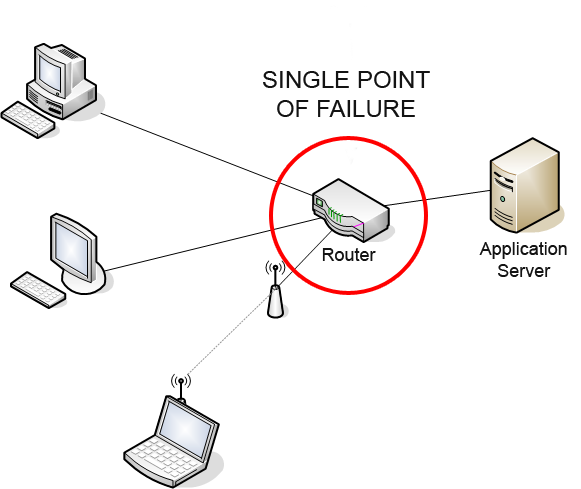
A single point of failure (SPOF) is a part of a system that, if it fails, will stop the entire system from working.
A quorum is the minimum number of votes that a distributed transaction has to obtain in order to be allowed to perform an operation in a distributed system.
Arbiter - 조정자
A split-brain(a network partition) indicates data or availability inconsistencies originating from the maintenance of two separate data sets with overlap in scope
Computer cluster consists of a set of loosely or tightly connected computers that work together so that, in many respects, they can be viewed as a single system.
A set of policies and procedures to enable the recovery or continuation of vital technology infrastructure and systems following a natural or human-induced disaster.
The continuation of a service after the failure of one or more of its components.
The distribution of workloads across multiple computing resources.
Load balancing is often used to implement failover.
- DNS based
- Routing Policy
- Weighted, Lantency, Failover set, Geo-location
- AWS Route53
*.example.com- virtual hosts
- Host HTTP/1.1 header
- Multi host names bound to one IP address.
A data storage virtualization technology that combines multiple physical disk drive components into a single logical unit for the purposes of data redundancy, performance improvement, or both.


DM(device mapper)-Multipathing provides input-output (I/O) fail-over and load-balancing by using multipath I/O within Linux for block devices.

Object storage on a single distributed computer cluster. Ceph aims primarily for completely distributed operation without a single point of failure, scalable to the exabyte level.

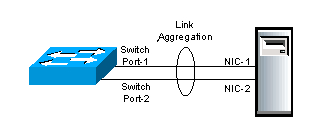
Combining (aggregating) multiple network connections in parallel in order to increase throughput beyond what a single connection could sustain, and to provide redundancy in case one of the links should fail.

- Service Registration
- Service Discovery
- DNS support: Consul only
- Consistent and durable general-purpose K/V store
- Leader Election
-
Consul
-
ready to use(DNS, health check), commercially supported.
-
Zookeeper
-
Java
-
old but stable
-
Etcd
-
new and just simple K/V store.
-
ttl, atomic
- TTL
- compareAndDelete, compareAndSwap
- znode 단위로 관리된다.
- znode는 파일 시스템과 유사한 디렉토리 구조(path)를 가진다.
- znode에 데이터를 저장할 수 있다.
- znode의 변화 watch
- Zookeeper와 클라이언트의 연결이 끊어지면 자동으로 삭제
- EPHEMERAL
- EPHEMERAL_SEQUENTIAL : Ticketing
- No TTL
var zk = require('zkHelper'),
options = {
basePath: '/myapps';
configPath: '/myapps/config',
node: require('os').hostname(),
servers: ['zk0:2181', 'zk1:2181', 'zk2:2181'], // zk servers
clientOptons: { sessionTimeout: 10000, retries: 3 }
};
zk.init(options, function (err, zkClient) {
if (zk.isMaster()) {
console.info('I am master')
} else {
console.info('master', zk.getMaster() && zk.getMaster().master)
}
var config = zk.getConfig();
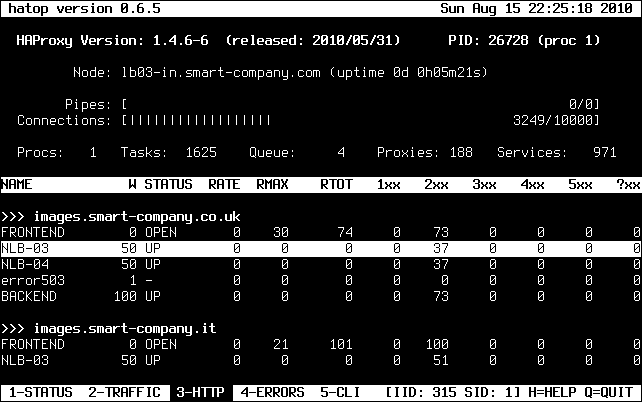
});HAProxy is free, open source software
that provides a high availability load balancer and proxy server for TCP(L4) and HTTP-based applications(L7)
that spreads requests across multiple servers.
-
manpage: fast and reliable http reverse proxy and load balancer
-
LVS(Linux Virtual Server) : L4 only alternative; kernel space impl.


