHandler(DataException.class)
public ResponseEntity<ErrorResponse> passDataExceptionError(DataException e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(new ErrorResponse(e.getMessage()));
}
-
what Controller를 보조하는 어노테이션으로 Controller에서 쓰이는 공통 기능들을 모듈화하여 전역으로 쓰기 위해 사용한다.
@ExceptionHandler,@InitBinder,@ModelAttribute세 가지의 어노테이션을 지원한다. -
when - how
- 전역 예외 처리기로서 사용할 수 있다.
@ControllerAdvice
public class GlobalControllerAdvice {
@ExceptionHandler(NullPointerException.class)
public void nullPointerException(NullPointerException e) {
}
}
애플리케이션 전역에서 발생한 특정한 예외를 @ControllerAdvice에서 잡아 처리할 수 있다. 예외처리에 대한 응답을 body로 전달하고 싶다면 @ResponseBody 어노테이션과 @ControllerAdvice를 합쳐 놓은 @RestControllerAdvice를 사용할 수 있다.
- @ModelAttribute를 모든 컨트롤러에서 사용한다면 @ControllerAdvice에 선언하여 전역적으로 사용할 수 있다.
@RestControllerAdvice
public class GlobalControllerAdvice {
@ModelAttribute
public User user() {
return new User("joanne");
}
}
- Validator, Formatter, Converter 등 여러가지 설정을 바인딩 할 수 있는 어노테이션인 @InitBinder를 ControllerAdvice에 작성하여 전역적으로 설정할 수 있다.
- why
공통으로 수행되는 로직을 @ControllerAdvice 내부에서 전역적으로 처리하면 관리에 용이하다. 예를 들어 애플리케이션의 모든 컨트롤러에서 NullPointerException이 발생할 가능성이 있을 때, 각 컨트롤러에서 @ExceptionHandler 어노테이션을 붙인 메서드를 각각 작성해서 처리하는 것보다, @ControllerAdvice에서 전역적으로 처리하면 응답을 확인하기도 수월하다. 또한 예외를 비즈니스 로직에 넣지 않고 분리할 수 있다.
- what
클라이언트의 HttpRequest에 대한 응답 데이터를 포함하는 클래스이다. HttpStatus, HttpHeaders, HttpBody를 포함하며 HttpEntity를 상속하여 구현되어있다. - when
상태코드, 헤더, 바디를 포함한 응답을 전달하기 위해 사용된다. ResponseEntity를 이용해 반환하게 되면 클라이언트에게는 JSON 또는 xml 형식으로 변환돼 반환된다. - why
View가 아닌 HTTP 정보만을 반환해야할 때 HttpStatus, Body, Header로 이루어진 완전한 HTTP 응답인 ResponseEntity를 사용할 수 있다. 여기서, 잠깐 의문이 생겼다.
ResponseEntity는 어떻게 객체를 JSON형태로 보내는 것일까?
따로 Converter를 지정하지 않으면 기본적으로 HttpMessageConverter의 구현체인 MappingJackson2HttpMessageConverter를 사용한다.

호출 스택은 우선AbstractJackson2HttpMessageConverter의writeInternal가MappingJackson2HttpMessageConverter를 호출한다. 다음은writeInternal코드의 일부인데,JsonGenerator,ObjectMapper등을 이용해 Json으로 변환하는 것을 확인할 수 있다.
@Override
protected void writeInternal(Object object, @Nullable Type type, HttpOutputMessage outputMessage)
throws IOException, HttpMessageNotWritableException {
MediaType contentType = outputMessage.getHeaders().getContentType();
JsonEncoding encoding = getJsonEncoding(contentType);
Class<?> clazz = (object instanceof MappingJacksonValue ?
((MappingJacksonValue) object).getValue().getClass() : object.getClass());
ObjectMapper objectMapper = selectObjectMapper(clazz, contentType);
Assert.state(objectMapper != null, "No ObjectMapper for " + clazz.getName());
OutputStream outputStream = StreamUtils.nonClosing(outputMessage.getBody());
try (JsonGenerator generator = objectMapper.getFactory().createGenerator(outputStream, encoding)) {
writePrefix(generator, object); //writePrefix는 MappingJackson2HttpMessageConverter에 구현되어있다.
- how
지하철의 노선을 생성한 뒤 제대로 생성된 경우 created라는 201 응답과 함께 생성된 line의 정보를 body에 담아 ResponseEntity로 응답하는 Controller의 다음 메서드를 통해 어떻게 사용하는지 확인할 수 있다.
@PostMapping
public ResponseEntity<LineResponse> createLine(@Valid @RequestBody LineRequest lineRequest) {
LineResponse line = lineService.saveLine(lineRequest);
return ResponseEntity.created(URI.create("/lines/" + line.getId())).body(line);
}
- https://woodcock.tistory.com/19
- https://docs.spring.io/spring-framework/docs/current/reference/html/web.html#mvc-ann-return-types
- https://wckhg89.github.io/archivers/understanding_jackson
- what
HTTP라는 기존 웹 표준을 그대로 사용하는 자원(Resource)과 행위, 표현으로 구성된 API이다. 자원은 URI로 표현되며 행위는 HTTP Method로서 표현할 수 있다. 이를 통해 REST API 메시지만 보고도 원하는 요청을 쉽게 이해할 수 있다. 추가적으로 URI로 지정한 리소스에 대한 동작을 통일되고 한정적인 인터페이스로 수행하며, 작업을 위한 상태 정보를 저장하거나 관리하지 않는다. 따라서 들어오는 요청만을 단순히 처리한다.
+URI를 이용해 명시된 자원에 접근하고 자원에 어떠한 조작을 할 지 HTTP method를 통해 나타내는 방법이다.
-
when
URI를 통해 명시된 자원에 접근하고 조작에 대한 요청을 보내고 싶을 때 REST를 사용할 수 있다. -
how
- 정보의 자원을 표현하는 URI를 이용한다. 특히 리소스명은 동사보다는 소문자이며 복수형 명사를 사용한다.
_는 사용하지 않고 가독성을 위해서는-를 사용한다. 또한 파일 확장자는 URI에 포함시키지 않는다.GET /members/1 - 자원에 대한 행위를 적절한 HTTP Method를 통해 표현한다.
DELETE /members/1적절한 HTTP Method는 다음과 같은 기준으로 선정할 수 있다.
POST - 리소스 생성
GET - 리소스 조회 및 자세한 정보 가져오기
PUT - 리소스 수정
DELETE - 리소스 삭제
- 적절한 HTTP 응답 상태 코드를 통해 응답한다.
상태 코드는 HTTP 상태 코드 - HTTP | MDN 에서 확인할 수 있다.
-
why
웹의 장점을 최대한 활용할 수 있는 아키텍처로서 고안되었다. 따라서 HTTP의 장점을 최대한 활용하면서 URI만으로 원하는 요청에 대한 표현을 할 수 있도록 하기 위해 사용한다.
- REST, Spring
-
what
트랜잭션이란 데이터베이스의 상태를 변화시키기 위해 수행하는 작업의 단위를 뜻한다. 스프링에서는 트랜잭션 처리를 지원하는데, @Transactional 어노테이션을 통해 이를 수행할 수 있다. -
when
다음과 같은 성질(ACID)을 만족시켜야하는 여러 가지 데이터베이스 작업이 수행되는 메서드에 대해 @Transactional 어노테이션을 달아 해결할 수 있다.
