Created
October 17, 2020 09:15
-
-
Save tnwei/11979239b145bfd9ed525a7f10adfa29 to your computer and use it in GitHub Desktop.
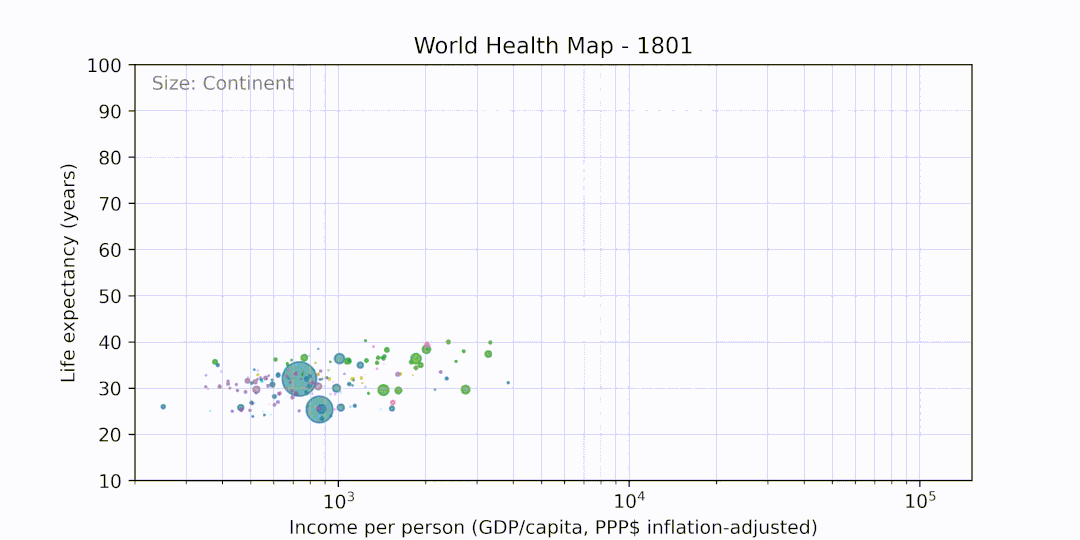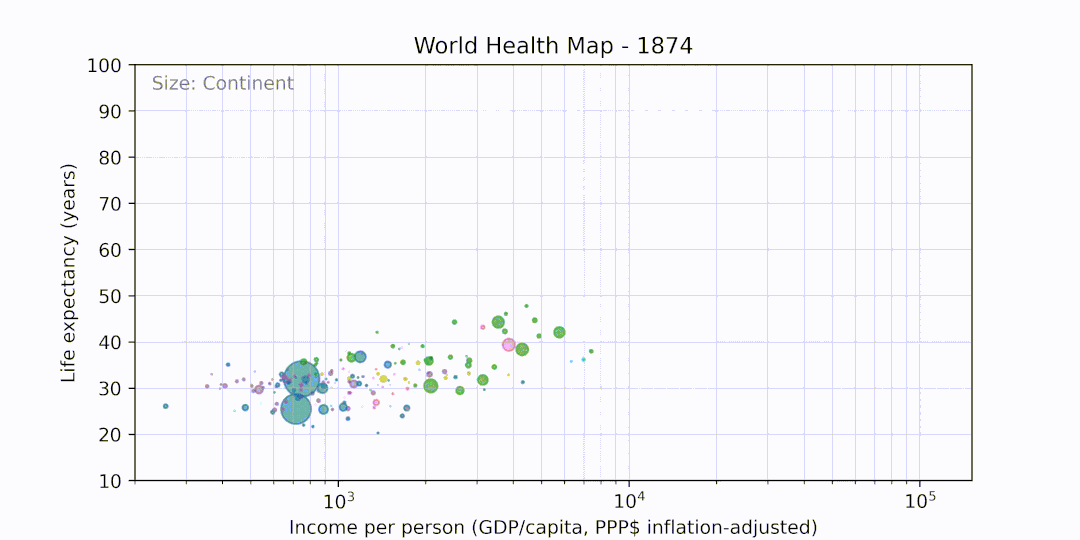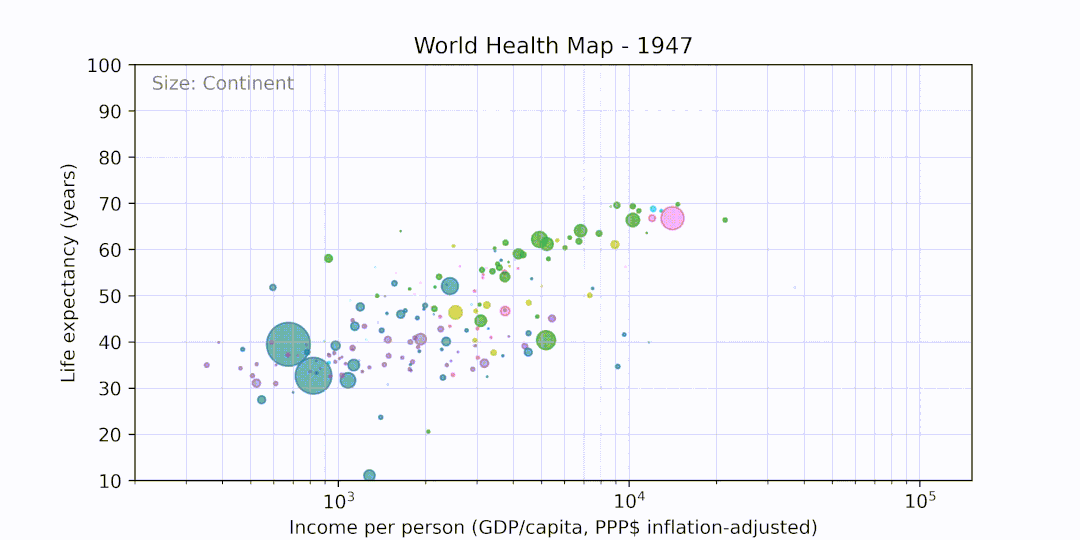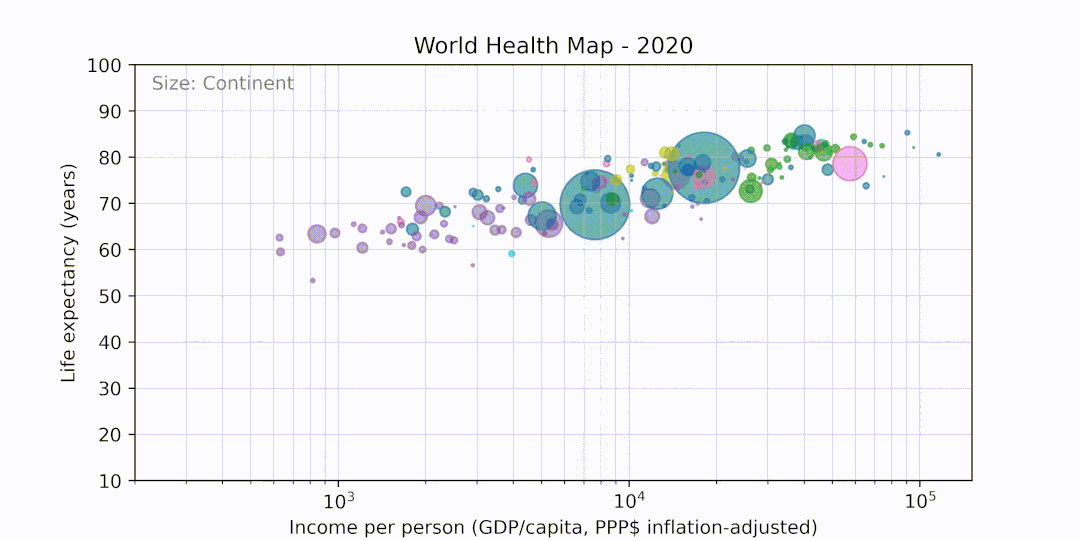
Recreates the World Health Chart visualization by Gapminder in Python, written as part of Week 4 of Exposure to Code.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| """ | |
| # Recreating World Health Chart by Gapminder | |
| Wrote this as part of week 4's course contents for Exposure to Code. | |
| Chart in question: https://www.gapminder.org/fw/world-health-chart/ | |
| ## Before running this script | |
| Obtain data required from https://www.gapminder.org/data/: | |
| + Select "Income" and download CSV, should have file name income_per_person_gdppercapita_ppp_inflation_adjusted.csv | |
| + Select "Life expectancy" and download CSV, should have file name "life_expectancy_years.csv" | |
| + Select "Population" and download CSV, should have file name population_total.csv | |
| This script assumes that these files above are available in the current working directory. | |
| ## Requirements | |
| This Python script requires `pandas`, `numpy`, `matplotlib` and `pycountry_convert` to run. The computer will also need `ffmpeg` installed separately. | |
| """ | |
| import pandas as pd | |
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| import matplotlib.animation as animation | |
| import pycountry_convert as pc | |
| ## Data loading and wrangling -------------------------------------------------- | |
| pop = pd.read_csv("population_total.csv", index_col=0) | |
| income = pd.read_csv("income_per_person_gdppercapita_ppp_inflation_adjusted.csv", index_col=0) | |
| life = pd.read_csv("life_expectancy_years.csv", index_col=0) | |
| # Datasets contain projections into the future, not interested in those | |
| yearnow = str(2020) | |
| life_idxlim = life.columns.tolist().index(yearnow) | |
| income_idxlim = income.columns.tolist().index(yearnow) | |
