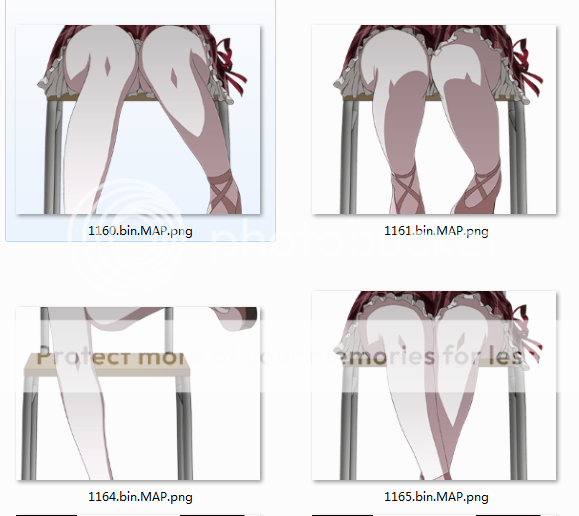
从cpk中解包出来的大部分图片类文件中只有一个文件。但是其中也有部分文件中含有多个图片。这点必须注意。
无论是哪一种图片,都有一个特点,调色板,head,数据并未压缩,但是具体的图像数据是经过gzip压缩的。gzip大数据块由多个小数据块组成,大数据块的起始位置是0x400对齐的。
在学生会游戏中捷报出来的图片,按照gzip数据块的位置分成两种。
- 只有一个调色板的 [情况1]
start len
0x0 0x400 256色RGBA调色板
0x400 0x1400 头信息,可为全0
0x1800 some Len gzip 大数据块
- 一个或者多个调色板的 [情况2]
start len
0x0 0x400 * n 若干个256色RGBA调色板
0x400 * n some Len gzip大数据块1(一个大数据块对应一个调色板)
next addr some Len gzip大数据块2
gzip大数据块的主要构成如下
start len
0x0 4 gzip小块个数
0x4 + 4 * i 4 第i个gzip小数据块的起始偏移
0x4 + 4 * i + 4 4 第i个gzip小数据块的终止偏移,也是i+1个小数据块起始偏移
addr[align=0x10] 在最后一个偏移之后,下一个0x10的对齐的地址处是第一个小数据块位置
其中如果有n个小数据块,则会有n+1个偏移,最后一个偏移,是最后一个小数据块的终止位置的偏移。
对于每一个小数据块,其结构如下
start len
0x0 4 gzip压缩块解压缩后块大小
0x10 4 1f 8b 08开始的gzip块
对于第一部分中提及的[情况2],或者[情况1]中头信息全为0的情况,我们认为这种图片是不需要拼图的,认为其为[REG](Regular)图片。而有头信息的,我们则认为其为[MAP]图片。
对于此类图片,就是简单的16*8的tile类型图片。但是由于未知宽高,只能靠数据推测。根据学生会游戏中所有导出的图片判断,所有的图片的宽度都为512,而高度可以通过数据区大小除以512得到。
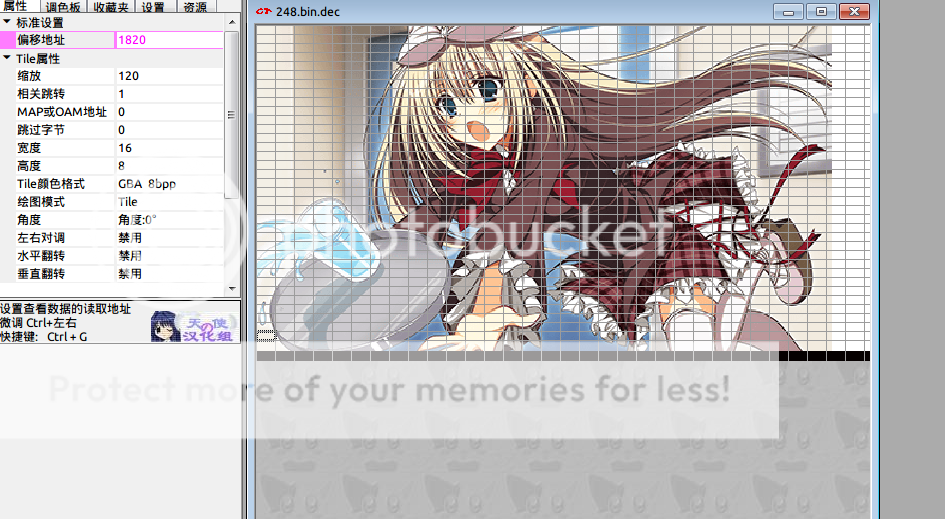
tile转化的主要代码,可以参见我写的fromTile
# tarW, tarH 目标图像大小,如512,272
# toW, toH 是最终保存的图像大小,切割30*272后的480, 272
# tiles 16*8的tile数组
def fromTile(pixBuf, tarW, tarH, \
toW, toH, \
tiles, pal = 0):
tileW = 16
tileH = 8
tileInW = tarW / tileW
for picY in xrange(toH):
for picX in xrange(toW):
tileOut = picY / tileH * tileInW + picX / tileW
tileIn = picY % tileH * tileW + picX % tileW
if pal == 0:
pixBuf[picY*toW + picX] = tiles[tileOut][tileIn]
else:
getInd = ord(tiles[tileOut][tileIn])
colBuf = pal[4 * getInd: 4 * getInd + 4]
pixBuf[picY*toW + picX] = tuple([ord(colCh) for colCh in colBuf])此类图片的关键即是在0x400多了拼图数据。但是其中有部分数据是属于脸部表情,其具体的拼图坐标在文件中并不存在,只有后半部分的拼图信息,因此为了能正确处理,必须根据头信息讲前半部分的头部数据单独提取出来。
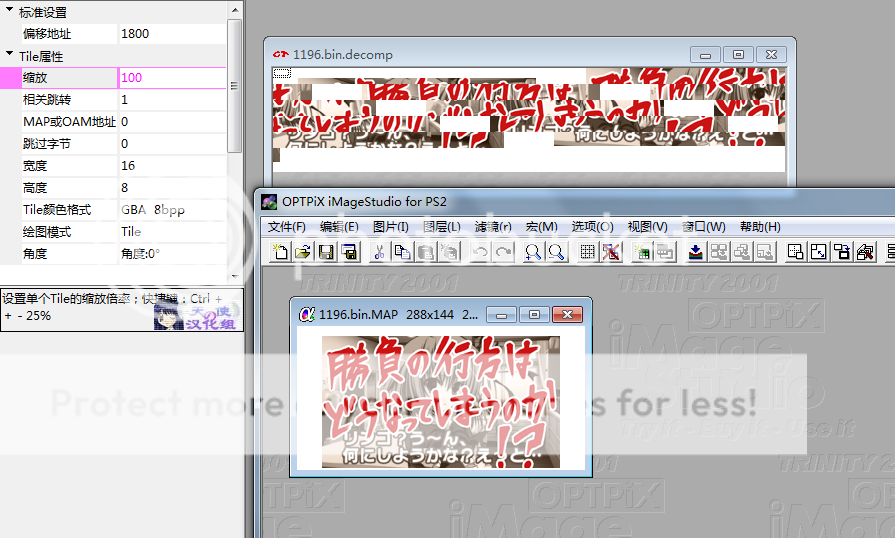
具体的头信息如下所示
0x400
-----0x00 4d 41 50 00(MAP\0)
-----0x04 e4 00 (map区长度,从0x400开始)
-----0x06 28 00 (0x28(numPos) 坐标的个数,每个坐标数据4个字节)
-----0x08 20 00(0x20=32) 宽上32个拼图块
-----0x0a 10 00(0x10=16) 拼图块宽为16 (宽=32*16 = 512)
-----0x0c 03 00(0x03=3) 高上3个拼图块
-----0x0e 10 00(0x10=16) 拼图块高16 (高=3*16=48)(不含脸和嘴)
-----0x10 00 60 00 00 (0x6000 数据区总长度,包括前半部分脸和嘴,和后半部分)
-----0x14 00 02 00 00 (未知)
-----0x18 01 01 (未知)
-----0x1a 00 00 (有脸和嘴的非0,意义未知)
-----0x1c 00 02 (0x200=512,实际图片宽)
-----0x1e 80 00 (0x80=96, 实际图片高,包括前半部分脸和嘴,和后半部分) = val[0x0c] * val[0x0e] + val[0x22]
-----0x20 00 00 (未知)
-----0x22 50 00 (0x50=80,脸部分高度,无脸为0)
-----0x24 00 00 (未知)
-----0x26 10 00 (未知)
-----0x28 20 00 (未知)
-----0x2a 00 00 (未知)
-----0x2c 00 00 ff ff
-----0x30 起
-----====numPos个4字节数据
数据基本上市后面不变,前面变,下面是例子
X= 192 Y= 0
X= 224 Y= 0
X= 160 Y= 16
X= 192 Y= 16
X= 224 Y= 16
X= 160 Y= 32
X= 192 Y= 32
前半部分就不细说了,基本上就跟上面描述的一样,可以参考下我的代码理解。最重要的是后半部分拼图数据的分析理解。
001 [x] = 0x0000, 0, 0[/16] [y] = 0x0000, 0, 0[/16]
002 [x] = 0x0020, 32, 2[/16] [y] = 0x0000, 0, 0[/16]
003 [x] = 0x0040, 64, 4[/16] [y] = 0x0000, 0, 0[/16]
004 [x] = 0x0060, 96, 6[/16] [y] = 0x0000, 0, 0[/16]
005 [x] = 0x0000, 0, 0[/16] [y] = 0x0010, 16, 1[/16]
006 [x] = 0x0020, 32, 2[/16] [y] = 0x0010, 16, 1[/16]
007 [x] = 0x0040, 64, 4[/16] [y] = 0x0010, 16, 1[/16]
008 [x] = 0x0060, 96, 6[/16] [y] = 0x0010, 16, 1[/16]
009 [x] = 0x0000, 0, 0[/16] [y] = 0x0020, 32, 2[/16]
010 [x] = 0x0020, 32, 2[/16] [y] = 0x0020, 32, 2[/16]
011 [x] = 0x0040, 64, 4[/16] [y] = 0x0020, 32, 2[/16]
012 [x] = 0x0060, 96, 6[/16] [y] = 0x0020, 32, 2[/16]
013 [x] = 0x0000, 0, 0[/16] [y] = 0x0030, 48, 3[/16]
014 [x] = 0x0020, 32, 2[/16] [y] = 0x0030, 48, 3[/16]
015 [x] = 0x0040, 64, 4[/16] [y] = 0x0030, 48, 3[/16]
016 [x] = 0x0060, 96, 6[/16] [y] = 0x0030, 48, 3[/16]
017 [x] = 0x0000, 0, 0[/16] [y] = 0x0040, 64, 4[/16]
018 [x] = 0x0020, 32, 2[/16] [y] = 0x0040, 64, 4[/16]
019 [x] = 0x0040, 64, 4[/16] [y] = 0x0040, 64, 4[/16]
020 [x] = 0x0060, 96, 6[/16] [y] = 0x0040, 64, 4[/16]
根据上面的例子,发现规律,y不动,x每次加32。y每次加16,x再从头开始变化,从这个结合下图ct2中的截图可以发现,每个坐标信息,代表由4个16*8的tile组成的32*16的tile,其x,y值即代表赐个tile在目标图片中的坐标值。
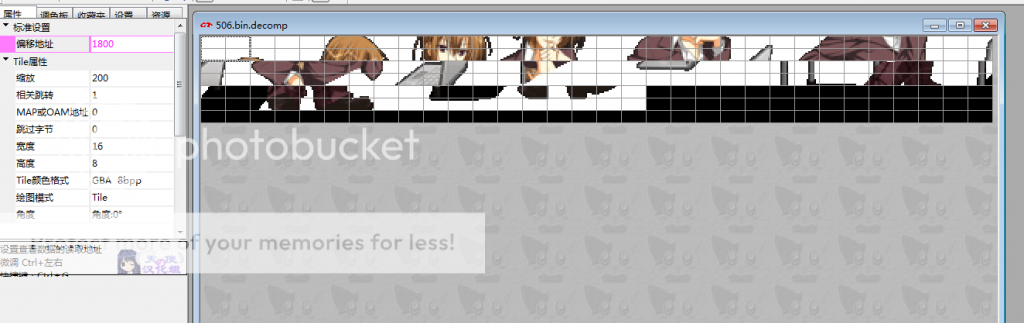
如何处理这种组合tile问题呢。我才用了这样一个思路
1.每次读取 两行 16*8 的tile, 共 64 * (16*8)
curFile.seek(0x1800)
lineLen = BASE_TILE_H * BASE_TILE_W * num_tile_w * (tile_h / BASE_TILE_H)
lineLen2 = BASE_TILE_H * BASE_TILE_W * num_tile_w
multiLines = []
for i in xrange(num_tile_h):
multiLines.append(curFile.read(lineLen))2.每两行tile,从左往右一次读入4个,合成为1个32*16,生成若干个32*16的tile
def getBigTile(mLine, big_tile_list, NUM_BT_W, line_len):
curPos = 0
for i in xrange(NUM_BT_W):
blk = []
blk.append(mLine[curPos: curPos + BASE_TILE_H * BASE_TILE_W])
blk.append(mLine[curPos + BASE_TILE_H * BASE_TILE_W : curPos + BASE_TILE_H * BASE_TILE_W * 2])
blk.append(mLine[line_len + curPos: line_len + curPos + BASE_TILE_H * BASE_TILE_W])
blk.append(mLine[line_len + curPos + BASE_TILE_H * BASE_TILE_W : line_len + curPos + BASE_TILE_H * BASE_TILE_W * 2])
pixBuf = [0] * (32 * 16)
fromTile(pixBuf, 32, 16, blk)
big_tile_list.append(pixBuf)
curPos = curPos + BASE_TILE_H * BASE_TILE_W * 2
big_tile_list = []
for mLine in multiLines:
getBigTile(mLine, big_tile_list, NUM_BT_W, lineLen/2)- 将32*16的tile根据坐标信息,贴入目标图片
def mapTile(pixBuf, tarW, tarH, tile, pal):
tileW = 32
tileH = 16
tileInW = tarW / tileW
for picY in xrange(tarH, tarH + tileH):
for picX in xrange(tarW, tarW + tileW):
tileIn = (picY - tarH) * tileW + (picX - tarW)
getInd = ord(tile[tileIn])
colBuf = pal[4 * getInd: 4 * getInd + 4]
pixBuf[picX, picY] = tuple([ord(colCh) for colCh in colBuf])
for i, tile in enumerate(big_tile_list):
if i == len(mapTable):
break
mapTile(pixImage, mapTable[i][0], mapTable[i][1], tile, pal)依照此思路便可将图片拼起来,如果有脸部数据,则需要单独提取出来,按照[REG]图片的思路单独导出来即可。
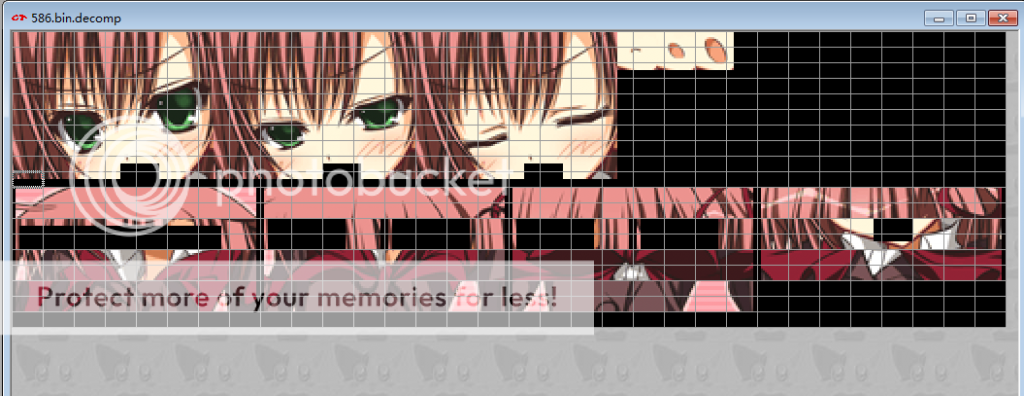
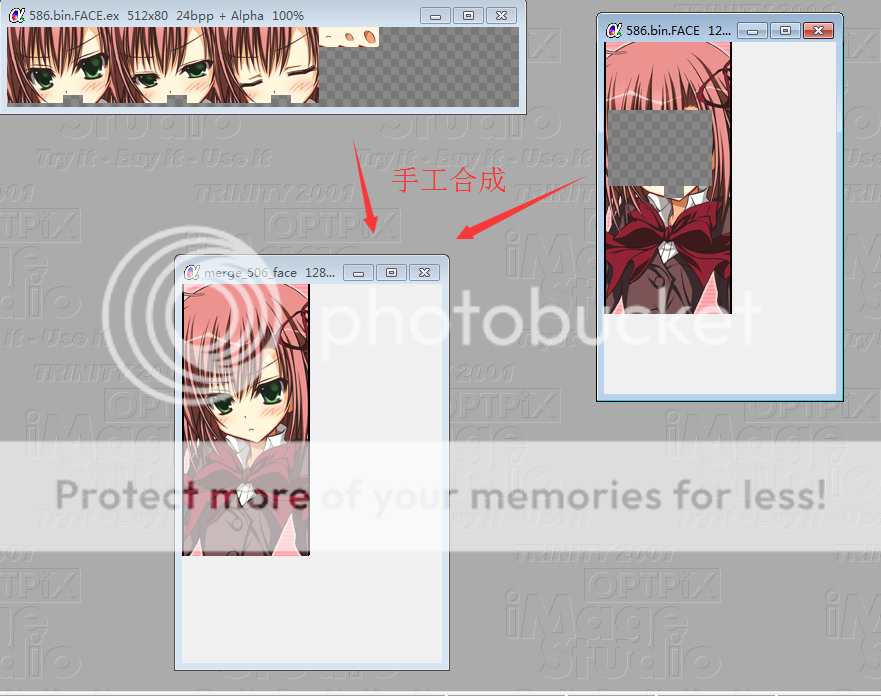
下面是我自己讲脸部数据,和后半部分分开的结果。最后尝试人工合成了下,效果还不错
下载地址:http://pan.baidu.com/s/1o6ODNnG
pw: seitokai_stardrad


####表情是单独导出的