-
-
Save navyxliu/9c325d5c445899c02a0d115c6ca90a79 to your computer and use it in GitHub Desktop.
| // -Xcomp -Xms16M -Xmx16M -XX:+AlwaysPreTouch -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC -XX:-UseOnStackReplacement -XX:CompileOnly='Example1.ivanov' -XX:CompileCommand=dontinline,Example1.blackhole | |
| class Example1 { | |
| private Object _cache; | |
| public void foo(boolean cond) { | |
| Object x = new Object(); | |
| if (cond) { | |
| _cache = x; | |
| } | |
| } | |
| // Ivanov suggest to make this happen first. | |
| // we don't need to create JVMState for the cloning Allocate. | |
| public void ivanov(boolean cond) { | |
| Object x = new Object(); | |
| if (cond) { | |
| blackhole(x); | |
| } | |
| } | |
| static void blackhole(Object x) {} | |
| public void test1(boolean cond) { | |
| //foo(cond); | |
| ivanov(cond); | |
| } | |
| public static void main(String[] args) { | |
| Example1 kase = new Example1(); | |
| // Epsilon Test: | |
| // By setting the maximal heap and use EpsilonGC, let's see how long and how many iterations the program can sustain. | |
| // if PEA manages to reduce allocation rate, we expect the program to stay longer. | |
| // Roman commented it with a resonable doubt: "or your code slow down the program..." | |
| // That's why I suggest to observe iterations. It turns out not trivial because inner OOME will implode hotspot. We don't have a chance to execute the final statement... | |
| long iterations = 0; | |
| try { | |
| while (true) { | |
| kase.test1(0 == (iterations & 0xf)); | |
| iterations++; | |
| } | |
| } finally { | |
| System.err.println("Epsilon Test: " + iterations); | |
| } | |
| } | |
| } |
The is the generated code (-XX:+PrintOptoAssembly) for Example1::ivanov with DoPartialEscapeAnalysis.
please note that object allocation(B6) and initialization(B4) are both subject to
'testl RDX, RDX' on B1.
============================= C2-compiled nmethod ==============================
#r018 rsi:rsi : parm 0: Example1:NotNull *
#r016 rdx : parm 1: int
# -- Old rsp -- Framesize: 32 --
#r591 rsp+28: in_preserve
#r590 rsp+24: return address
#r589 rsp+20: in_preserve
#r588 rsp+16: saved fp register
#r587 rsp+12: pad2, stack alignment
#r586 rsp+ 8: pad2, stack alignment
#r585 rsp+ 4: Fixed slot 1
#r584 rsp+ 0: Fixed slot 0
#
----------------------- MetaData before Compile_id = 2 ------------------------