| pop_idxlim = pop.columns.tolist().index(yearnow) | |
| life = life[life.columns[:life_idxlim+1]] | |
| pop = pop[pop.columns[:pop_idxlim+1]] | |
| income = income[income.columns[:income_idxlim+1]] | |
| # Remove countries that are not in all of the datasets | |
| common_countries = set(income.index).intersection(set(life.index)).intersection(set(pop.index)) | |
| income = income.drop(index=[i for i in income.index if i not in common_countries]) | |
| life = life.drop(index=[i for i in life.index if i not in common_countries]) | |
| pop = pop.drop(index=[i for i in pop.index if i not in common_countries]) | |
| # Meanwhile, we also need country by continent | |
| # From https://stackoverflow.com/a/59166127/13095028 | |
| def country_to_continent(country_name): | |
| country_alpha2 = pc.country_name_to_country_alpha2(country_name) | |
| country_continent_code = pc.country_alpha2_to_continent_code(country_alpha2) | |
| country_continent_name = pc.convert_continent_code_to_continent_name(country_continent_code) | |
| return country_continent_name | |
| countries = income.index.to_series() | |
| continents = pd.Series(index=countries, dtype="object", name="continents") | |
| for i in countries: | |
| try: | |
| continents.loc[i] = country_to_continent(i) | |
| except: | |
| continents.loc[i] = None | |
| # Manually putting in the country names for this: | |
| continents.loc["Congo, Dem. Rep."] = "Africa" | |
| continents.loc["Congo, Rep."] = "Africa" | |
| continents.loc["Cote d'Ivoire"] = "Africa" | |
| continents.loc["Lao"] = "Asia" | |
| continents.loc["Micronesia, Fed. Sts."] = "Oceania" | |
| continents.loc["St. Vincent and the Grenadines"] = "North America" | |
| continents.loc["Timor-Leste"] = "Asia" | |
| # Use following code to save mapping continents, to skip code chunk above | |
| # continents.to_csv("country2continents.csv") | |
| # country2continents = pd.read_csv("country2continents.csv", index_col=0) | |
| # continents = country2continents.squeeze().tolist() | |