- 원자성 - 한 트랜잭션 내에서 실행한 작업은 하나로 간주하므로 모두 성공하거나, 모두 실패이다.
- 일관성 - 트랜잭션은 일관성 있는 데이터베이스 상태를 유지한다.
- 격리성 - 동시에 실행되는 트랜잭션들이 서로 영향을 미치지 않도록 서로 격리해야한다.
- 지속성 - 트랜잭션을 성공적으로 마치면 결과가 항상 저장되어야 한다.
-
how
클래스, 메서드 위에 @Transactional이 추가되면, 이 클래스나 메서드에 트랜잭션 기능이 적용된 프록시 객체가 생성된다. 이 프록시 객체는 @Transactional이 포함된 메소드가 호출될 경우 PlatformTransactionalManager를 사용하여 트랜잭션을 시작하고, 정상 여부에 따라 모두 커밋하거나 모두 롤백한다. @Transactional 어노테이션을 사용할 때, 읽기 작업만 수행할 경우readOnly=true라는 옵션을 달아 사용할 수 있다. 이 옵션을 달아주는 경우 현재 read-lock을 사용하고 있을 때 true를 반환해준다. 따라서 이 경우 읽기 전용 트랜잭션이 시작되었기 때문에 insert, update, delete와 같은 쓰기 작업이 진행되면 예외가 발생한다. -
why
Transactional 어노테이션을 달지 않은 채 여러 데이터베이스에 접근하는 메서드를 수행하는 경우, 특정 메서드가 제대로 완료되지 않았을 때에도 다른 변수나 메서드의 상태가 변경될 수 있다. 따라서 한 메서드를 하나의 처리 단위로서 실행시키길 원할 경우 사용해야한다.
스프링에서 컨트롤러를 지정해주기 위한 어노테이션에는 다음의 두 가지가 있다.
- what
주로 View를 반환하기 위해 사용하는 Controller에 다는 어노테이션이다.
- when
- 클라이언트는 URI 형식으로 웹 서비스에 요청을 보낸다.
- 요청은 HandlerMapping과 그 타입을 찾는 DispatcherServlet에 의해 Intercept된다.
- 요청은 Controller에 의해 처리되고 그 응답은 DispatcherServlet으로 리턴된 후, DispatcherServlet은 View로 dispatch된다.
전통적인 Spring MVC Work flow는 ModelAndView 객체가 컨트롤러에서 클라이언트로 전달된다. 여기에 @ResponseBody 어노테이션을 이용하면 View를 리턴하지 않고 컨트롤러에서 직접 데이터를 리턴할 수 있다.
- how
@Controller
public class UserController {
@GetMapping("/user")
public String userView(){
return "userView";
}
}
위와 같은 Controller에, @ResponseBody 어노테이션을 더해 데이터를 반환하는 것을 Spring 4.0 부터는 @RestController 어노테이션을 이용해 단순화하였다.
-
what
컨트롤러에서 Data를 반환해야 하는 경우 @ResponseBody 어노테이션이 포함된 @RestController를 사용해 객체 데이터를 반환할 수 있도록 도와준다. -
when
@ResponseBody가 포함되어있는 @RestController를 사용하면, 컨트롤러에서 바로 HttpResponse를 클라이언트에게 전달할 수 있다. RestController는 별도의 View를 제공하지 않는 형태로 서비스를 실행한다. 따라서 ResponseEntity를 이용하면 직접 결과 데이터와 HTTP 상태 코드를 전송할 수 있기에 더욱 세밀한 제어가 필요한 경우 함께 사용할 수 있다. -
how
@RestController
@RequestMapping("/lines")
public class LineController {
@PutMapping("/{id}")
public ResponseEntity<Void> updateLine(@PathVariable Long id, @RequestBody LineRequest lineUpdateRequest) {
lineService.updateLine(id, lineUpdateRequest);
return ResponseEntity.ok().build();
}
}
@Controller
@ResponseBody
public class Controller { }
@RestController
public class RestController { }- Spring @Controller와 @RestController 차이 - MangKyu’s Diary
- https://doublesprogramming.tistory.com/105
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/bind/annotation/RestController.html
- HTTP 프로토콜을 기반으로 사용자와 통신한다.
- HTTP는 상태가 없으므로 페이지 이동 시마다 서버와 연결해야한다.
- 상태유지, 장바구니 기능 구현 등이 까다롭다.
- Stateless 를 해결하는 2가지 방식이 세션과 쿠키이다.
- 세션: 서버에서 연결 정보를 관리한다.
- 쿠키: 클라이언트(브라우저)에서 연결 정보를 관리한다.
- what
쿠키는 사이트를 방문하고 이용할 때 브라우저에 저장되는 데이터인데, 웹 서버에서 생성되며, 사용자를 식별할 수 있는 key-value 쌍으로 이루어진 String 형태를 갖는다.
무상태 프로토콜인 HTTP 환경에서 상태를 유지하기 위한 기술이다. 데이터를 브라우저 측에 저장해두고 매 요청시 마다 서버로 쿠키를 전송한다. 따라서 페이지가 새로고침되거나 새로운 요청이 발생된다고 해도 클라이언트측의 브라우저에 데이터가 저장된 상태로 이동된다.
- when
- 최초 페이지에서 로그인하고 여러 페이지에 걸쳐 로그인 인증정보가 유지되어야하는 경우
- 쇼핑몰과 같은 사이트에서 장바구니에 담긴 아이템 정보들이 다른 페이지로 이동 시에도 유지되어야하는 경우
- 새로고침과 같은 경우에도 사용자의 상태가 변경되지 않아야하는 경우
- 이전 단계의 페이지의 정보들이 유지되어야하는 경우
- 하루 안보기 -> 지워지거나, 조작되거나, 가로채이더라도 큰 일은 없을 그런 수준의 정보를 브라우저에 정보를 저장할 때 사용.
- how
- Client가 Http Request를 서버에 보낸다.
- Server는 setCookie() 함수를 통해 쿠키를 설정하고, Http 헤더와 함께 쿠키를 클라이언트에게 전송한다.
- 클라이언트는 Http Request를 할 때 마다 쿠키를 설정한 뒤, 서버로는 Http Header에 담아서 보낸다.
서버가 쿠키를 생성할 때에는 setCookie() 함수를 사용하는데, "Name", "Value", "Expires"는 필수 표기 항목이다.
쿠키는 사용자 컴퓨터에 파일로 남겨지기 때문에 보안상에 문제가 발생할 수 있다.
- what
세션이란 서버가 해당 서버로 접근한 클라이언트를 식별하는 방법으로 서버는 접근한 클라이언트에게 response-header field인 set-cookie 값으로 클라이언트 식별자인 session-id를 응답한다.
일정 시간 동안 같은 사용자(브라우저)로부터 들어오는 일련의 요구를 하나의 상태로 보고 그 상태를 일정하게 유지시키는 기술이다. 여기서 일정 시간이란 방문자가 웹 서버에 접속해있는 상태를 하나의 단위로 보고 세션이라고 칭한다.
세션은 서버에 그 정보를 저장한다.
Client와 Web Server간 네트워크 연결이 지속적으로 유지된다. 처음 접속 시 클라이언트에게 유일한 아이디를 부여한다. 따라서 세션 아이디는 어떤 사용자의 세션인지를 식별하는 고유 ID로서의 역할을 한다.
