Elasticsearch is an open-source search engine built on top of Apache Lucene™, a full-text search-engine library in Java.
Elasticsearch stores data as JSON documents, making it easy to be used together with MongoDB or CouchBase.
{
"_id": "55542458be37e10aa043ea41",
"owner_id": "131203376904913",
"social_roi": {
"engagements_count": 2,
"social_ids": [
{
"platform": "facebook",
"id": "100003475572725",
"acquired_date": "2012-11-29T16:07:50"
}
]
},
"demographic": {
"gender": "male",
"language": "en_US"
}
}In order to be able to treat date fields as dates, numeric fields as numbers, and string fields as full-text or exact-value strings, Elasticsearch needs to know what type of data each field contains. This information is kept as mapping.
ES is able to create mapping for fields based on its own guess, when data starts being indexed into it.
GET user_data/user_data/_mapping
{
"user_data": {
"properties": {
"demographic": {
"properties": {
"language": {
"type": "string",
"index": "not_analyzed"
},
"location": {
"type": "string"
},
}
},
"created_on": {
"type": "date",
"format": "dateOptionalTime"
}
}
}
}Adding mapping for new fields is easy, while changing mapping for an existing field is quite tricky. It's always recommended to specify a mapping for fields you expect to exist.
Elasticsearch provides a http-based RESTful API for searching.
Index <=> Database
Type <=> Table
"tian"?
GET /user_data/user_data/_search?q=tian
"tian", again?
POST /user_data/user_data/_search
{
"query": {
"match": {
"_all": "tian"
}
}
}People with Email: tianchu.nyc@gmail.com?
POST /user_data/user_data/_search
{
"query": {
"term": {
"emails": "tianchu.nyc@gmail.com"
}
}
}Explain?
GET /_validate/query?explain
{
"query": {
"term": {
"emails": "tianchu.nyc@gmail.com"
}
}
}Population distribution by language?
POST /user_data/user_data/_search
{
"aggregations": {
"all_languages": {
"terms": {
"field": "demographic.language"
}
}
},
"size": 0
}Data in Elasticsearch can be broadly divided into two types: exact values and full text.
Exact values are exactly what they sound like. Examples are a date or a user ID, but can also include exact strings such as a username or an email address. The exact value Foo is not the same as the exact value foo. The exact value 2014 is not the same as the exact value 2014-09-15.
Full text, on the other hand, refers to textual data—usually written in some human language — like the text of a tweet or the body of an email.
not_analyzed -> Exact match, "en_US" won't be tokenized and indexed as "en" and "US".
analyzed (default) -> Full text, "New York, NY" will be analyzed and indexed as "New", "York", and "NY". So you can search either "York" or "New York".


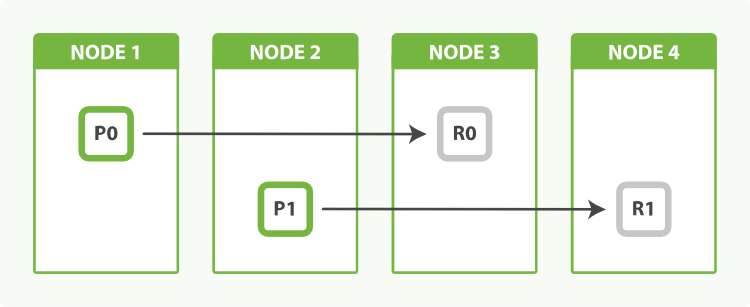
Elasticsearch is near-realtime, in the sense that when you index a document, you need to wait for the next refresh for that document to appear in a search. Refreshing is an expensive operation and that is why by default it’s made at a regular interval, instead of after each indexing operation.
Index Request -> Transaction Log -> Refresh() -> Segment (Searchable) -> Flush() -> Persisted
- No built-in authentication or access control.
- No support for transactions.
- Durability is not designed as a super high priority.
- Near-real-time data availability.
Elasticsearch Definitive Guide
Elasticsearch from the Top Down