Created
October 24, 2023 17:10
-
-
Save topepo/3dbd9bb7cdecc364abe24d8bb1f53752 to your computer and use it in GitHub Desktop.
A simple comparison of two models with different feature set approaches
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| library(tidymodels) | |
| library(doMC) | |
| # ------------------------------------------------------------------------------ | |
| tidymodels_prefer() | |
| theme_set(theme_bw()) | |
| options(pillar.advice = FALSE, pillar.min_title_chars = Inf) | |
| registerDoMC(cores = parallel::detectCores()) | |
| # ------------------------------------------------------------------------------ | |
| data("Chicago") | |
| n <- nrow(Chicago) | |
| p <- 1 - (14/n) | |
| Chicago <- | |
| Chicago %>% | |
| select(ridership, date) | |
| init_split <- initial_time_split(Chicago, prop = p) | |
| chi_train <- training(init_split) | |
| chi_test <- testing(init_split) | |
| # ------------------------------------------------------------------------------ | |
| # The effects in the data are almost completely driven by the day-of-the-week | |
| # and holidays. For example: | |
| plot_start <- 1050 | |
| chi_train %>% | |
| mutate( | |
| day = lubridate::wday(date, label = TRUE), | |
| day = factor(day, ordered = FALSE) | |
| ) %>% | |
| slice(plot_start:(plot_start + 35)) %>% | |
| ggplot(aes(date, ridership)) + | |
| geom_point(aes(col = day), cex = 2) + | |
| geom_line(alpha = .2) | |
| # ------------------------------------------------------------------------------ | |
| chi_rs <- | |
| chi_train %>% | |
| sliding_period( | |
| index = c(date), | |
| period = "week", | |
| lookback = 12 * 52, | |
| assess_stop = 2, | |
| step = 2 | |
| ) | |
| # ------------------------------------------------------------------------------ | |
| # Use a handful of date features to get good preformance | |
| lm_rec <- | |
| recipe(ridership ~ date, data = chi_train) %>% | |
| step_date(date) %>% | |
| step_holiday(date) %>% | |
| update_role(date, new_role = "date id") | |
| lm_res <- | |
| linear_reg() %>% | |
| fit_resamples(lm_rec, chi_rs) | |
| collect_metrics(lm_res) | |
| # ------------------------------------------------------------------------------ | |
| # Convert data to integers and let the network figure it out. | |
| nnet_rec <- | |
| recipe(ridership ~ date, data = chi_train) %>% | |
| step_mutate(day_index = as.numeric(date)) %>% | |
| step_normalize(day_index) %>% | |
| update_role(date, new_role = "date id") | |
| nnet_spec <- | |
| mlp( | |
| hidden_units = tune(), | |
| penalty = tune(), | |
| epochs = tune() | |
| ) %>% | |
| set_mode("regression") %>% | |
| # open up the range of the initial values ('rang') in case that's an issue | |
| set_engine("nnet", rang = 0.75) | |
| print(translate(nnet_spec)) | |
| nnet_param <- | |
| nnet_spec %>% | |
| extract_parameter_set_dials() %>% | |
| update( | |
| hidden_units = hidden_units(c(2, 100)), | |
| epochs = epochs(c(150, 10000)) | |
| ) | |
| set.seed(3828) | |
| nnet_res <- | |
| nnet_spec %>% | |
| tune_grid(nnet_rec, chi_rs, grid = 25, param_info = nnet_param) | |
| show_best(nnet_res) | |
| autoplot(nnet_res) | |
| nnet_fit <- | |
| workflow( | |
| nnet_rec, | |
| finalize_model(nnet_spec, select_best(nnet_res, metric = "rmse")) | |
| ) %>% | |
| fit(chi_train) | |
| augment(nnet_fit, chi_train) %>% | |
| mutate( | |
| day = lubridate::wday(date, label = TRUE), | |
| day = factor(day, ordered = FALSE) | |
| ) %>% | |
| slice(plot_start:(plot_start + 35)) %>% | |
| ggplot(aes(day_index, ridership)) + | |
| geom_point(aes(col = day), cex = 2) + | |
| geom_line(aes(y = .pred)) | |
| # ------------------------------------------------------------------------------ | |
| # Use the simple features with the network | |
| nnet_feat_rec <- | |
| recipe(ridership ~ date, data = chi_train) %>% | |
| step_mutate(day_index = as.numeric(date)) %>% | |
| step_date(date) %>% | |
| step_holiday(date) %>% | |
| update_role(date, new_role = "date id") %>% | |
| step_range(all_numeric_predictors()) %>% | |
| step_dummy(all_factor_predictors(), one_hot = TRUE) | |
| set.seed(3828) | |
| nnet_feat_res <- | |
| nnet_spec %>% | |
| tune_grid(nnet_feat_rec, chi_rs, grid = 25, param_info = nnet_param) | |
| autoplot(nnet_feat_res) |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Hey Max,
I played around with
lm,nnet, andglmnetjust to give you some quick insights. I'll summarize the insights below, and then give you the code to reproduce.Insights
My approach differs a bit:
What I see is that LM overfits badly with the features I gave it. NNET and GLMNET do well.
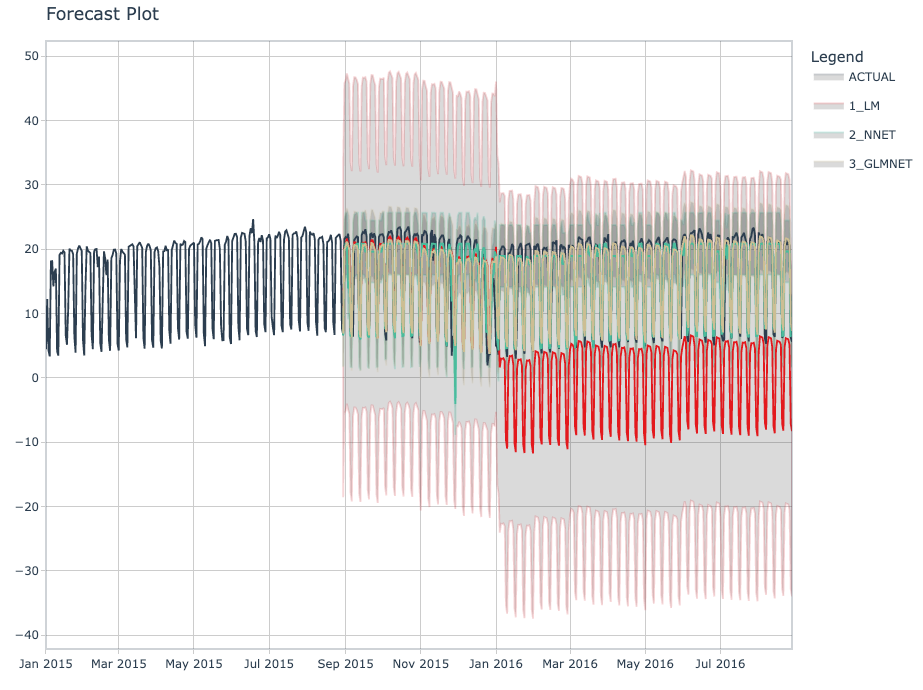
The future forecast looks much better with the GLMNET model as compared to the NNET model. This is because I did not perform tuning. But it's worth noting that the GLMNET is very simple - Just add a little penalty and it needs no tuning to give a good forecast. NNET needs tuning.
Code