-
when
세션은 서버에 저장되기 때문에 쿠키와는 다르게 정보가 노출되지 않는다. 따라서 서비스 관리자가 직접 관리해야할 중요한 정보들은 세션으로 서버 안에서 직접 다루어진다. -
how
<Session Id가 존재하지 않을 경우>
- Client가 Http Request를 서버에 보낸다.
- Session과 Session ID를 생성 및 저장한다.
- setCookie 함수를 통해 쿠키에 세션 아이디를 담아 응답으로 돌려준다.
<Session ID가 존재할 경우>
- client가 요청할 때 세션 아이디를 쿠키에 담아서 보낸다.
- Session Id를 저장소에서 조회한 뒤 세션을 찾는다.
- 필요한 정보를 응답에 담아 보낸다.
- https://en.wikipedia.org/wiki/HTTP_cookie
- 쿠키와 세션이란
- 무하프로젝트 :: HTTP Session 이란?
- 네트워크 HTTP 쿠키와 세션이란 ? :: 인생의 로그캣
- 컨트롤러에서 쿠키 생성, 제거
-
what
SimpleJdbcInsert는 테이블에 대한 쉬운 삽입 기능을 제공하는 재사용 가능한 객체이다. 기본 삽입문을 구성하는데 필요한 코드를 단순화하기 위한 메타 데이터 처리를 제공한다. -
when - why
실제 삽입은 Spring의 JdbcTemplate을 이용해 처리되지만, 그 과정에 있어 테이블 이름, 열 이름, 열 값이 포함된 맵을 제공하면 손쉽게 Insert문을 사용하고, Key를 받아올 수 있기에 사용한다. -
how
final SimpleJdbcInsert simpleJdbcInsert = new SimpleJdbcInsert(jdbcTemplate)
.withTableName("테이블명")
.usingGeneratedKeyColumns("키 컬럼");
Map<String, Object> params = new HashMap<>(담을 값의 개수);
params.put("컬럼명", 넣을 값);
Long id = simpleJdbcInsert.executeAndReturnKey(params).longValue();
-
what
유틸 클래스로서 DAO 구현을 위해 사용할 수 있으며 모든 데이터 액세스 기술에 유용하게 사용할 수 있다. -
when
dao에서 리턴값으로 객체를 넘겨주는 경우에 특히 사용할 수 있다. DataAccessUtils의 메서드명으로 리턴에 어떤 값이 들어갈 지 자체적으로 명시되기 때문에 유용하게 사용할 수 있다. 하지만 유틸 클래스 자체를 지양하거나 객체의 존재 여부를 dao에서 예외를 던지는 것이 아니라 우선 Service 레이어로 넘긴 뒤, 서비스에서 예외 처리를 담당하도록 하기 위해서는 Dataaccessutils 를 사용하지 않고 Optional 등을 이용하는 방법이 있다. -
why
Optional을 넘기는 경우 그 객체가 1개인지, 2개인지, null인지 명시하기 어렵다. 따라서 해당 유틸 클래스를 사용하면nullableSingleResult,intResult등과 같이 메서드명으로 어떤 객체를 넘기는 지 전달할 수 있고, 또한 메서드 자체에서 메서드명에 해당하지 않는 예외가 발생한다면 내부적으로 예외를 발생시키기 때문에 예외가 발생하지 않는 제대로 된 값만 넘길 수 있다는 장점이 있다. -
how
public Car findOneById(Long id){
...
return DataAccessUtils.requiredSingleResult(jdbcTemplate.queryForList(sql, id));
위는 requiredSingleResult의 용례에 관한 예제이며 DataAccessUtils에서 제공하는 다양한 내부 메서드는 참고 자료에서 확인할 수 있다.
- what
서로 다른 시스템들 사이에서 데이터를 주고 받기 위한 가장 기초적인 프로토콜
80번 포트를 사용하고 있다.
상태를 가지고 있지 않은 Stateless 프로토콜이며, Method, Path, Version, Headers, Body로 구성된다.
암호화되지 않은 평문 데이터를 전송하는 프로토콜이다. 단방향성 - 클라이언트가 서버로 요청을 보내고 이에 대한 응답을 받는 단방향적 통신
비연결성 - 연결이 계속 유지되지 않고 요청에 대한 응답이 끝나면 연결을 끊음.
무상태성 - 클라이언트가 서버와 연결된 상태가 아니기 때문에 상태를 가지지 않는다. (보완을 위해 쿠키, 세션 등을 사용한다.)
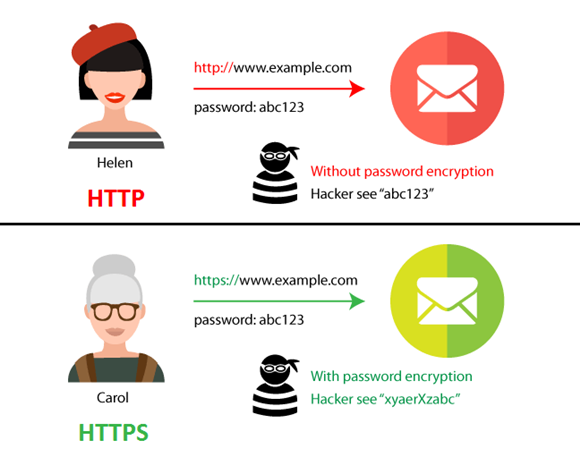
- what
HTTP + Secure의 약자이다. 일반 HTTP 프로토콜의 문제점은 서버에서 브라우저로 전송되는 정보가 암호화되지 않는다는 것이었다. HTTPS 프로토콜은 SSL을 사용함으로써 이 문제를 해결했다.
443번 포트를 사용한다.
네트워크 상에서 중간에 제 3자가 정보를 볼 수 없도록 공개키 암호화를 지원하고 있다.
개인정보와 같은 민감한 데이터를 주고 받을 때엔 HTTPS, 단순 정보 조회등을 처리 시에는 HTTP.
Nginx와 아파치는 모두 웹 서버로서 사용된다.
-
what 아파치는 Apache 2.0 오픈 소스 하에서 배포된 웹 서버이다. 여타 다른 웹 서버들처럼 HTML, PHP, 미디어 파일 등의 웹 컨텐트를 호스팅하고, 방문한 사용자들에게 해당 컨텐츠를 제공한다.
-
how
요청 하나 당 프로세스가 처리하는 구조이다. 자세히 말하자면 클라이언트에서 요청을 받으면 MPM(Multi Processing Module)이라는 방식으로 처리를 하는데, 대표적으로는 Prefork와 Worker 방식이 있다. Apache에 WAS로 톰캣을 연동하는 경우라면 Apache 여러 방식을 아파치 자체에서 제공해주기 때문에 다양하고 효율적으로 연동할 수 있다.
-
what
보안과 속도를 최적화시키려는 노력에서 탄생한 웹 서버로서 사용이 매우 간단하고 규모가 작은 서비스이면서 정적 데이터 처리가 많은 서비스에 적합하다.
프로그램의 흐름이 이벤트에 의해 결정되는 Event-Driven 방식의 웹 서버이다. -
how 비동기 Event-Driven 기반 구조이므로 CPU와 관계 없이 모든 IO들을 이벤트 리스너로 미루기 때문에 흐름이 끊기지 않고 응답이 빠르게 진행되어 1개의 프로세스로 더 많은 작업을 할 수 있다.
