PageSpy 是一个适用于远程 Web 项目调试的工具。在最近的更新中,还添加了对微信小程序的支持。
它通过对浏览器/微信小程序 API 的封装,将调用原生方法时的参数进行过滤、转化,整理成指定格式的消息供调试端消费;调试端收到消息后,在类似 Chrome devtools 的面板中将数据呈现出来。对于前端开发者来说,上手零成本。

如果你现在还为调试远端的网页而苦恼,不妨先把 PageSpy 部署起来。如果你已经是 PageSpy 用户或者对这类调试工具的实现感兴趣,不妨跟着本文的讲解一探究竟。
主仓库地址:https://github.com/HuolalaTech/page-spy-web ,觉得好用的小伙伴可以点个 ⭐️。
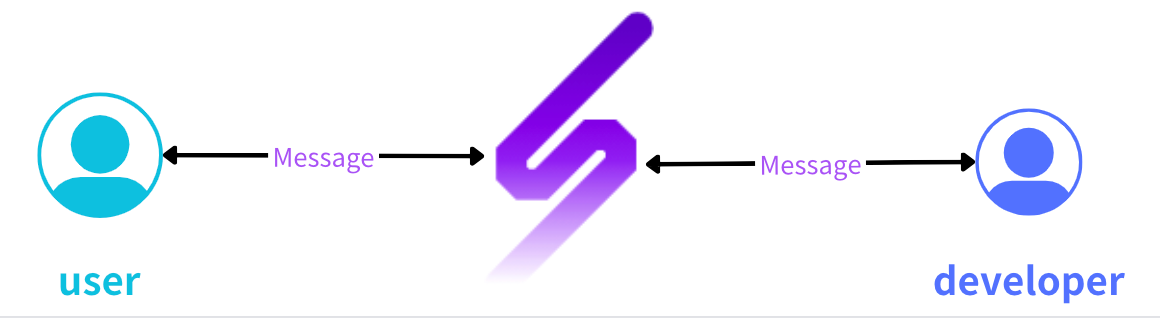
为了实现远端调试的功能,PageSpy 是需要在服务器部署后端服务的。借助后端服务,调试端 (开发者) 与用户端 (远端的用户) 建立了连接,并可以实时通信。下图简单描述整个过程。
因此 page-spy-web 仓库中既有前端代码也有后端代码。
├── src # 前端代码
├── backend # 后端代码
├── ...
从上图中可以看出,用户端以及调试端分别与服务器之间建立了连接。为了保障通信的实时性,使用 WebSocket 来传输消息再合适不过了。
// https://github.com/HuolalaTech/page-spy/blob/main/src/utils/socket.ts
const socket = new WebSocket('wss://remote-url');
socket.addEventListener('open', onOpen);
// ...
socket.addEventListener('message', onReceiveMessage);在连接建立后,我们就重点关注 WebSocket 传输哪些内容。
JSON 数据可读性好,也便于浏览器处理。在 WebSocket 连接中传输的便是标准的 JSON 数据。消息的结构可以用下方的 interface 来代表。
// https://github.com/HuolalaTech/page-spy/blob/main/types/lib/message-type.d.ts
interface MessageItem<T> {
role: 'client' | 'debugger';
type: 'console' | 'network' | 'debug' | '...';
data: T;
}其中的 role 字段用于区分消息的来源,type 表明消息的类型,data 则是具体的消息内容,这个因 type 而异。用户端/调试端在收到特定的消息类型后,执行相应的操作,比如:
- 将用户端页面的网络请求展示调试端的 Network 面板
- 在用户端浏览器中执行调试端发送代码片段
确定了消息的格式后,接下来工作的核心便是尽可能地采集用户端的数据,将收集到的数据封装成指定的 Message 就可以发送到调试端。
对于开发者来说,需要关注的有以下几种数据:DOM,Console,Error,网络,Storage 等。
使用 document.documentElement.outerHTML 即可获得 DOM 元素的结构。
劫持 console.* 等方法的实现来获取日志信息。
const levels = ['log', 'info', 'error', 'warn'];
levels.forEach((level) => {
window.console[level] = logger;
});当使用
console打印复杂的对象时,该如何处理呢?下文中的 “数据的序列化与展示” 会做说明。
JavaScript 执行过程中的错误有两类,分别监听 error 与 unhandledrejection 事件来获取错误信息。
window.addEventListener('error', reportError);
window.addEventListener('unhandledrejection', reportUnhandledrejection);与此同时,加载静态资源的错误也需要收集的。与上方代码有所区别的是,这里需要排除一下 JavaScript 运行期间的错误。
window.addEventListener(
'error',
(event) => {
// 忽略 JS 运行期间的报错
if (!(evt instanceof ErrorEvent)) {
const url = event.target.src || event.target.href;
console.error(`Failed to load ${url}`);
}
},
true,
);在浏览器端发送网络请求的有:XMLHttpRequest,fetch,window.sendBeacon,在小程序中则是 wx.request。要获取当前网页发出的网络请求,便需要劫持这几个 API,从而记录请求的耗时,Request 与 Response 等信息。
以 fetch 为例,劫持的逻辑可以简化成如下的代码:
// https://github.com/HuolalaTech/page-spy/blob/main/src/plugins/network/proxy/fetch-proxy.ts
const originFetch = window.fetch;
window.fetch = function (input: RequestInfo | URL, init: RequestInit = {}) {
const fetchInstance = originFetch(request, init);
// 获取请求的 URL, METHOD, REQUEST HEADERS 等信息
const url = retrieveUrl(input);
// ...