frontend mqtt_fe
option tcplog
bind :1883
mode tcp
timeout client 90s
default_backend mqtt_be
backend mqtt_be
mode tcp
timeout server 90s
server mqtt.1 10.0.0.11:1883 maxconn 50000 check inter 2000 rise 2 fall 3
server mqtt.2 10.0.0.22:1883 maxconn 50000 check inter 2000 rise 2 fall 3
server mqtt.3 10.0.0.13:1883 maxconn 50000 check inter 2000 rise 2 fall 3
frontend mqttwss_fe
option httplog
bind :8083
bind :8483 ssl crt mqtt.pem
redirect scheme https if !{ ssl_fc }
mode http
default_backend mqttwss_be
backend mqttwss_be
mode http
cookie SRV insert indirect nocache
server mqtt.1 10.0.0.11:80 cookie mqtt.1 maxconn 50000 check inter 2000 rise 2 fall 3
server mqtt.2 10.0.0.22:80 cookie mqtt.2 maxconn 50000 check inter 2000 rise 2 fall 3
server mqtt.3 10.0.0.13:80 cookie mqtt.3 maxconn 50000 check inter 2000 rise 2 fall 3
frontend HttpFrontend
bind *:80
mode http
acl fooBackend hdr_beg(host) -i foo.
acl barBackend hdr_beg(host) -i bar.
use_backend fooBackend if fooBackend
use_backend barBackend if barBackend
default_backend bazBackend
<...>
- Use haproxy instead of AWS ELB
- Update haproxy to use all instances running in a security group.
update-haproxy.py [-h] --security-group SECURITY_GROUP [SECURITY_GROUP ...] --access-key ACCESS_KEY --secret-key SECRET_KEY [--output OUTPUT] [--template TEMPLATE] [--haproxy HAPROXY] [--pid PID] [--eip EIP] [--health-check-url HEALTH_CHECK_URL] ```
- -D : daemon
- -f : config file(/etc/haproxy/haproxy.cfg)
- -p : pid file to have its children's pids
- -sf pidlist
- Send FINISH signal to the pids in pidlist after startup.
- The processes which receive this signal will wait for all sessions to finish before exiting.
- -st pidlist
- Send TERMINATE signal to the pids in pidlist after startup.
- The processes which receive this signal will wait immediately terminate, closing all active sessions.
- use GSLB
- Active/Standby
- sysctls tunning
ulimit -a
- multi-process
- ssl offloading
- dedicate process for a task
- dedicate processor for irq handling
global
nbproc 4 # number of processes
frontend access_http
bind 0.0.0.0:80
bind-process 1 # dedicate one process to http
mode http
default_backend backend_nodes
frontend access_https
bind 0.0.0.0:443 ssl crt /etc/yourdomain.pem
bind-process 2 3 4 # dedicate the other processes to https
mode http
option forwardfor
option accept-invalid-http-request
reqadd X-Forwarded-Proto:\ https
default_backend backend_nodes
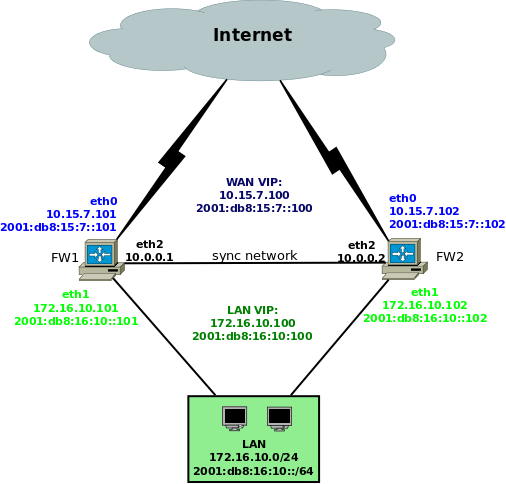
- VRRP(Virtual Router Redundancy Protocol)
- LVS(Linux Virtual Server)
vrrp_instance E1 {
interface eth0
state BACKUP
virtual_router_id 61
priority 100
advert_int 1 # advertise every 1sec to multicast: 224.0.0.18
virtual_ipaddress {
10.15.7.100/24 dev eth0
2001:db8:15:7::100/64 dev eth0
}
nopreempt
garp_master_delay 1 # 1sec delay for gratuitous ARP after transition to MASTER
}
Sync {
Mode FTFW {
DisableExternalCache Off
}
UDP {
IPv4_address 10.0.0.1
IPv4_Destination_Address 10.0.0.2
Port 3780
Interface eth2
SndSocketBuffer 1249280
RcvSocketBuffer 1249280
Checksum on
}
}
- FW1: 장애로, VRRP advertise pkt 전송 안됨.
- FW2: VIP 할당되고, gratuitous ARP pkt 전송.
- switch port의 mac address 갱신.
- nodes의arp table 갱신.
- FW2: external cache(FW1's conntrack info) --> internal(kernel) cache로 갱신함.
provides clustering infracture such as membership, messaging and quorum.
# quorum 이 구성
quorum {
provider: corosync_votequorum
two_node: 0
}
# totem protocol 설정
totem {
version: 2
token: 3000 # token 을 받지 못해서 해당 노드 fail로 판단하는 시간(ms)
token_retransmits_before_loss_const: 10
join: 60
consensus: 3600 # 새로운 q uorum member을 구성을 시작하는 전 기다리는 시간(ms).
...
}
It is an open source high availability resource manager software used on computer clusters since 2004. Its preferred API for this purpose is the OCF resource agent API.
- OCF(Open Cluster Framework)
- LSB(linux standard base) init script와 유사한 shell script이다.
- Resource Agent를 만드는데 이용된다.
- exit code에 따라 pacemaker가 다른 행동을 한다.
Two-node Active/Passive clusters using Pacemaker and DRBD are a cost-effective solution for many High Availability situations