- JDBC, Network/Infra
-
what
Facade Pattern이란 어떠한 서브 시스템의 일련의 인터페이스에 대한 통합된 인터페이스를 제공하는 방법이다. 간단한 예를 들자면, 퍼사드는 건물의 정면을 의미하는데, 하위 시스템들에 대해 건물의 입구를 제공하여 하위 시스템들로 접근하기 위해 건물의 입구를 통과하도록 설계하는 것과 같다. -
when
 위 처럼, 여러 클라이언트가 다양한 서비스들을 한꺼번에 필요로 하는 경우가 있다고 가정하자. 이 때, 우리는 각각의 클라이언트들의 요청에 알맞은 서비스를 매핑해주는 것이 아니라, 각 서비스들의 상위 관문인 퍼사드 인터페이스를 통해 요청하도록 하고, 자세한 비즈니스 로직은 퍼사드를 통해 구현되도록 다음과 같이 변경할 수 있다.
위 처럼, 여러 클라이언트가 다양한 서비스들을 한꺼번에 필요로 하는 경우가 있다고 가정하자. 이 때, 우리는 각각의 클라이언트들의 요청에 알맞은 서비스를 매핑해주는 것이 아니라, 각 서비스들의 상위 관문인 퍼사드 인터페이스를 통해 요청하도록 하고, 자세한 비즈니스 로직은 퍼사드를 통해 구현되도록 다음과 같이 변경할 수 있다.

요약하자면, 퍼사드는 클라이언트의 요청을 적절한 하위 클래스의 시스템에 위임하는 역할, 하위 시스템 클래스는 하위 시스템의 기능을 구현하여 적절한 비즈니스 로직을 취하도록 하는 역할, 그리고 클라이언트는 어떠한 작업을 수행하기 위해 퍼사드에게 요청하는 역할을 수행한다.
- 학습로그에 퍼사드를 포함한 이유?
이번 미션에서는 100% 퍼사드 패턴을 만족한 구현 방식으로 서비스 - 다오 구조를 구현한 것은 아니었다. 단순히 서비스와 dao가 1:1 매핑이 되도록, 서비스가 다른 서비스를 참조하지 않도록 구성하기 위해 서비스들의 상위 역할을 하는 클래스를 분리하고, 해당 상위 클래스를 서비스들의 조합으로 나타냄으로서 구현하였다.
하지만 이러한 방법에 유사한 패턴으로서 퍼사드가 있다는 것을 알게 되었고, 이를 학습로그에 작성하게 되었다.
- how
// order controller
public class OrderFulfillmentController {
OrderServiceFacade facade;
boolean orderFulfilled=false;
public void orderProduct(int productId) {
orderFulfilled=facade.placeOrder(productId);
System.out.println("OrderFulfillmentController: Order fulfillment completed. ");
}
}
// order facade
public interface OrderServiceFacade {
boolean placeOrder(int productId);
}
public class OrderServiceFacadeImpl implements OrderServiceFacade{
public boolean placeOrder(int pId){
boolean orderFulfilled=false;
Product product=new Product();
product.productId=pId;
if(InventoryService.isAvailable(product))
{
System.out.println("Product with ID: "+ product.productId+" is available.");
boolean paymentConfirmed= PaymentService.makePayment();
if(paymentConfirmed){
System.out.println("Payment confirmed...");
ShippingService.shipProduct(product);
System.out.println("Product shipped...");
orderFulfilled=true;
}
}
return orderFulfilled;
}
}-
what
layered architecture란 유사한 관심사들을 레이어로 구분하여 추상화한 뒤 수직적으로 배열하는 아키텍처이다. 주로 3계층 구조로 나뉘어 구분되는데, 3계층 구조에는 Data, Application, Presentation으로 구분된다.- Presentation Layer: 응용 프로그램의 최상위 계층에 위치하며 다른 층의 데이터와 소통한다. 사용자 인터페이스를 제공한다.
- Application Layer: 비즈니스 로직 또는 트랜잭션 계층으로 불린다. 클라이언트의 요청에 대해 비즈니스 로직을 수행하는 서버처럼 행동하며, Data Layer에 대해서는 클라이언트처럼 행동하는 Middleware 역할을 한다.
- Data Layer: 데이터베이스와의 상호작용을 수행하는 것을 관리하는 프로그램을 포함하는 계층이다.
-
when
시스템을 레이어로 나누면 시스템 전체를 수정하지 않고도 특정 레이어를 수정 및 개선할 수 있기에 사용한다.- 단방향 의존성: 각 레이어는 하위 인접한 레이어에게만 의존
- 관심사의 분리: 각 레이어는 주어진 고유한 역할만을 수행
- 코드의 확장성과 재사용성: 각 레이어가 서로 독립적이며 역할이 분명하기에 서로에게 끼치는 영향을 최소화하여 수정 가능 / 독립 레이어이므로 하나의 서비스 레이어는 여러개의 프레젠테이션 레이어가 재사용할 수 있다.
- 코드의 가독성
-
more
-
Presentation Layer: Web Layer이자 UI Layer이다. 화면 조작 또는 사용자의 입력을 처리하기 위한 관심사를 모아 놓은 계층이라고 볼 수 있다. 즉, 최종 사용자에게 UI를 제공하거나 클라이언트로 응답을 다시 보내는 역할을 담당하는 모든 클래스이다. API의 엔드포인트를 정의하고 전송된 요청들을 읽어 들이는 로직을 포함한다.
-
Application Layer: 일반적으로 다양한 도메인과 비즈니스 로직을 의미있는 수준으로 묶어 제공하는 역할을 수행하는 계층이다. 핵심 비즈니스 로직을 직접 구현하기보다는 도메인에게 적절한 책임을 분배하며 얕은 비즈니스 로직을 구성한다. Application Layer에서는 도메인 모델 및 Presentation Layer 사이에서 도메인 기능을 응용하는 로직을 담당하며, 트랜잭션 및 도메인 모델의 기능간의 순서만을 보장해야한다. 또한 도메인 모델을 직접적으로 반환하지 않고, DTO등을 반환하도록 함으로서 도메인 모델을 캡슐화하는 역할을 수행할 수 있다.
-
Data Layer: DataSource를 직접 활용하며 DB에서 데이터 저장, 수정 등의 DB와 관련된 로직을 수행하는 계층이다.
-
-
why
Layered Architecture에 대해 학습해본 이유는, 이번에 Service가 Service를 가져도 되는가?라는 의문에 대해 리뷰어이신 데이브께서 레이어드 아키텍쳐에 경우에는 서비스가 서비스를 가지는 경우도 존재한다고 하셔서 학습의 동기가 되었다. 레이어드 아키텍쳐는 앞서 말했듯 시스템을 관심사로 구분하여 수직적으로 쌓았기 때문에 여러개의 서비스가 존재할 때, 그리고 그 서비스들이 수직적 관계(말이 이상한데.. 단방향 관계가 확실한 경우를 말하고 싶었다.)를 갖는 경우에는 서비스가 서비스를 가져도 된다는 의견을 확립할 수 있었다.
-
what
TDD란 테스트가 주도하는 개발을 말한다. 즉, 테스트 코드를 먼저 작성하는 것에서부터 개발을 시작하는 것을 이야기한다.