| # Change continents to numbers for plotting | |
| cont2num = {} | |
| count = 0 | |
| for i in continents: | |
| if i not in cont2num: | |
| cont2num[i] = count | |
| count += 1 | |
| cont_nums = list(map(lambda x:cont2num.get(x), continents)) | |
| ## Plotting by year -------------------------------------------------- | |
| def sample_data_by_year(year, life, income, pop): | |
| life_srs = life[str(year)] | |
| income_srs = income[str(year)] | |
| pop_srs = pop[str(year)] | |
| life_srs.name = "life" | |
| income_srs.name = "income" | |
| pop_srs.name = "pop" | |
| res = pd.concat([life_srs, income_srs, pop_srs], axis=1) | |
| return res | |
| ## This code chunk is for exporting the excerpt of data used for the | |
| ## in-class exercise | |
| # df = sample_data_by_year(2020, life, income, pop) | |
| # df["continent"] = cont_nums | |
| # df.to_csv("world_health_chart_2020.csv") | |
| # | |
| ## Following is the class exercise solution: | |
| # | |
| # life2020 = df["life"] | |
| # income2020 = df["income"] | |
| # pop2020 = df["pop"] | |
| # countries2020 = df.index | |
| # | |
| # plt.figure(figsize=(10, 5)) | |
| # plt.scatter(x=income2020, y=life2020, s=pop2020 / 1e6, c=cont_nums, cmap="tab10", alpha=0.6) | |
| # plt.xscale("log", base=10) | |
| # | |
| # plt.grid(which="both", alpha=0.3) | |
| # plt.ylabel("Life") | |
| # plt.xlabel("GDP") | |
| # plt.title("World Health Map - 2020") | |
| # | |
| # plt.show() | |
| ## Recreating the gapminder plot -------------------------------------------- | |
| # Ref: https://jakevdp.github.io/blog/2012/08/18/matplotlib-animation-tutorial/ | |
| # Ref: https://stackoverflow.com/questions/9401658/how-to-animate-a-scatter-plot | |
| # Ref: https://stackoverflow.com/questions/14666439/how-to-set-the-image-resolution-for-animations | |
| years = [str(i) for i in range(1801, 2021, 1)] | |
| max_frames = len(years) | |
| year = years[0] | |
| # From experimentation, use for x-limits (20, 90), and for y-limits (200, 151000) | |
| # Initialize static elements | |
| fig, ax = plt.subplots(figsize=(8, 4)) | |