By supporting many nodes, Pacemaker can dramatically reduce hardware costs by allowing several active/passive clusters to be combined and share a common backup node.

When shared storage is available, every node can potentially be used for failover. Pacemaker can even run multiple copies of services to spread out the workload.

node 13: node-03
node 2: node-01
node 9: node-02
property cib-bootstrap-options: \
dc-version=1.1.12-561c4cf \
cluster-infrastructure=corosync \
no-quorum-policy=stop \
stonith-enabled=false \
start-failure-is-fatal=false \
symmetric-cluster=false \
last-lrm-refresh=1490016772
- 나머지 두 node는 정상 동작.
- 문제가 된 node는 quorum 구성을 못하고, 해당 node의 모든 resource stop!
- no-quorum-policy=stop
conntrackd : one master at a node and slaves are on the other nodes. vip public : one resource at a node.
primitive p_conntrackd ocf:fuel:ns_conntrackd \
op monitor interval=30 timeout=60 \
op monitor interval=27 role=Master timeout=60 \
params bridge=br-mgmt \
meta migration-threshold=INFINITY failure-timeout=180s
primitive vip__vrouter_pub ocf:fuel:ns_IPaddr2 \
op monitor interval=5 timeout=20 \
op start interval=0 timeout=30 \
op stop interval=0 timeout=30 \
meta migration-threshold=3 failure-timeout=60 resource-stickiness=1
ms master_p_conntrackd p_conntrackd \
meta notify=true ordered=false interleave=true clone-node-max=1 master-max=1 master-node-max=1