위 이미지는 TDD를 잘 나타내주는
red-green refactor이다. 설명은 다음과 같다.Red: 항상 실패하는 테스트를 먼저 작성한다. Green: 테스트가 통과하는 프로덕션 코드를 작성한다. Refactor: 테스트가 통과하면 프로덕션 코드를 리팩토링한다.-
추상적인 레벨에서의 TDD의 핵심 개념
결정과 피드백 사이의 갭에 대한 인식, 더 나아가 결정과 피드백 사이의 갭을 조절하기 위한 테크닉
여기서의 결정이란
이 방법으로 코드를 짜야지를 말하고, 피드백이란성공/실패(에러)라는 응답을 받는 것을 말한다. 따라서 이 둘 사이의 갭이 커질수록 그 갭을 극복하는 것이 어렵다. 즉, 테스트 코드를 실행한 결과를 통해 빠른 피드백을 받을 수 있고, 이를 통해 갭을 줄일 수 있다.
-
-
when
- 불확실성이 높은 경우
- 빠른 피드백이 필요한 경우
- 요구사항이 자주 변경되는 경우 등등등..
-
why
불확실성이 높을 때
피드백과협력이 중요하다. 따라서 TDD 또한 피드백과 협력을 증진시키는 과정이기 때문에 불확실성이 높은 프로그래밍 과정에 있어서 도움이 된다. 따라서 TDD를 실천해야한다!
-
what
인수 테스트란 사용자의 스토리에 맞추어 테스트를 작성하는 것을 말한다. 각 기능이 유기적으로 연결되었는가에 대한 테스트보다는, 사용자의 시나리오가 정상적으로 동작하는가를 테스트 한다.
여담으로 통합 테스트와 인수 테스트의 차이는 우선 목적이 다르다. 통합 테스트는 단위 테스트가 끝난 모듈을 통합하느 과정에서 발생할 수 있는 예외 상황을 테스트하는 것이고, 인수 테스트는 사용자의 시나리오대로 프로그램이 잘 동작하는지를 테스트하는 것이다. 인수 테스트를 수행할 때 시나리오를 바탕으로 수행하다보니 통합 모듈이 사용되게 되고, 그러므로 인해 통합 테스트와 유사하다고 생각되는 경우가 많다. 아무튼 결론은 둘은 목적은 다르지만 겹치는 경우도 많다!
-
when
사용자의 시나리오를 테스트할 때 사용한다.
-
why
빠른 피드백을 받을 수 있고, 기존 기능을 망가뜨리지 않고 새 기능을 확장해나갈 수 있다. 또한 작업의 시작과 끝이 테스트에서부터 명확하기에 구현하는 데에 도움이 된다.
-
background
- DTO란? 계층 간 데이터 교환을 위한 객체이다. DTO는 단순히 전달만을 위한 객체이므로 비즈니스 로직을 내부에 갖지 않는다.
- MVC 패턴이란? 애플리케이션을 개발할 때 그 구성 요소를 Model, View 및 Controller 등 세 가지 역할로 구분하는 디자인 패턴이다.
비즈니스 처리 로직(모델)과 view영역은 서로의 존재를 인지하지 못하고, Controller가 중간에서 Model과 View의 소통을 담당한다. 이 때, 모델에서 넘겨받은 데이터를 뷰에게 전달하기 위해 DTO를 사용할 수 있다.
-
how
DTO 사용 예시
// Station 도메인 public class Station { private final long id; //외부에 노출되면 안되는 정보 private final String name; public Station(long id, String name) { this.id = id; this.name = name; } } // StationDto public class StationDto { private final String name; public StationDto(String name) { this.name = name; } }
-
DTO는 어느 범위까지 사용해야할까?
DTO로의 변환은 컨트롤러에서 하는게 맞지 않을까요?,서비스에 DTO가 들어가는 것이 맞을까요, 도메인으로 변환한 뒤 들어가는 것이 맞을까요?,DTO가 dao까지 들어가고 있어요😱등의 의견이 이 질문에 대해 생각해보게 된 계기가 되었다.별다른 이유 없이 나는 DTO가 dao까지 들어가는 것은 물론 안되는 것이 맞으며, 컨트롤러로 가기 전 Service에서 비즈니스 로직 수행 후 DTO로 변환한 뒤 전달해주어야한다는 생각을 갖고 있었다. 그리고, 컨트롤러에서 서비스를 호출할 때에도 DTO를 전달하는 것은 별다른 문제가 되지 않는다고 생각했다.

우선, dao에 dto가 들어가면 안된다는 생각을 갖게 해줬던 건 위 이미지이다. 위 이미지는 Layered Architecture를 설명할 때 구조를 나타내는 이미지로서 스프링 부트와 aws로 혼자 구현하는 웹 서비스라는 책에서 처음 접하게 되었다. 이 이미지에서도 볼 수 있듯이 dto는 Web Layer와 Service Layer간의 데이터 전송을 위해 사용되고, Service와 DAO는 도메인으로 소통한다. Repository Layer에 dto가 들어가면 안되는 이유로는, repository layer에서는 엔티티의 영속성을 관장하는 역할이기 때문에 도메인의 dto 변환 및 dto에서 도메인의 변환을 repository layer에서 책임지게 하는 것을 지양하자는 의견이 존재한다는 것도 하나의 이유가 된다.
그럼 다음으로, DTO의 변환은 그럼 서비스에서 하는 것이 맞을까?
DTO 변환은 서비스에서 하는 것이 맞다는 것을 가정하고 이야기해보자.한줄 요약: 서비스는 도메인을 보호하는 역할을 가지기 때문에, 컨트롤러로 결과를 전달할 때에도 한번 캡슐화한 뒤(dto로 변환) 전달해야한다.
우선, Service Layer는 어플리케이션의 경계를 정의하고 비즈니스 로직 등 도메인을 캡슐화하는 역할이라고
마틴 파울러가 말했다. 즉, Service Layer는 도메인의 캡슐화를 수행하는 책임을 가지기 때문에, Controller로 결과를 전달할 때에도 DTO로 변환해서 전달하는 것이 도메인을 더 보호하는 결과라는 생각이 들었다. 또한 도메인이 컨트롤러까지 넘어가게 된다면, 도메인의 변경이 있을 시 컨트롤러까지 그 영향이 미치기 때문에 유지보수에도 좋지 않다. 위의 이유들로 보자면 DTO의 변환은 서비스 레이어에서 수행하는 것이 맞는 것 같다.그렇다면, 컨트롤러에서 DTO로의 변환은 수행하면 안되는 것인가?
이번에는 dto 변환을 컨트롤러에서 하는 것이 맞다고 가정하고 이야기해보자.먼저 컨트롤러에서 서비스로의 dto 진입에 대해서부터 생각해보자.
한줄 요약: 서비스로 dto의 진입을 허용하지 않게 되면, 컨트롤러에서 dto 변환을 수행해야한다.
앞선 layered architecture에서는 layer별로 역할이 정해져 있기 때문에, 각 역할이 제대로 구분되어 있다면 Presentation Layer가 여러 개의 Application Layer를 이용할 수 있다고 되어 있다. 즉, 레이어드 아키텍쳐로 구성한다는 것 자체가 각 레이어의 책임을 명확히 분리한다는 의미이다. 그렇다면, DTO가 service로 들어가게 될 시 Service는 해당 dto를 사용하는 컨트롤러에 종속적이게 된다. 그리고, dto가 한번 서비스까지 들어가게 되면 dao까지 진입하게 되는 결과를 낳을 수 있다. 그럼, 이에 대한 결론을 내리면 서비스는 dto를 모른 채 도메인만을 가지고 설계하는 것이 맞고, 서비스는 dto를 모르기 때문에 컨트롤러로 결과를 전달할 때에도 도메인으로 전달해야한다. 즉, 도메인을 dto로 변환하는 작업 또한 컨트롤러에서 수행해야하는 것이다.
-
Conclusion
결론을 내려보자면, 각 레이어의 책임이 어떻게 구분하는지, 그리고 Entity가 어느 계층까지 노출되어도 가능하냐 등의 종합적인 이유를 따져본 뒤 어느 계층에서 dto 변환을 수행해야할 지 결정해야한다. 하지만 나라면,컨트롤러로 도메인이 노출되는 경우 변경의 범위가 크다.는 이유가 가장 와닿았기 때문에 Service에서 컨트롤러로 데이터를 전달할 때 dto로 변환한 뒤 전달을 수행할 것 같다.
- Spring, Java
-
what
반환되어야하는 상태 코드 및 이유를 예외 클래스 또는 메서드에 표시하는 용도로 사용되는 어노테이션이다.
핸들러 메소드가 호출될 때 상태 코드가 HTTP response에 적용되고 ResponseEntity 또는 redirect와 같은 다른 수단으로 설정된 상태 정보를 대체한다. -
주의할 점
Warning: when using this annotation on an exception class, or when setting the reason attribute of this annotation, the HttpServletResponse.sendError method will be used. With HttpServletResponse.sendError, the response is considered complete and should not be written to any further. Furthermore, the Servlet container will typically write an HTML error page therefore making the use of a reason unsuitable for REST APIs. For such cases it is preferable to use a org.springframework.http.ResponseEntity as a return type and avoid the use of @ResponseStatus altogether.
예외 코드 및 이유를 반환할 때 사용할 수 있지만, 이
@ResponseStatus를 사용할 경우 HttpServletResponse.sendError() 메서드가 사용된다. 이 메서드가 사용되면 응답이 완료된 것으로 간주되며 서블릿 컨테이너는 일반적으로 HTML 오류 페이지를 작성하므로 REST API의 예외 응답에는 적절하지 않다. 따라서 REST API의 예외 응답으로는 org.springframework.http.ResponseEntity를 반환 유형으로 사용하고 @ResponseStatus를 사용하지 않는 것이 좋다.만약 @ResponseStatus를 이용해 상태 코드를 지정하고, 응답으로는 예외 객체를 뱉는다면
@RestControllerAdvice와 함께 다음과 같이 사용은 할 수 있되, ResponseEntity에 상태 코드를 싣어서 보내는 것을 권장한다.@ResponseStatus(HttpStatus.BAD_REQUEST) @ExceptionHandler(NoExistException.class) public ErrorResponse handleNotFoundException(NoExistException e) { return new ErrorResponse(e.getMessage()); } // 권장 @ExceptionHandler(NoExistException.class) public ResponseEntity<ErrorResponse> handleNotFoundException(NoExistException e) { return ResponseEntity.badRequest().body(new ErrorResponse(e.getMessage())); }
-
what
Interceptor는 특정 핸들러 그룹에 대해 기존 또는 사용자 정의 인터셉터를 등록하여 각 핸들러 구현을 수정할 필요 없이 공통 전처리 동작을 추가할 수 있도록 한다. 이 매커니즘은 예를 들어 권한 확인과 같은 일반적인 핸들러 동작과 같은 전처리 측면의 넓은 분야에 사용될 수 있다. 주 목적은 반복적인 핸들러 코드를 제거하는 것이다.
DispatcherServlet이 Controller를 호출하기 전, 후에 끼어들어 스프링 컨텍스트 내부에서 컨트롤러에 관한 요청과 응답에 관여한다.
-
how
- preHandler() - Controller 실행 전
- postHandler() - Controller 실행 후 view Rendering 실행 전
- afterCompletion() - view Rendering 이후
각 메서드의 반환값이 true이면 다음 체인이 실행되지만, false이면 중단하고 남은 인터셉터와 컨트롤러가 실행되지 않는다.
-
what
Strategy interface for resolving method parameters into argument values in the context of a given request.
컨트롤러에서 파라미터를 바인딩해주는 역할을 수행한다. 예를 들어 특정 클래스나 특정 어노테이션 등의 요청 파라미터를 수정해야한다거나 또는 클래스의 파라미터를 조작 혹은 공통적으로 써야하는 파라미터들을 바인딩해주는 역할을 한다.
-
how
간단한 로그인 유저라는 객체를 만든 뒤, 컨트롤러에서 들어오는 요청에 대해 name: "조앤", age: 24를 갖는 로그인 유저를 바인딩하도록 하는 ArgumentResolver를 만들어보자.// 1. loginUser 객체 생성 public class LoginUser { private final String username; private final int age; // getter 및 생성자 생략 } //2. CustomHandlerArgumentResolver 등록 // supportsParameter는 바인딩할 클래스를 지정하고, // resolveArgument는 바인딩할 객체를 조작하는 로직을 담는다. public class CustomHandlerMethodArgumentResolver implements HandlerMethodArgumentResolver { @Override public boolean supportsParameter(MethodParameter parameter) { return LoginUser.class.isAssignableFrom(parameter.getParameterType()); } @Override public LoginUser resolveArgument(MethodParameter parameter, ModelAndViewContainer mavContainer, NativeWebRequest webRequest, WebDataBinderFactory binderFactory) throws Exception { return new LoginUser("조앤", 24); } } // 3. Configuration에 우리가 등록한 CustomHandlerMethodArgumentResolver를 등록해준다. @Configuration public class WebConfig extends WebMvcConfigurerAdapter { @Override public void addArgumentResolvers(List<HandlerMethodArgumentResolver> argumentResolvers) { argumentResolvers.add(new CustomHandlerMethodArgumentResolver()); } }
다음과 같이 설정하면, Controller에서 LoginUser를 받을 시 resolver에서 바인딩 해 둔 조앤, 24살의 로그인 유저가 반환된다.
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/method/support/HandlerMethodArgumentResolver.html
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/web/servlet/HandlerInterceptor.html
-
what
Json Web Token이라 불리는 JWT는 모바일이나 웹의 사용자 인증을 위해 사용하는 암호화된 토큰을 의미한다.
JWT 토큰은 총 세 부분으로 나뉘는 형태를 갖는다. 첫번째 **.**까지는 Header를 의미한다. 헤더는 토큰을 어떻게 해석해야하는 지를 명시한다. 두번째 **.**까지는 payload로서, 실제 토큰의 바디이며 토큰에 포함할 내용을 담는다. 마지막은 Signature로서 header-payload 위변조 검증을 위한 부분이다. -
use
JWT가 다른 토큰과 가장 다른 부분은 토큰 자체가 데이터를 갖고 있다는 점.
토큰을 받아서 서명으로 유효한 토큰인지 검증한 뒤, 유효하다고 판단하면 payload를 디코딩해서 토큰에 담긴 데이터를 열어본다. payload에는 만료 시간등이 담겨있으므로 토큰이 사용 가능한지 검사를 하고 이상이 없을 시 바로 사용한다. 토큰의 사용자 아이디 등이 페이로드에 담겨있다면 db나 캐시를 조회할 필요 없이 애플리케이션 자체에서 사용자를 확인/조회할 수 있다. 하지만 다른 토큰보다 길이가 길다. -
주의사항
- payload는 암호화되지 않으므로 최소한의 데이터만을 담아야한다.
- jwt token을 강제로 만료시킬 방법이 없다. 토큰 발급 시 해당 토큰의 유효성이 결정되므로, 사용자는 사용을 만료했으나 만료가 안된 상황에서 탈취를 당한다면 만료 시점까지 그 토큰은 유효하다.