| ax.grid(which="both", alpha=0.3) | |
| ax.set_ylabel("Life expectancy (years)") | |
| ax.set_xlabel("Income per person (GDP/capita, PPP$ inflation-adjusted)") | |
| ax.set_xscale("log", base=10) | |
| # Adding an annotation here | |
| ax.text(x=0.02, y=0.94, s="Size: Continent", transform=ax.transAxes, color="gray") | |
| # Set static x and y plot limits for the whole animation | |
| ax.set_xlim((200, 151000)) | |
| ax.set_ylim((10, 100)) | |
| # Initialize dynamic elements | |
| title_text = ax.set_title("World Health Map - " + year) | |
| df = sample_data_by_year(year, life, income, pop) | |
| scatter = ax.scatter( | |
| x=df["income"], y=df["life"], s=[df["pop"] / 1e6], | |
| c=cont_nums, cmap="tab10", alpha=0.6 | |
| ) | |
| # And the function to further initialize them | |
| def init_plot(): | |
| global title_text, scatter | |
| title_text.set_text("") | |
| # Cheeky way of getting empty array w/ shape (0, 2) | |
| init_pos = np.array([[], []]).reshape(0, 2) | |
| scatter.set_offsets(init_pos) | |
| scatter.set_sizes(np.array([])) | |
| return title_text, scatter | |
| # Animate function mirrors structure of init_plot() | |
| def animate_make_world_health_plot(i): | |
| """ | |
| i is the frame number | |
| """ | |
| # Make the necessary calculations | |
| global life, income, pop, years | |
| global title_text, scatter | |
| year = years[i] | |
| df = sample_data_by_year(year, life, income, pop) | |
| # Make changes | |
| title_text.set_text("World Health Map - " + year) | |
| scatter.set_offsets(df[["income", "life"]].values) | |
| scatter.set_sizes(df["pop"].values / 1e6) | |
| return title_text, scatter | |
| ani = animation.FuncAnimation( | |
| fig, animate_make_world_health_plot, frames=max_frames, | |
| interval=150, blit=True, init_func=init_plot | |
| ) | |
| dpi = 500 | |
| # Save as mp4 | |
| ani.save('world-health-map.mp4', dpi=dpi, extra_args=['-vcodec', 'libx264']) | |
| plt.close() | |
Author
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Produces the following output: