This report presents a method to train AI to effectively generate content from smaller, structured datasets using Python. Gemini's token processing capabilities are leveraged to effectively utilize limited data, while techniques for interpreting CSV and JSON formats are explored.
In the era of rapidly advancing artificial intelligence (AI), the ability to analyze and leverage large datasets is paramount. While RAG (Retrieval Augmented Generation) environments are often ideal for such tasks, there are scenarios where content generation needs to be achieved with smaller datasets.
Gemini, with its capacity to process a significant number of tokens, offers a promising solution. By combining the power of prompts and uploaded files, it can effectively utilize even limited data. However, when dealing with structured data formats like CSV or JSON, it's essential to ensure AI can accurately interpret and understand the information.
This report will explore a practical approach to achieve this using Python scripting. We will delve into specific techniques and provide illustrative examples to demonstrate how AI can be effectively trained to effectively comprehend and generate content based on smaller, structured datasets.
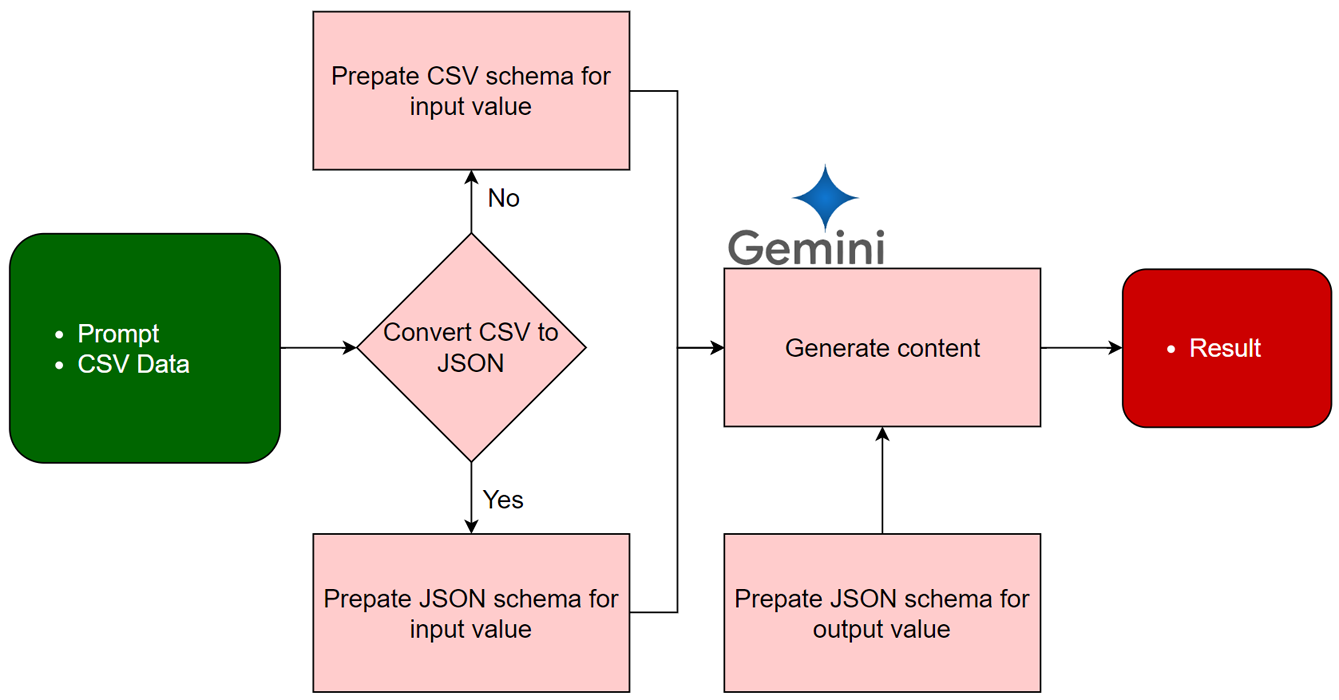
This is a flow diagram of the approach for generating content using Gemini and CSV data. Here are the steps involved:
- Data Preparation: Input: A CSV file containing the necessary data. Schema Creation: Direct CSV Usage: A CSV schema is generated to define the structure and types of the data within the CSV file, enabling Gemini to understand and process it effectively. CSV to JSON Conversion: If the CSV data is converted to JSON format, a JSON schema is created to describe the structure and types of the JSON data, providing Gemini with a clear understanding of the input.
- Output Schema Definition: A JSON schema is created to specify the desired structure and types of the output content. This schema can be used within the prompt itself or with the response_schema parameter to guide Gemini's generation process.