- Spring, JAVA
-
background
- 사용자 정의 예외: 개발자가 직접 정의하여 사용하는 예외이다.
- checked exception: 개발자가 반드시 예외 처리를 직접 진행해야하는 예외이다. ex. SQLException, IOException
- unchecked exception: 개발자가 예외처리를 직접 하지 않아도 되는 예외이다. (명시적으로 예외 처리가 강제되지 않는 예외이다.)
NullPointerException,ArrayIndexOutOfBoundException,NumberFormatException등이 있다.
자바의 모든 예외 클래스는 java.lang.Exception 클래스를 상속받는데, Exception 클래스 자체는 checked Exception이며, 그 자식들 중 RuntimeException은 unchecked이다.
-
사용자 정의 예외는 언제 사용해야할까?
예외 메시지로도 충분히 의미를 전달할 수 있고, 표준 예외를 사용하면 가독성도 높아지기 때문에 표준 예외를 사용하는 것이 더 나을수도 있다. 하지만 사용자 정의 예외를 사용하면 클래스 명으로도 정보 전달이 가능하며, 상세한 예외 정보를 제공할 수 있다. 또한 커스텀 예외를 사용하면 개발자가 인지한 상황에서 특정 예외를 던저주는 것이기 때문에 예외 발생에 대한 처리가 용이하다. -
사용자 정의 예외는 어떻게 구성하는 것이 좋을까? 예외 메시지 단위로 커스텀 예외를 생성하는 것은 수많은 예외 클래스를 낳고 관리가 어렵기에 매우 좋지 않은 방법이다. 따라서, 발생할 수 있는 가장 상위 행동으로 상위 예외 클래스를 만든 뒤, 도메인 별로 해당 상위 예외 클래스를 상속하여 구현한다. 그리고 각 예외 클래스는 예외 메시지만을 가지며 HttpStatus는 ExceptionHandler에서 관리하도록 함으로서 상태 코드에 대한 응집도를 높인다. 더불어 예외 메시지에 상세 정보를 담을 수 있도록 구성함으로서 디버깅에 용이하도록 구현하는 것이 좋다고 생각한다.
- Spring, JAVA
-
what
책임 연쇄 패턴이란 특정한 기준 범위 내의 명령을 처리할 수 있는 연산의 집합으로 구성된 처리 객체를 만들고, 그 처리 객체 들을 체인과 같이 연쇄적으로 연결하여 특정 처리 객체가 다룰 수 없는 명령은 다음의 처리 객체로 체이닝하여 연산에 대한 책임을 넘기는 것을 말한다. -
when
요금 계산 방법 기본운임(10㎞ 이내) : 기본운임 1,250원 이용 거리초과 시 추가운임 부과 10km초과∼50km까지(5km마다 100원) 50km초과 시 (8km마다 100원) 9km = 1250원 12km = 10km + 2km = 1350원 16km = 10km + 6km = 1450원 75km = 10km + 40km + 25km = 2450원다음과 같은 요구사항이 있을 때, if 분기문을 이용해서 처리한다면 아래와 같이 처리할 수 있다.
if (distance < 10) { return 1250; } if (distance < 50) { return calculateOverFare(distance, 5); } return calculateOverFare(distance, 8); private int calculateOverFare(int distance, int km) { return (int) ((Math.ceil((distance - 1) / km) + 1) * 100); }
이에 대해, 다음과 같은 기준을 적용하여 책임연쇄패턴으로 변경해보자.
- 특정 기준(거리)에 따라 요청을 수행(요금 계산 로직)할 수도 있고, 수행하지 못할 수도 있다.
- 그 기준(거리)을 넘으면 다음 연산 객체(요금 계산 로직을 가진 객체)에게 요청할 수 있다.
상위 인터페이스인 Chain을 만든 뒤, 체인들이 공통적으로 갖는 기능을 설정하자.
- 다음 체인을 유연하게 설정한다.
- 현재 체인에서 해당하는 요금을 계산한다.
- 현재 체인에서 처리할 수 없는 경우 다음 체인에게 요청을 넘긴다.
public interface FareChain { void setNextChainByChain(FareChain fareChain); int calculateFare(int distance); } public class FirstFare implements FareChain { private final int THRESHOLD = 10; FareChain nextFareChain; @Override public void setNextChainByChain(FareChain nextFareChain) { this.nextFareChain = nextFareChain; } @Override public int calculateFare(int distance) { if (distance > THRESHOLD) { return calculateFare(THRESHOLD) + nextFareChain.calculateFare(distance); } return 1250; } } public class SecondFare implements FareChain { private static final int KM = 5; private static final int THRESHOLD = 50; private static final int BASIC_THRESHOLD = 10; private FareChain nextFareChain; @Override public void setNextChainByChain(FareChain nextFareChain) { this.nextFareChain = nextFareChain; } @Override public int calculateFare(int distance) { if (distance > THRESHOLD) { return calculateFare(THRESHOLD) + nextFareChain.calculateFare(distance); } return (int) ((Math.ceil((distance - BASIC_THRESHOLD - 1) / KM) + 1) * 100); } } public class ThirdFare implements FareChain { private static final int KM = 8; private static final int THRESHOLD = 50; @Override public void setNextChainByChain(FareChain nextFareChain) { } @Override public int calculateFare(int distance) { return (int) ((Math.ceil((distance - THRESHOLD - 1) / KM) + 1) * 100); } }
-
why
요청을 보내는 객체와 이를 처리하는 객체간의 결합도를 느슨하게 할 수 있다.
내부에서 분기가 발생하지만, 실제 모두 분기로 처리하는 것에 비해 관리가 용이하며 새로운 기준이 추가될 시 다음 체인을 연결해주기만 하면 되기에 유지보수에 용이하다.

이 글은 Effective Java에서 나온 내용을 정리하였습니다.
-
what
객체 생성을 깔끔하고 유연하게 하기 위한 기법이다.
객체를 생성하는 패턴에는 먼저, 점층적 생성자 패턴(필수 생성자와 선택적 인자를 받는 생성자를 추가해가며 생성하는 방법)이 있다. 점층적 생성자 패턴을 사용한다면new Member("홍길동", "ㅁㅁ", "ㅌㅌ")와 같은 호출이 빈번히 일어날 때,new Member("홍길동")으로 대체할 수 있다. 하지만 단점으로는 다른 생성자를 호출하는 생성자가 많기에 인자가 추가되는 일이 발생하면 코드를 수정하기가 어렵고, 가독성이 떨어질 수도 있다. 특히 모두 같은 타입을 갖는 인자가 여러개일 때, 호출 코드만 보아서는 어떤 의미인지 알 수 없다.NutritionFacts cocaCola = new NutritionFacts(240, 8, 100, 3, 35, 27); NutritionFacts pepsiCola = new NutritionFacts(220, 10, 110, 4, 30); NutritionFacts mountainDew = new NutritionFacts(230, 10);이에 대안으로 자바빈 패턴이 소개된다. 자바빈 패턴은 먼저 객체를 생성한 뒤, 다른 인자들을 setter 메서드를 활용해 채워넣는 것이다. 이렇게 하는 경우 각 인자의 의미를 파악할 수 있게 되지만, 1회의 호출로 객체 생성이 끝나지 않으며 (한번에 생성 x 세터를 통해 객체에 값을 떡칠) setter가 존재하므로 변경불가능한 클래스를 만들 수가 없다.
따라서 등장하는 것이 Builder Pattern이다. 빌더 패턴은 점층적 생성자 패턴과 자바빈패턴의 장점을 취한 것으로 인자의 의미도 파악이 되며, 빌더 클래스를 이용해 한번에 클래스를 생성할 수 있으며 final로 선언도 가능하다.
-
when
생성자의 인자의 수가 많아질 때, 그리고 인자의 여러개가 같은 타입을 가져 생성자 하나로는 인자의 구분이 불분명할 때 사용할 수 있다. -
how
// 빌더 패턴의 대상이 될 Section 클래스 public class Section { private final Long id; private final Station upStation; private final Station downStation; private final int distance; // private 생성자로 변경 불가능한 객체 생성 private Section(Builder builder) { this.id = builder.id; this.upStation = builder.upStation; this.downStation = builder.downStation; this.distance = builder.distance; } // 정적 내부 클래스 public static class Builder { private final int distance; private Long id; private Station upStation; private Station downStation; // 생성자에서 타입으로 식별이 가능한 것은 Builder의 생성자 인자로 설정 public Builder(Long id, int distance) { this.id = id; this.distance = distance; } public Builder(int distance) { this.distance = distance; } // 타입이 동일해 구분하기 어려운 것들은 체이닝을 통해 set할 수 있도록 public Builder upStation(Station upStation) { this.upStation = upStation; return this; } public Builder downStation(Station downStation) { this.downStation = downStation; return this; } // 변경 불가능 객체 생성 메서드 public Section build() { return new Section(this); } }
빌더 패턴을 적용하여 객체를 생성하는 과정은 다음과 같다.
- 필요한 객체를 직접 생성하는 대신 먼저 타입이 중복되지 않고 필수인자인 것들을 생성자에 전달하여 빌더 객체를 만든다.
- 빌더 객체에 정의된 설정 메서드들을 호출하여 타입이 중복이거나 선택 인자인 것들을 추가한다.
- build 메서드를 호출하여 변경 불가능한 객체를 생성한다.
// given final Long id = 1L; final Station upStation = new Station(1L, "상행역"); final Station downStation = new Station(2L, "하행역"); final int distance = 10; // when final Section section = new Section.Builder(id, distance) .upStation(upStation) .downStation(downStation) .build();
-
why
장점- 작성하기 쉽고, 가독성이 좋다.
- 인자에 불변식을 적용할 수 있다.
- 하나의 빌더 객체로 여러 객체를 만들 수 있는 유연함
단점
- 객체 생성 시 빌더부터 생성해야하기에 성능 저하 가능
- 인자가 충분히 많지 않거나, 타입이 중복되지 않는 경우에는 굳이 사용해야할 이유가 없다.
- 하지만 인자가 늘어날 가능성이 높은 객체의 경우에는 사용하는 것이 도움이 될 수도 있다.
- 이펙티브 자바 https://www.informit.com/articles/article.aspx?p=1216151&seqNum=2
- https://johngrib.github.io/wiki/builder-pattern/
Request의 field에는 의식적으로 Wrapper 타입을 사용해주어야하는 것일까?
우선, 비객체 타입으로 Null을 가질 수 없는 형태를 갖는다. null이 들어오는 경우 NullPointerException을 발생시킨다.
또한 아래와 같이 default value를 갖는다.
| Data Type | Default Value (for fields) |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0L |
| float | 0.0f |
| double | 0.0d |
| char | '\u0000' |
| String (or any object) | null |
| boolean | false |
래퍼클래스는 기본형을 객체로 한번 감싼 클래스이다. 따라서 기본형을 객체로 다룰 수 있도록 해준다. 더불어 Wrappper 클래스는 null을 가지지 못하던 기본형을 객체로 한번 감쌌기 때문에 null을 가질 수 있다. 그리고 래퍼클래스는 기본형과 다르게 default 값을 null로 가진다.
기본 타입을 래퍼 클래스로 감싸는 과정을 Boxing, 래퍼 클래스로부터 기본 타입을 얻어내는 과정을 Unboxing이라고 한다. Java에서는 래퍼 클래스와 기본 타입을 혼용하며 사용할 때, 자동으로 박싱과 언박싱이 일어나게 된다. 예를 들어, int 타입의 값을 Integer 변수에 대입하면 자동 박싱이 일어나 힙 영역에 Integer 객체가 생성된다.
여기서 주의해야할 점은 Wrapper 클래스에서는 null을 허용하지만, 기본 타입에서는 허용하지 않기 때문에 언박싱 과정에서 NPE가 발생할 수 있으므로 주의해야한다.
- When to Use Wrapper Class and Primitive Type in Request DTO
- Wrapper Class를 사용했을 때의 장점
원하는 값이 들어왔을 때에만 그 값을 할당할 수 있다. (default가 null이므로)
null이 들어왔을 때 NPE를 발생시키지 않으므로 로직 상 null이 필요한 경우에 사용할 수 있다. - Primitive Type을 사용했을 때의 장점 기본 타입이 성능 상 더 낫다. 해당 필드를 생략해도 default가 들어가므로 null이 할당되지 않아 예기치 못한 NPE를 줄일 수 있다.
- 결론
우선 이 글의 가장 큰 주제는 Request DTO에서의 wrapper class와 primitive class이므로, 우선 토대로 생각해보았을 때 ID와 같은 값에는 우선 null을 할당하고, DB에 데이터를 넣은 뒤 값을 할당하기 때문에 이런 경우에는 Wrapper를 사용하는 것이 맞다고 생각된다. (0L을 할당하면 실제 0L의 id를 갖는 값이 존재할 수도 있다.) 또한 기본 타입에서 저절로 할당되는 default value를 절대로 허용하지 못하는 경우 또한 Wrapper를 사용하는 것이 맞을 것이다. (ex. 0으로 초기화되는 경우 비즈니스 로직에 문제를 일으킬 때) 이 외의 경우에는 성능 및 npe에서 생각해보았을 때 기본 타입을 사용하는 것이 더욱 우선순위일 것이라 생각된다.
- Wrapper Class를 사용했을 때의 장점
- https://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html
- https://stackoverflow.com/questions/1570416/when-to-use-wrapper-class-and-primitive-type/1570470
-
what
간단한 설정으로 프로젝트에서 지정한 url을 화면으로 확인할 수 있게 해 준다.
swagger ui가 적용된 페이지는 여기에서 확인할 수 있다.
swagger를 프로젝트에 적용할 경우 설정된 API URL 리스트들의 목록을 바로 확인할 수 있다.
또한 Postman과 같이 TEST할 수 있는 ui를 제공한다. -
how
- build.gradle에 아래 의존성을 추가한다.
compile group: 'io.springfox', name: 'springfox-swagger2', version: '2.5.0'
compile group: 'io.springfox', name: 'springfox-swagger-ui', version: '2.5.0'
- Swagger 설정 Bean을 프로젝트에 등록한다.
@Configuration
@EnableSwagger2
public class SwaggerConfig {
@Bean
public Docket api() {
return new Docket(DocumentationType.SWAGGER_2)
.select()
.apis(RequestHandlerSelectors.basePackage("wooteco.subway"))
.paths(PathSelectors.ant("/**"))
.build();
}
}- https://jojoldu.tistory.com/
- https://woowacourse.github.io/javable/post/2020-08-31-spring-swagger/
- https://stoplight.io/blog/difference-between-open-v2-v3-v31/
- JAVA, Spring, DB