vip internal, vip public and conntrackd at the same node.
location master_p_conntrackd-on-node-01 master_p_conntrackd 100: node-01
location master_p_conntrackd-on-node-02 master_p_conntrackd 100: node-02
location master_p_conntrackd-on-node-03 master_p_conntrackd 100: node-03
colocation conntrackd-with-pub-vip inf: vip__vrouter_pub:Started master_p_conntrackd:Master
colocation vip__vrouter-with-vip__vrouter_pub inf: vip__vrouter vip__vrouter_pub
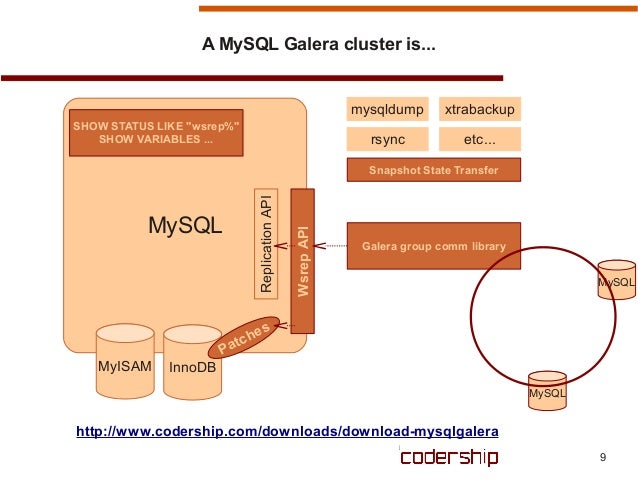
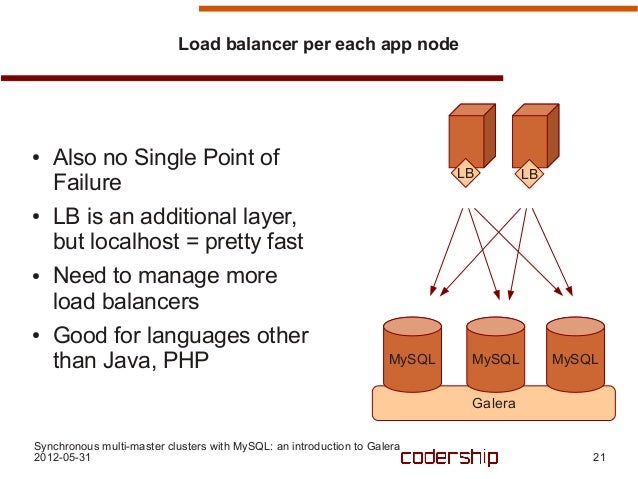
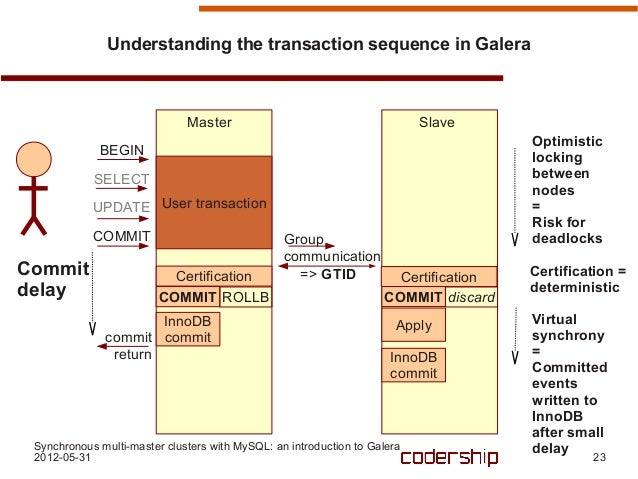
- WSRep(Write set replication)
- GTID(Global Transaction ID) : {uuid}:{sequence number}
- State: INIT -> JOINER -> JOINED -> SYNCED
- SST(State Snapshot Transfers)
- IST(Incremental State Transfers)
- IST trigger condition:
- 해당 클러스터 그룹의 state UUID와 joiner node의 statu UUID가 같아야 함
- 모든 missing write-sets이 donor의 write-set 캐시에 존재 해야 함
-
zookeeper, etcd, consul : builing block for own coordinator; loosely connected;
-
haproxy: failover and load balancing micro services.
-
Pacemaker: Pacemaker is really only designed to do membership and failure detection at small scale
<50nodes. tightly connected.
- Technology : ...
- Process : documented, clear ownership.
- People : skill set, attitudes, leadership, role & responsibiltiy.