- Content Generation: Gemini utilizes the prepared input data and the defined prompt to generate the desired content. The output content adheres to the specified output schema.
- Result Return: The generated content is returned as the final output.
Please access https://ai.google.dev/gemini-api/docs/api-key and create your API key. At that time, please enable Generative Language API at the API console. This API key is used for the following scripts.
This official document can also be seen. Ref.
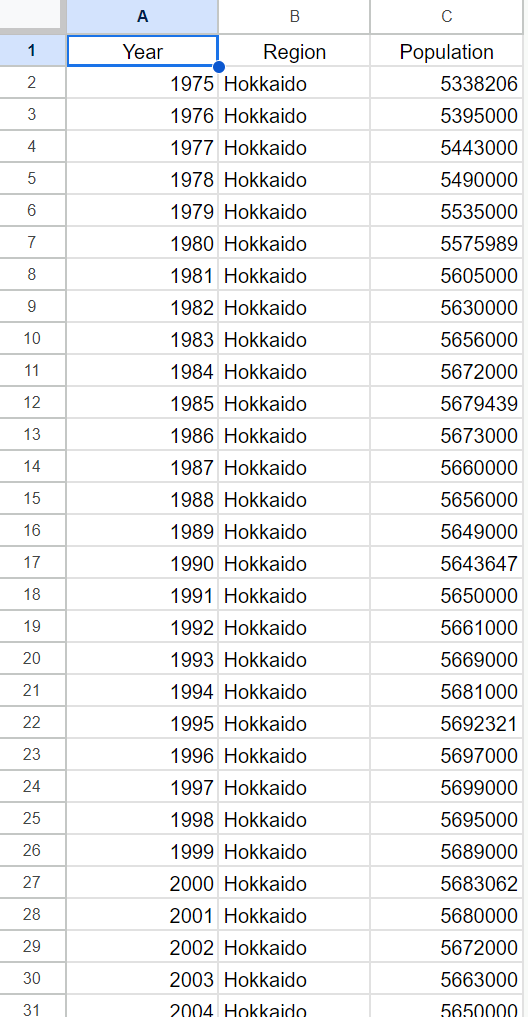
This report uses the sample data above. While the image depicts a Google Spreadsheet, the actual test utilizes CSV data converted from this spreadsheet. The filename of the CSV file is sample.csv.
The sample data originates from e-Stat (a portal site for Japanese Government Statistics), specifically columns "A", "B", and "C". These columns represent years, regions (all prefectures in Japan), and populations, respectively. Although only "Hokkaido" is shown in the image, the actual data encompasses all prefectures. The data consists of 2,303 rows and 3 columns and is used in CSV format for the following scripts.
This is a Python script.
This is a main class for testing the following sample scripts. Please create a file GenerateContent.py including the following script. The following sample scripts use this script as import GenerateContent.
import google.generativeai as genai
import io
import json
import requests
import time
class Main:
def __init__(self):
self.genai = None
self.model = None
self.api_key = None
def run(self, object):
self.api_key = object["api_key"]
self._setInstances(object)
print("Get file...")
file = self._uploadFile(object["name"], object["data"])
print("Generate content...")
response = self.model.generate_content(
[file, object["prompt"]], request_options={"timeout": 600}
)
data = None
try:
data = json.loads(response.text)
except json.JSONDecodeError:
data = response.text
return data
def _setInstances(self, object):
genai.configure(api_key=self.api_key)
generation_config = {"response_mime_type": "application/json"}
if "response_schema" in object:
generation_config["response_schema"] = object["response_schema"]
self.genai = genai
self.model = genai.GenerativeModel(
model_name="gemini-1.5-flash-002", # or gemini-1.5-pro-002
generation_config=generation_config,
)
def _uploadFile(self, name, text):
file = None
try:
file = genai.get_file(f"files/{name}")
except:
requests.post(
f"https://generativelanguage.googleapis.com/upload/v1beta/files?uploadType=multipart&key={self.api_key}",
files={
"data": (
"metadata",
json.dumps(
{
"file": {
"mimeType": "text/plain",
"name": f"files/{name}",
}
}
),
"application/json",
),
"file": ("file", io.StringIO(text), "text/plain"),
},
)
time.sleep(2)
file = genai.get_file(f"files/{name}")
print(f"File was uploaded.")
while file.state.name == "PROCESSING":
print(".", end="")
time.sleep(10)
file = genai.get_file(file.name)
if file.state.name == "FAILED":
raise ValueError(file.state.name)
return fileIn this pattern, CSV data is directly used. In order to make Gemini understand CSV data, I used a CSV schema. Also, in order to export the result as JSON data, I used a JSON schema. You can see them as csvSchema and jsonSchema in the following script. The prompt can be seen as prompt.
The function createData returns raw CSV data.
In this script, JSON schema for outputting is used in the prompt.
import GenerateContent
import json
api_key = "###" # Please set your API key.
filename = "sample.csv" # Please set your CSV file with the path.
def createPrompt():
csvSchema = {
"description": 'Order of "fields" is the order of columns of CSV data.\n"name" is the column name.\n"type" is the type of value in the column.',
"fields": [
{"name": "Year", "type": "number"},
{"name": "Region", "type": "string"},
{"name": "Population", "type": "number"},
],
}
jsonSchema = {
"description": "JSON schema for outputting the result.",
"type": "array",
"items": {
"type": "object",
"properties": {
"region": {"description": "Region name.", "type": "string"},
"reason": {
"description": "Reasons for the population increase.",
"type": "string",
},
"measures": {
"description": "Details of measures to stop the population increase.",
"type": "string",
},
"currentPopulation": {
"description": "Current population.",
"type": "number",
},
"futurePopulationWithMeasures": {
"description": "Future population after 50 years with measures to keep the population increasing.",
"type": "number",
},
"futurePopulationWithoutMeasures": {
"description": "Future population after 50 years without measures to keep the population increasing.",
"type": "number",
},
},
"required": [
"region",
"reason",
"measures",
"currentPopulation",
"futurePopulationWithMeasures",
"futurePopulationWithoutMeasures",
],
},
}
prompt = "\n".join(
[
"Run the following steps.",
'1. Read the CSV data in the following text file. The CSV schema of this data is "CSVSchema".',
f"<CSVSchema>{json.dumps(csvSchema)}</CSVSchema>",
"2. Using the data collected and your knowledge, predict 3 regions that will have the largest increase in population in the future in the order of increase. Return the region name, detailed reasons for the increase, and measures to keep the population increasing by considering the features of the region. Also, return the current population and the population 50 years later predicted by you with and without measures to keep the population increasing.",
'3. Return the result by following "JSONSchema".',
f"<JSONSchema>{json.dumps(jsonSchema)}</JSONSchema>",
]
)
return prompt
def createData(filename):
return open(filename, "r").read()
data = createData(filename)
prompt = createPrompt()
object = {
"api_key": api_key,
"name": "sample-name-1a",
"data": data,
"prompt": prompt,
}
res = GenerateContent.Main().run(object)
print(res)In this script, JSON schema for outputting is used with response_schema.
import GenerateContent
import json
api_key = "###" # Please set your API key.
filename = "sample.csv" # Please set your CSV file with the path.
def createPrompt():
csvSchema = {
"description": 'Order of "fields" is the order of columns of CSV data.\n"name" is the column name.\n"type" is the type of value in the column.',
"fields": [
{"name": "Year", "type": "number"},
{"name": "Region", "type": "string"},
{"name": "Population", "type": "number"},
],
}
prompt = "\n".join(
[
"Run the following steps.",
'1. Read the CSV data in the following text file. The CSV schema of this data is "CSVSchema".',
f"<CSVSchema>{json.dumps(csvSchema)}</CSVSchema>",
"2. Using the data collected and your knowledge, predict 3 regions that will have the largest increase in population in the future in the order of increase. Return the region name, detailed reasons for the increase, and measures to keep the population increasing by considering the features of the region. Also, return the current population and the population 50 years later predicted by you with and without measures to keep the population increasing.",
]
)
return prompt
def createData(filename):
return open(filename, "r").read()
jsonSchema = {
"description": "JSON schema for outputting the result.",
"type": "array",
"items": {
"type": "object",
"properties": {
"region": {"description": "Region name.", "type": "string"},
"reason": {
"description": "Reasons for the population increase.",
"type": "string",
},
"measures": {
"description": "Details of measures to stop the population increase.",
"type": "string",
},
"currentPopulation": {
"description": "Current population.",
"type": "number",
},
"futurePopulationWithMeasures": {
"description": "Future population after 50 years with measures to keep the population increasing.",
"type": "number",
},
"futurePopulationWithoutMeasures": {
"description": "Future population after 50 years without measures to keep the population increasing.",
"type": "number",
},
},
"required": [
"region",
"reason",
"measures",
"currentPopulation",
"futurePopulationWithMeasures",
"futurePopulationWithoutMeasures",
],
},
}
data = createData(filename)
prompt = createPrompt()
object = {
"api_key": api_key,
"name": "sample-name-1b",
"data": data,
"prompt": prompt,
"response_schema": jsonSchema,
}
res = GenerateContent.Main().run(object)
print(res)In this pattern, CSV data is used by converting to JSON data. In order to make Gemini understand JSON data, I used a JSON schema. Also, in order to export the result as JSON data, I used a JSON schema. You can see them as jsonSchema1 and jsonSchema2 in the following script. The prompt can be seen as prompt.