{method}
- this oop: 0x00007fbdd9000540
- method holder: synchronized 'Example1'
- constants: 0x00007fbdd9000050 constant pool [70]/operands[5] {0x00007fbdd9000050} for synchronized 'Example1' cache=0x00007fbdd9000870
- access: 0x81000001 public
- name: 'ivanov'
- signature: '(Z)V'
- max stack: 3
- max locals: 3
- size of params: 2
- method size: 14
- highest level: 3
- vtable index: 6
- i2i entry: 0x00007fbde419df00
- adapters: AHE@0x00007fbdf40d3240: 0xba i2c: 0x00007fbde42adbe0 c2i: 0x00007fbde42adc9a c2iUV: 0x00007fbde42adc68 c2iNCI: 0x00007fbde42adcd4
- compiled entry 0x00007fbddcd681e0
- code size: 17
- code start: 0x00007fbdd9000528
- code end (excl): 0x00007fbdd9000539
- method data: 0x00007fbdd9000ad0
- checked ex length: 0
- linenumber start: 0x00007fbdd9000539
- line 15: 0
- line 17: 8
- line 18: 12
- line 20: 16
- localvar length: 0
- compiled code: nmethod 122 1 3 Example1::ivanov (17 bytes)
------------------------ OptoAssembly for Compile_id = 2 -----------------------
#
# void ( Example1:NotNull *, int )
#
000 N94: # out( B1 ) <- BLOCK HEAD IS JUNK Freq: 1 IDom: 0/#1 RegPressure: 0 IHRP Index: 1 FRegPressure: 0 FHRP Index: 1
000 movl rscratch1, [j_rarg0 + oopDesc::klass_offset_in_bytes()] # compressed klass
decode_klass_not_null rscratch1, rscratch1
cmpq rax, rscratch1 # Inline cache check
jne SharedRuntime::_ic_miss_stub
nop # nops to align entry point
nop # 4 bytes pad for loops and calls
020 B1: # out( B5 (B12) B2 ) <- BLOCK HEAD IS JUNK Freq: 1 IDom: 0/#2 RegPressure: 1 IHRP Index: 10 FRegPressure: 0 FHRP Index: 10
020 # stack bang (136 bytes)
pushq rbp # Save rbp
subq rsp, #16 # Create frame
03a testl RDX, RDX
03c je,s B5 P=0.100000 C=-1.000000
03e B2: # out( B6 B3 ) <- in( B1 ) Freq: 0.9 IDom: 1/#3 RegPressure: 2 IHRP Index: 8 FRegPressure: 0 FHRP Index: 8
03e # TLS is in R15
03e movq RSI, [R15 + #264 (32-bit)] # ptr
045 movq R10, RSI # spill
048 addq R10, #16 # ptr
04c cmpq R10, [R15 + #280 (32-bit)] # raw ptr
053 jae,us B6 P=0.000100 C=-1.000000
055 B3: # out( B4 ) <- in( B2 ) Freq: 0.89991 IDom: 2/#4 RegPressure: 2 IHRP Index: 7 FRegPressure: 0 FHRP Index: 7
055 movq [R15 + #264 (32-bit)], R10 # ptr
05c PREFETCHNTA [R10 + #192 (32-bit)] # Prefetch allocation to non-temporal cache for write
064 movq [RSI], #1 # long
06b movl [RSI + #8 (8-bit)], narrowklass: precise java/lang/Object: 0x00007fbdb000fd90:Constant:exact * # compressed klass ptr
072 movl [RSI + #12 (8-bit)], R12 # int (R12_heapbase==0)
076 B4: # out( B9 B5 (B11) ) <- in( B7 B3 ) Freq: 0.9 IDom: 2/#4 RegPressure: 12 IHRP Index: 19 FRegPressure: 32 FHRP Index: 12
076
076 MEMBAR-storestore (empty encoding)
076 # checkcastPP of RSI
nop # 1 bytes pad for loops and calls
077 call,static Example1::blackhole
# Example1::ivanov @ bci:13 (line 18) L[0]=_ L[1]=_ L[2]=_
# OopMap {off=124/0x7c}
07c B5: # out( N94 ) <- in( B4 (B11) B1 (B12) ) Freq: 0.999982 IDom: 1/#3 RegPressure: 0 IHRP Index: 4 FRegPressure: 0 FHRP Index: 4
07c addq rsp, 16 # Destroy frame
popq rbp
cmpq rsp, poll_offset[r15_thread]
ja #safepoint_stub # Safepoint: poll for GC
08e ret
08f B6: # out( B8 B7 ) <- in( B2 ) Freq: 9.00149e-05 IDom: 2/#4 RegPressure: 12 IHRP Index: 10 FRegPressure: 32 FHRP Index: 2
08f movq RSI, precise java/lang/Object: 0x00007fbdb000fd90:Constant:exact * # ptr
nop # 2 bytes pad for loops and calls
09b call,static wrapper for: _new_instance_Java
# Example1::ivanov @ bci:13 (line 18) L[0]=_ L[1]=_ L[2]=_
# OopMap {off=160/0xa0}
0a0 B7: # out( B4 ) <- in( B6 ) Freq: 9.00131e-05 IDom: 6/#5 RegPressure: 1 IHRP Index: 3 FRegPressure: 0 FHRP Index: 3
# Block is sole successor of call
0a0 movq RSI, RAX # spill
0a3 jmp,s B4
0a5 B8: # out( B10 ) <- in( B6 ) Freq: 9.00149e-10 IDom: 6/#5 RegPressure: 1 IHRP Index: 4 FRegPressure: 0 FHRP Index: 4
0a5 # exception oop is in rax; no code emitted
0a5 movq RSI, RAX # spill
0a8 jmp,s B10
0aa B9: # out( B10 ) <- in( B4 ) Freq: 9e-06 IDom: 4/#5 RegPressure: 1 IHRP Index: 4 FRegPressure: 0 FHRP Index: 4
0aa # exception oop is in rax; no code emitted
0aa movq RSI, RAX # spill
0ad B10: # out( N94 ) <- in( B9 B8 ) Freq: 9.0009e-06 IDom: 2/#4 RegPressure: 1 IHRP Index: 7 FRegPressure: 0 FHRP Index: 7
0ad addq rsp, 16 # Destroy frame
popq rbp
0b2 jmp rethrow_stub
0b7 B11: # out( B5 ) <- in( B4 ) Freq: 0.899982 IDom: 4/#5 RegPressure: 0 IHRP Index: 2 FRegPressure: 0 FHRP Index: 2
# Empty connector block
0b7 B12: # out( B5 ) <- in( B1 ) Freq: 0.1 IDom: 1/#3 RegPressure: 0 IHRP Index: 2 FRegPressure: 0 FHRP Index: 2
# Empty connector block
--------------------------------------------------------------------------------
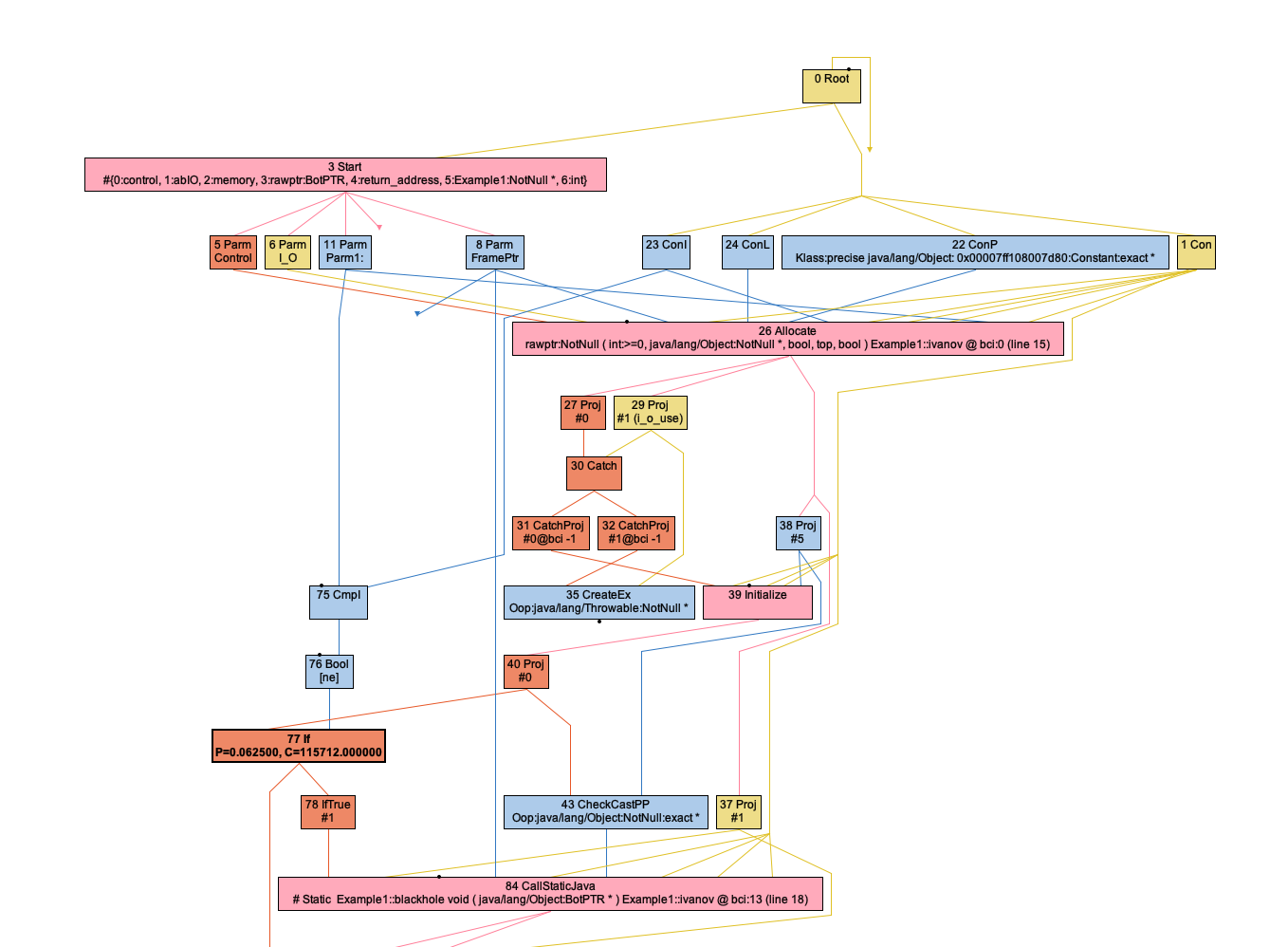
This the IR after parse, without PEA.
