leorick.lin leoricklin
leoricklin
/ res_adk.md
Last active
September 25, 2025 00:36
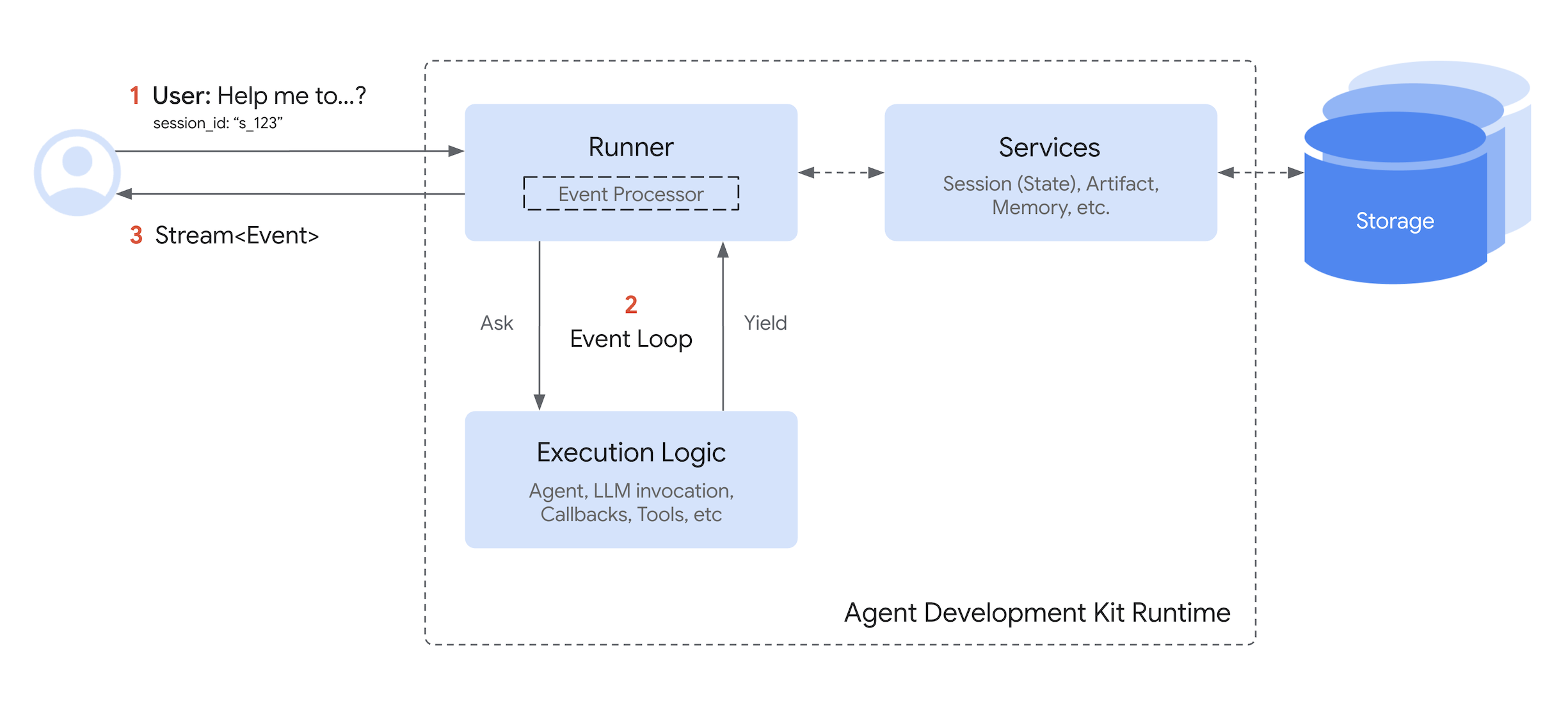
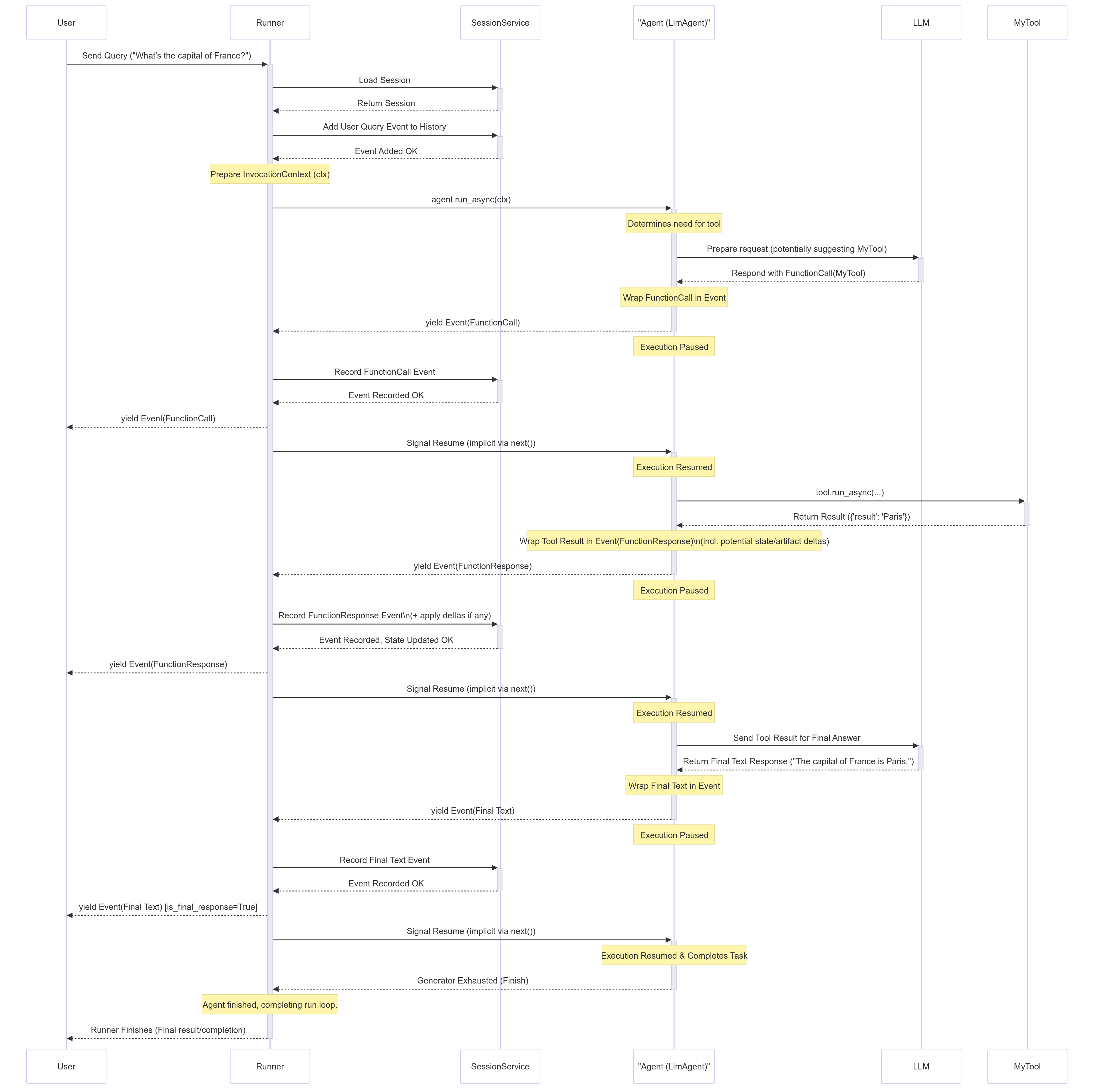
leoricklin
/ res_cn.md
Last active
January 16, 2021 14:37
-
字符串:String
-
列表:List
-
集合:Set
-
有序集合:sorted set
-
数组:array
-
字段:column
-
分区字段:partitioned column
-
实体:Entity
-
属性:Properties
leoricklin
/ res_app_arch.md
Last active
December 3, 2025 06:52
Whether you're preparing for a System Design Interview or you simply want to understand how systems work beneath the surface, we hope this repository will help you achieve that.
leoricklin
/ res_gist.md
Last active
November 24, 2020 03:12
leoricklin
/ Search my gists.md
Created
November 24, 2020 02:58
— forked from santisbon/Search my gists.md
How to search gists
Enter this in the search box along with your search terms:
Get all gists from the user santisbon.
user:santisbon
Find all gists with a .yml extension.
extension:yml
Find all gists with HTML files.
language:html
leoricklin
/ res_enterprisearchitecture.md
Last active
October 31, 2023 06:18
20170427 企业IT架构转型之道:阿里巴巴中台战略思想与架构实战 Kindle电子书, https://www.amazon.cn/dp/B071KW9F7P
20190801 中台战略:中台建设与数字商业, Kindle, https://www.amazon.cn/dp/B07WPRRTPS/
20190701 企业级业务架构设计:方法论与实践 (架构师书库, https://www.amazon.cn/dp/B07WPRRVCB
leoricklin
/ res_cloud.md
Last active
November 19, 2022 02:36
Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.
leoricklin
/ res_k8s.md
Last active
January 6, 2022 07:43
- Service endpoint (pod IP+target port) <- service (cluster IP) <- node port on all node <- (load balancer or external ip)
leoricklin
/ res_aws.md
Last active
August 28, 2022 08:38
- AWS Well-Architected, https://aws.amazon.com/architecture/well-architected/ The AWS Well-Architected Framework describes the key concepts, design principles, and architectural best practices for designing and running workloads in the cloud. By answering a set of foundational questions, you learn how well your architecture aligns with cloud best practices and are provided guidance for making improvements.
- Reference architecture, https://aws.amazon.com/solutions/reference-architectures
- 20190419 Everything You Need to Know About Big Data: From Architectural Principles to Best Practices, EN
- https://youtu.be/MotN5f6_xl8
leoricklin
/ res_spring.md
Created
November 23, 2020 10:17
- What Is Spring, https://youtu.be/Spzug_SjJnM
- 20200709 SpringOne Sessions and Workshops Now Released—Register Today!, https://tanzu.vmware.com/content/blog/springone-sessions-and-workshops-now-released-register-today