The function createData returns JSON data converted from CSV data as follows.
[
{"region": "Hokkaido", "populations": [{"year": "1975", "population": "5338206"} ,,,]},
{"region": "Aomori", "populations": [{"year": "1975", "population": "1468646"} ,,,]},
{"region": "Iwate", "populations": [{"year": "1975", "population": "1385563"} ,,,]},
,
,
,
}In this script, JSON schema for outputting is used in the prompt.
import GenerateContent
import csv
import json
api_key = "###" # Please set your API key.
filename = "sample.csv" # Please set your CSV file with the path.
def createPrompt():
jsonSchema1 = {
"description": 'JSON schema of the inputted value. The filename is "[email protected]".',
"type": "array",
"items": {
"type": "object",
"properties": {
"region": {"description": "Region name.", "type": "string"},
"populations": {
"description": "Populations for each year.",
"type": "array",
"items": {
"type": "object",
"properties": {
"year": {"type": "number", "description": "Year."},
"population": {
"type": "number",
"description": "Population.",
},
},
"required": ["year", "populations"],
},
},
},
"required": ["region", "populations"],
},
}
jsonSchema2 = {
"description": "JSON schema for outputting the result.",
"type": "array",
"items": {
"type": "object",
"properties": {
"region": {"description": "Region name.", "type": "string"},
"reason": {
"description": "Reasons for the population increase.",
"type": "string",
},
"measures": {
"description": "Details of measures to stop the population increase.",
"type": "string",
},
"currentPopulation": {
"description": "Current population.",
"type": "number",
},
"futurePopulationWithMeasures": {
"description": "Future population after 50 years with measures to keep the population increasing.",
"type": "number",
},
"futurePopulationWithoutMeasures": {
"description": "Future population after 50 years without measures to keep the population increasing.",
"type": "number",
},
},
"required": [
"region",
"reason",
"measures",
"currentPopulation",
"futurePopulationWithMeasures",
"futurePopulationWithoutMeasures",
],
},
}
prompt = "\n".join(
[
"Run the following steps.",
'1. Read the JSON data in the following text file. The JSON schema of this data is "JSONSchema1".',
f"<JSONSchema1>{json.dumps(jsonSchema1)}</JSONSchema1>",
"2. Using the data collected and your knowledge, predict 3 regions that will have the largest increase in population in the future in the order of increase. Return the region name, detailed reasons for the increase, and measures to keep the population increasing by considering the features of the region. Also, return the current population and the population 50 years later predicted by you with and without measures to keep the population increasing.",
'3. Return the result by following "JSONSchema2".',
f"<JSONSchema2>{json.dumps(jsonSchema2)}</JSONSchema2>",
]
)
return prompt
def createData(filename):
ar = list(csv.reader(open(filename, "r"), delimiter=","))[1:]
obj = {}
for r in ar:
year, region, population = r
v = {"year": year, "population": population}
obj[region] = (obj[region] + [v]) if region in obj else [v]
arr = [{"region": k, "populations": v} for (k, v) in obj.items()]
return json.dumps(arr)
data = createData(filename)
prompt = createPrompt()
object = {
"api_key": api_key,
"name": "sample-name-2a",
"data": data,
"prompt": prompt,
}
res = GenerateContent.Main().run(object)
print(res)In this script, JSON schema for outputting is used with response_schema.
import GenerateContent
import csv
import json
api_key = "###" # Please set your API key.
filename = "sample.csv" # Please set your CSV file with the path.