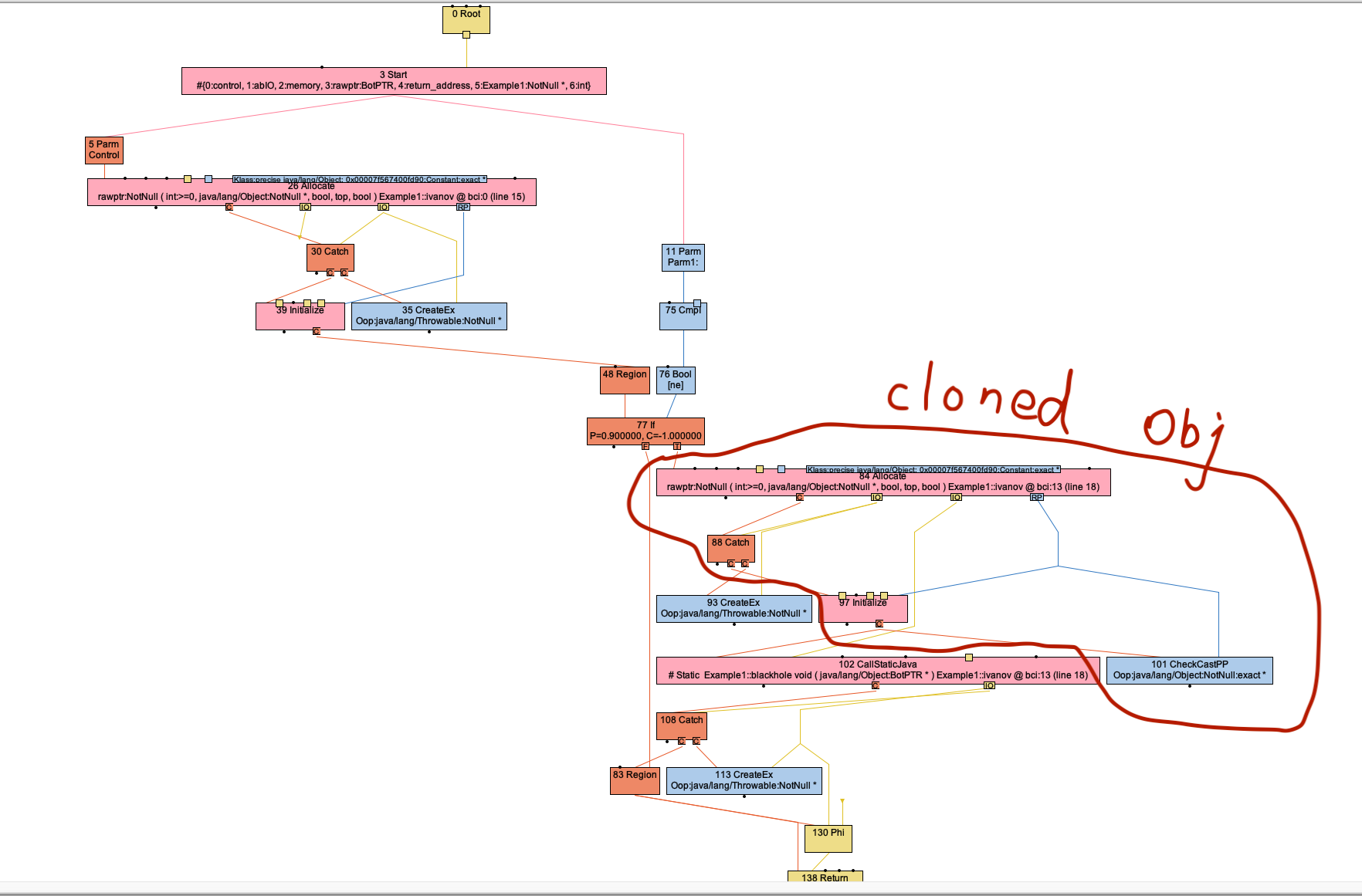
Here is the IR after parse with PEA. Please note that we clone the object. It's a cluster of nodes. 101 CheckCastPP is the argument of 102 CallStaticJava/Example1::blackhole. It's hid by the filter 'Simplify graph' of IGV.
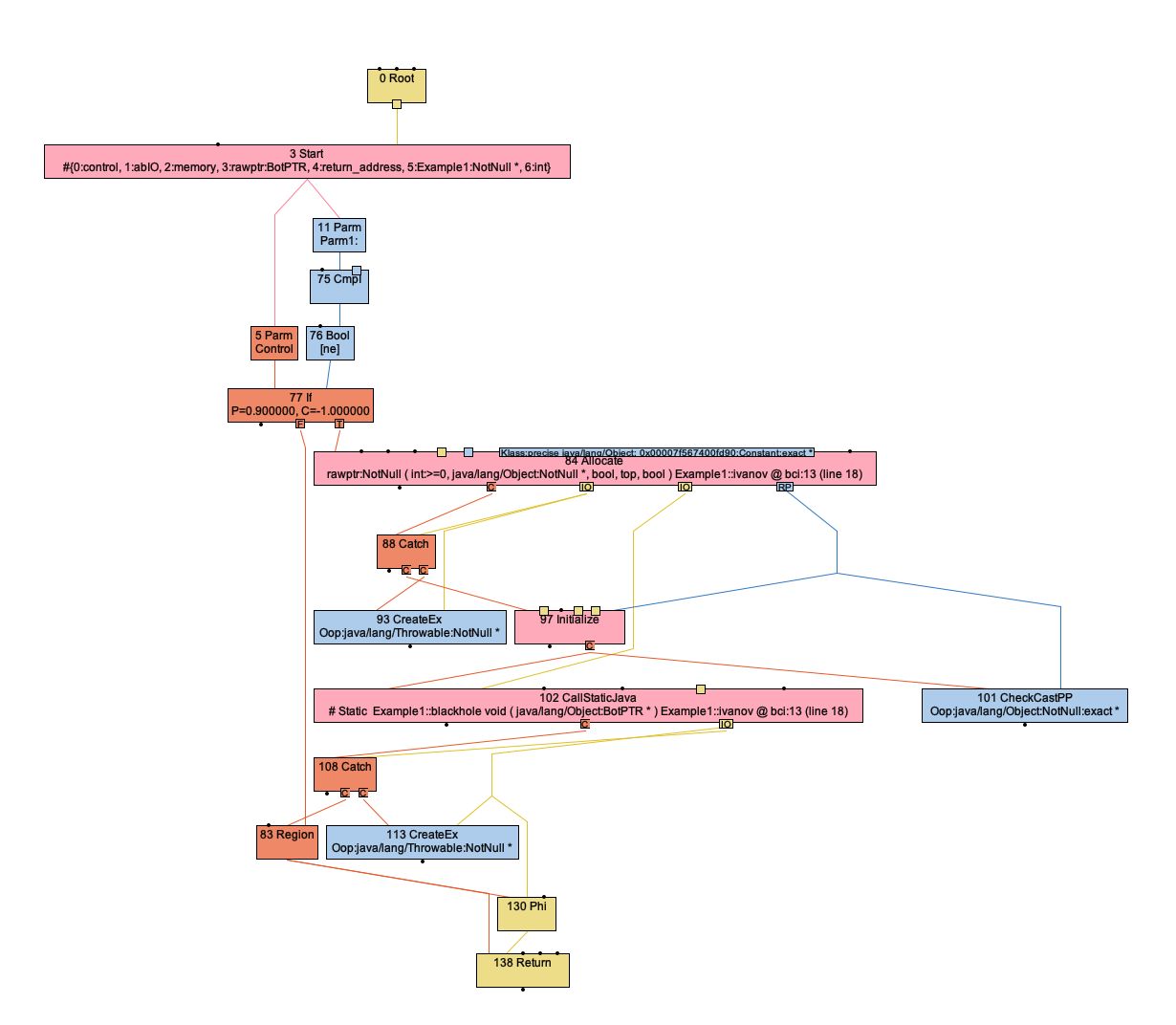
Even though it looks like we leave behind a redundancy, C2 EA/SR will eliminate the obsolete 26 Allocate! Here is the IR after Iterative EA. It is as if our PEA optimization moves the object under IfTrue.
the source code of my experimental PEA: https://github.com/navyxliu/jdk/tree/PEA_parser
I believe that JMH has prof:gc to acquire the allocation rate per iteration, maybe you can somehow use it for allocation rate of PEA. Thanks.
I believe that JMH has
prof:gcto acquire the allocation rate per iteration, maybe you can somehow use it for allocation rate of PEA. Thanks.
yes, I will convert this to a JMH. thanks!
This is a developing story.
if you are still interested, please follow it up -> Example2
The following code creates a phi node to merge 2 objects.
I believe RAM of JDK-8289943 can make the NonEscape object be replace in
public Object merge_node(boolean cond) {
Object x = new Object();
if (cond) {
_cache = x;
}
return x;
}
The most obvious result is that program with PEA sustain longer. With 16M heap, it sustains 2.5s while the original program only stays 0.279s.
this change amounts to change source to