const startTime = Date.now();
fetchInstance.then((res) => {
const costTime = Date.now() - startTime;
// 获取 RESPONSE HEADERS 等信息
const status = res.status;
// 这里一定要使用 res.clone(),避免影响到后续在业务中的使用
const responseBody = res.clone().text();
// res.clone().json() | res.clone().blob() | res.clone().arrayBuffer()
});
return fetchInstance;
};XMLHttpRequest,navigator.sendBeacon 与 wx.request 的劫持与上述代码思路相似。不过因为运行环境的限制,有许多的 header 无法通过 API 获取。
- Accept-Charset,Accept-Encoding
- Access-Control-Request-Headers
- Access-Control-Request-Method
- Connection
- Content-Length
- ...
完整的列表参见 https://fetch.spec.whatwg.org/#forbidden-header-name
浏览器支持多种形式的存储:sessionStorage,localStorage,cookie。对于 cookie 可以使用新的 API window.cookieStorage,从而避免了手动解析 cookie,并且可以获取更多有关 cookie 的配置信息。sessionStorage 与 localStorage 都是 Storage 实例,遍历方法也是类似的。
小程序中的存储为
wx.getStorage*这一类 API。通过劫持原有的实现,即可实现。代码不再赘述。
// https://github.com/HuolalaTech/page-spy/blob/main/src/plugins/storage.ts
const cookies = await window.cookieStorage.getAll();
for (let i = 0; i < window.cookieStorage.length; i++) {
const key = window.cookieStorage.key(i);
const value = window.cookieStorage.getItem(key);
}因为部分 cookie 添加 HttpOnly 属性,通过 API 的形式并不保证可以获取到所有的 cookie。
前端开发者会经常在浏览器控制台输入代码片段并执行。PageSpy 也是支持这种功能。调试端输入的代码本质上就是字符串,将其封装成特定消息后发送到用户端并执行。在浏览器中,使用 eval 或者 new Function 都可以动态运行代码。
// https://github.com/HuolalaTech/page-spy/blob/main/src/utils/socket.ts#L282
const result = new Function(`return ${message.source.data}`);动态运行代码后的返回值复杂多变,这里需要面临下面两个问题:
- 采取何种序列化数据
- 用户端发来数据该如何展示
对于问题 1,直接使用 JSON.stringify 可能是不行。很多数据无法直接被序列化。这里可以参考 Chrome devtools 的做法:像 number,string 这类简单的数据直接转化成序列化后传输。对于一些复杂的对象,先获取的自身的属性,转化成相应的 JSON 数据再发送出去。仅当在用户点击展开后,才去查找原型链,再重复上一步的操作。
基于上面的方案,问题 2 就比较好解决了。相当于要实现一个支持懒加载的 JSONView 组件。对于组件中包含 children (支持展开) 的节点,需要给其分配一个 id,从而确保在点击之后可以找到原来在内存中的数据。在 PageSpy 的代码中使用 Atom 来记录这种对应关系。
获取对象自身的属性可以使用 Object.getOwnPropertyDescriptors,原型链查找使用 Object.getPrototypeOf。
// 获取对应自身的属性,并计算对应的值
const descriptors = Object.getOwnPropertyDescriptors(cacheData);
// 沿原型链查找,并且生成节点数据
const proto = Object.getPrototypeOf(data);
const descriptors = Object.getOwnPropertyDescriptors(proto);严格来说,还应该调用
Object.getOwnPropertySymbols获取对象的 Symbol 属性与其对应值。不过实践中,对象的 Symbol 属性使用少,暂时忽略。
复杂对象的展示的逻辑相对复杂,完整的代码可以到这里查看。
本文带领大家对 PageSpy 的核心逻辑进行了梳理。跟着本文的思路,读者可以大致搞清楚 PageSpy 这个前端远程调试工具的内在实现。实现一个远程调试工具并没有什么黑魔法,最终围绕着还是浏览器/小程序中的核心 API 来做。
自 PageSpy 上线以来,许多知名互联网企业中的开发者都已经在公司内部署该服务,实测下来,确实解决了前端开发者远程调试的烦恼。最后,对 PageSpy 感兴趣的用户不妨去我们的 Github 仓库看看 https://github.com/HuolalaTech/page-spy-web ,里面包含更详细的使用文档与贴士。