def createPrompt():
jsonSchema1 = {
"description": 'JSON schema of the inputted value. The filename is "[email protected]".',
"type": "array",
"items": {
"type": "object",
"properties": {
"region": {"description": "Region name.", "type": "string"},
"populations": {
"description": "Populations for each year.",
"type": "array",
"items": {
"type": "object",
"properties": {
"year": {"type": "number", "description": "Year."},
"population": {
"type": "number",
"description": "Population.",
},
},
"required": ["year", "populations"],
},
},
},
"required": ["region", "populations"],
},
}
prompt = "\n".join(
[
"Run the following steps.",
'1. Read the JSON data in the following text file. The JSON schema of this data is "JSONSchema1".',
f"<JSONSchema1>{json.dumps(jsonSchema1)}</JSONSchema1>",
"2. Using the data collected and your knowledge, predict 3 regions that will have the largest increase in population in the future in the order of increase. Return the region name, detailed reasons for the increase, and measures to keep the population increasing by considering the features of the region. Also, return the current population and the population 50 years later predicted by you with and without measures to keep the population increasing.",
]
)
return prompt
def createData(filename):
ar = list(csv.reader(open(filename, "r"), delimiter=","))[1:]
obj = {}
for r in ar:
year, region, population = r
v = {"year": year, "population": population}
obj[region] = (obj[region] + [v]) if region in obj else [v]
arr = [{"region": k, "populations": v} for (k, v) in obj.items()]
return json.dumps(arr)
jsonSchema2 = {
"description": "JSON schema for outputting the result.",
"type": "array",
"items": {
"type": "object",
"properties": {
"region": {"description": "Region name.", "type": "string"},
"reason": {
"description": "Reasons for the population increase.",
"type": "string",
},
"measures": {
"description": "Details of measures to stop the population increase.",
"type": "string",
},
"currentPopulation": {
"description": "Current population.",
"type": "number",
},
"futurePopulationWithMeasures": {
"description": "Future population after 50 years with measures to keep the population increasing.",
"type": "number",
},
"futurePopulationWithoutMeasures": {
"description": "Future population after 50 years without measures to keep the population increasing.",
"type": "number",
},
},
"required": [
"region",
"reason",
"measures",
"currentPopulation",
"futurePopulationWithMeasures",
"futurePopulationWithoutMeasures",
],
},
}
data = createData(filename)
prompt = createPrompt()
object = {
"api_key": api_key,
"name": "sample-name-2b",
"data": data,
"prompt": prompt,
"response_schema": jsonSchema2,
}
res = GenerateContent.Main().run(object)
print(res)[
{
"region": "Tokyo",
"reason": "Tokyo's robust economy, diverse job market, and well-established infrastructure continue to attract both domestic and international migrants. Its status as a global hub for business and culture ensures ongoing population growth.",
"measures": "Invest in affordable housing, improve public transportation, enhance green spaces and recreational facilities to improve quality of life, and continue promoting Tokyo as a global center for innovation and opportunity.",
"currentPopulation": 14086000,
"futurePopulationWithMeasures": 16000000,
"futurePopulationWithoutMeasures": 15000000
},
{
"region": "Osaka",
"reason": "Osaka is a major economic center with a strong industrial base and a thriving service sector. Its vibrant culture and relatively lower cost of living compared to Tokyo attract individuals seeking opportunities.",
"measures": "Focus on attracting skilled workers and entrepreneurs by offering tax incentives and streamlining business regulations. Improve affordable housing options and educational facilities. Promote Osaka's cultural attractions to attract tourists and residents.",
"currentPopulation": 8763000,
"futurePopulationWithMeasures": 10500000,
"futurePopulationWithoutMeasures": 9500000
},
{
"region": "Aichi",
"reason": "Aichi Prefecture benefits from its position as a major manufacturing and automotive hub. This strong industrial base and associated employment opportunities fuel consistent population growth.",
"measures": "Promote further diversification of the economy beyond automotive manufacturing to ensure long-term resilience. Invest in education and technology to attract highly skilled professionals. Develop sustainable infrastructure to enhance quality of life.",
"currentPopulation": 7477000,
"futurePopulationWithMeasures": 9000000,
"futurePopulationWithoutMeasures": 8000000
}
]Upon executing the scripts in the above section, we observed the following outcomes:
- Data Format Processing: Gemini successfully processed both CSV and JSON structured data formats by utilizing their corresponding schemas (CSV schema and JSON schema).
- Schema Effectiveness: Both schema approaches proved effective for Gemini's understanding of the input data.
- Reason Field Variability: While the specific values of the "reason" field might vary slightly across script executions due to the non-zero temperature input, the values of other fields remained consistent.
- Region Prediction Accuracy: In some cases, the predicted region differed from the expected outcome. However, in this case, the primary focus was on whether Gemini accurately understood the input data, regardless of the specific region prediction.
These findings highlight Gemini's ability to effectively handle structured data formats and leverage schemas for improved comprehension.
- In this report, Python script is used. However, this approach can be used for various languages for using Gemini API.
- The data size depends on the maximum token for Gemini API.
This report refers to the following references.
- Taming the Wild Output: Effective Control of Gemini API Response Formats with response_mime_type: Published on May 1, 2024
- Gemini API with JSON schema: Published on May 7, 2024
- Taming the Wild Output: Effective Control of Gemini API Response Formats with response_schema Published on May 21, 2024