Fernrohr 17. Jahrhundert Optische Telegraphie
Tachygraph (Claude Chappe) 18. Jhd.
[Bild Verstellbare Balken]
8³ Mögliche Armpositionen ... 512
A-Z,&,1-10 enkodiert
[Bild Elektrolysebad]
36 Drähte
Gasblasen steigen an der der Position der stromführenden Drähte auf.
Magnetische Nadeln schlagen bei Stromfluss aus
[Bild Samuel Morse Telegraph] Nach Samuel Morse
[Bild Alfred Vail Telegraph] Morsecode aus kurzen und langen Signalen nach ALfred Vail
1844 Telegraphenverbindung zwischen Washington nach Baltimore
1866 Telegraphenverbindung über den Atlantik
Häufige Zeichen werden mit weniger Anschlägen encodiert als weniger Häufige Zeichen.
[Bild Zeichentabelle]
5 bit Blöcke
Zwei Zeichentabellen; eine für Buchstaben eine für Zaheln und Sonderzeichen. Umschalten mittels Umschaltzeichen.
[Bild Baudot Code]
Telephon, patetntiert von Bell -> Bell Labs
Bell Labs für lange Zeit Branchenführend.
Maxwell/Hertz endecken Elektromagnetische Wellen
Marconi
Elektonischer Verstärker
Claude Shannon "A Mathematical Theory of Communicaion"
Shannon'sches Kommunikationsmodell
[Bild ^]
Nachrichten werden nur zu bestimmter wahrscheindlichkeit zuverlässig übertragen.
Information einer Nahcricht = entropie
Wichtig für Datenkompression
Analoger Begriff: Redundanz
Informationsteile werden mehrmals übertragen -> Nachricht länger
übersetzung eines Signales in ein anderes (codiertes) Signal.
Gründer:
- anderes Medium
- Fehlererkennung/-behebung
- Effiziens
[Beispiel ISBN]
- Konstruktion geeigneter codes
- Fehlererkennung
- Fehlerkorrektur
-
Alphabet: Endliche, nicht leere Menge "Σ" (aus Zeichen).
Σ = {0,1}
-
Wort der Länge n; w ∈ Σ x Σ x ... Σ = Σ^n.
Σ x Σ = {(0,0),(0,1),(1,0),(1,1)}
= { 00, 01, 10, 11}
Σ³ = Σ x Σ x Σ = {(0,0,0), ...}
Σ^+= Σ^1 + Σ^2 + Σ^3 + ...
leere Menge ε ∈ Σ^0
Σ^* = Σ^0 ∪ Σ^+
- Endliche Menge M
- Codierung c: Injektive Abbildung c: M |-> Σ^*
- Code C = c(m) | m ∈ M.
- Daraus folgt C ⊆ Σ^*.
Injektiv: zwei unterschiedliche Nachrichten haben auch zwei unterschiedliche Codierungen. Es gibt mehr Codewörter als codierbare Nachrichten..
C = {c(m)|m ∈ M} ... Menge aller Codewörter C ⊆ Σ^*
Es gibt kein Codewort welches Präfix eines anderen Codeworts ist.
w ∈ C
u = w . v, v != ε
u !∈ C
Σ = {0,1}
C = {1001, 0011, 0101}
Σ = {0,1}
C = {1100, 0101, 0011}
Es ist möglich eine Abstand zwischen zwei Wörtern in Σ^n zu bilden. Der Abstand ist die Anzahl der Buchstaben an welchem sich die Wörter unterscheiden.
d(1000, 0000) = 1
d(0011, 0110) = 2
d ... ist eine Abstandfunktion (Metrik).
d(a,b) >= 0
d(a,b) = 0 => a=b
d(0110, 1000) = 3
d(0011, 1000) = 3
Dreiecksungleichung d(a,c) <= d(a,b) + d(b,c)
Translations Invariant: d(a + c, b + c) = d(a,b) ... wäre nett, ist aber nicht immer erfüllt.

C = {00, 11}
Codewort welches vom Sender versendet wird kommt nicht immer so beim Empfänger an. Der Empfänger erhält ein Wort aus Σ^n und sucht das nächstliegende Codewort in C um die bestmögliche decodierung zu erhalten.
-
Wie groß muss der Minimalabstand d(C) sein, damit
- bis zu t Fehler erkannt werden können?
- bis zu t Fehler korrigiert werden können?
-
Geben sie eine Beispiel zu entsprechenden Codes an.
[Hamming Decodierung Fehlererkennung]
- Gegeben ist Alphabet A und Quelle F.
- Auftrittswahrscheindlichket (relative Häufigkeit) eines Zeichens a ∈ A ist p_F(a)
- Informationsgehalt: I_F(a) = log_2(1/p_F(a))
- Intuition Je größer der Informationsgehalt desto größer die "Überaschung", dass das Zeichen auftritt.
Warum Logarithmus?
Bei der Annäherung an ein Konkretes Wort nähert man sich mit jedem Rateversuch an das Wort an. Bei jedem Versuch halbiert sich die Menge in dem dass Wort liegen kann. Anzahl der Versuche ist daher log(|Menge an Wörtern|)
Mittlerer Informationsgehalt pro Zeichen.
[Formel Entropie]
- Text aus Großbuchstaben, Leerzeichen und dem Satzzeichen "." (insgesamt 28 Zeichen)
- Wahrscheindlichkeiten gleich verteilt

-
Text aus Großbuchstaben, Leerzeichen und dem Satzzeichen "." (insgesamt 28 Zeichen)
- p_F für die 5 Vokale 1/10
- p_F für Leerzeichen 1/5
- p_F für "." 1/20
- p_F für D,H,L,N,R,S,T 1/56
- p_F für die restlichen 14 Buchstaben (???)
[komplexere Berechnung Informationsgehalt]
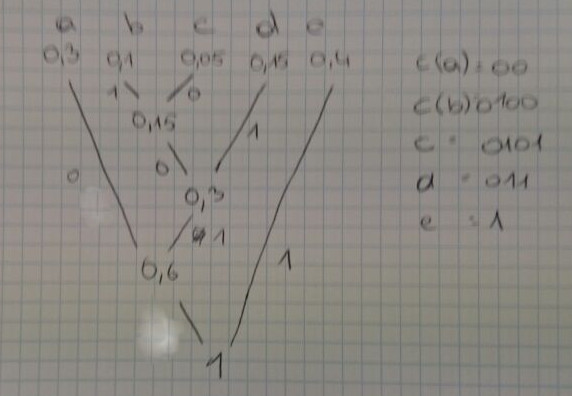
Kein Blockcode. Präfixcode.
Häufige Zeichen werden mit weniger Bits codiert.
Seltenere Zeichen mit mehr Bits.
- Alphabet: a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z,.," "
- ℤ_5
| + | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 1 | 2 | 3 | 4 | 0 |
| 2 | 2 | 3 | 4 | 0 | 1 |
| 3 | 3 | 4 | 0 | 1 | 2 |
| 4 | 4 | 0 | 1 | 2 | 3 |
| * | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 1 | 2 | 3 | 4 |
| 2 | 0 | 2 | 4 | 1 | 3 |
| 3 | 0 | 3 | 1 | 4 | 2 |
| 4 | 0 | 4 | 3 | 2 | 1 |
- ℤ*_4 (Teilerfremde zahlen < 4)
| * | 1 | 3 |
|---|---|---|
| 1 | 1 | 3 |
| 3 | 3 | 1 |
- "seltsame" Algebra
| ° | a | b | c |
|---|---|---|---|
| a | c | a | a |
| b | c | b | a |
| c | b | c | b |
x ° b = x
b ist eingeschränkt neutral, rechtsneutral
- Algebra mit neutralem Element
| ° | a | b | c |
|---|---|---|---|
| a | c | a | a |
| b | a | b | c |
| c | b | c | b |
b ist neutrales Element
a ° c = b
c ° a = b
b ° b = b
a und c sind inverse zueinander da b neutrales Element ist

A={a,b,c}
P(A) = {
{},
{a}, {b}, {c},
{a,b}, {a,c}, {b,c},
{a,b,c}
}
(ℚ, +, *)
- (ℚ, +) muss eine Gruppe sein: stimmt
- (ℚ\{0}, *) muss eine Gruppe sein: stimmt
-
- und * sind distributiv
Wenn alles zutrifft ist (ℚ, +, *) ein Körper