-
-
Save nikhilweee/24cae428f68c153afda495dc17ef43d6 to your computer and use it in GitHub Desktop.
| # This script is designed to convert bank statements from pdf to excel. | |
| # | |
| # It has been tweaked on HDFC Bank Credit Card statements, | |
| # but in theory you can use it on any PDF document. | |
| # | |
| # The script depends on camelot-py, | |
| # which can be installed using pip | |
| # | |
| # pip install "camelot-py[cv]" | |
| import os | |
| import argparse | |
| import camelot | |
| import pandas as pd | |
| from collections import defaultdict | |
| def extract_df(path, password=None): | |
| # The default values from pdfminer are M = 2.0, W = 0.1 and L = 0.5 | |
| laparams = {'char_margin': 2.0, 'word_margin': 0.2, 'line_margin': 1.0} | |
| # Extract all tables using the lattice algorithm | |
| lattice_tables = camelot.read_pdf(path, password=password, | |
| pages='all', flavor='lattice', line_scale=50, layout_kwargs=laparams) | |
| # Extract bounding boxes | |
| regions = defaultdict(list) | |
| for table in lattice_tables: | |
| bbox = [table._bbox[i] for i in [0, 3, 2, 1]] | |
| regions[table.page].append(bbox) | |
| df = pd.DataFrame() | |
| # Extract tables using the stream algorithm | |
| for page, boxes in regions.items(): | |
| areas = [','.join([str(int(x)) for x in box]) for box in boxes] | |
| stream_tables = camelot.read_pdf(path, password=password, pages=str(page), | |
| flavor='stream', table_areas=areas, row_tol=5, layout_kwargs=laparams) | |
| dataframes = [table.df for table in stream_tables] | |
| dataframes = pd.concat(dataframes) | |
| df = df.append(dataframes) | |
| return df | |
| def main(args): | |
| for file_name in os.listdir(args.in_dir): | |
| root, ext = os.path.splitext(file_name) | |
| if ext.lower() != '.pdf': | |
| continue | |
| pdf_path = os.path.join(args.in_dir, file_name) | |
| print(f'Processing: {pdf_path}') | |
| df = extract_df(pdf_path, args.password) | |
| excel_name = root + '.xlsx' | |
| excel_path = os.path.join(args.out_dir, excel_name) | |
| df.to_excel(excel_path) | |
| print(f'Processed : {excel_path}') | |
| if __name__ == '__main__': | |
| parser = argparse.ArgumentParser() | |
| parser.add_argument('--in-dir', type=str, required=True, help='directory to read statement PDFs from.') | |
| parser.add_argument('--out-dir', type=str, required=True, help='directory to store statement XLSX to.') | |
| parser.add_argument('--password', type=str, default=None, help='password for the statement PDF.') | |
| args = parser.parse_args() | |
| main(args) |
@nikhilweee same error about min() arg in my system too on a Windows machine.
Have you been able to find a solution?
@pushkaryadav good to know an accountant automating mundane stuff, what other solutions have you tried?
You can use Tabula to extract from PDF and also for HDFC CC, get a YESS statement from bank which consolidates all of your CC statements and easier for accounting
@pushkaryadav
thanks on sharing the excel codes..can you change the excel formula for Cell E2 (For Narration/Description)
Its the same as for date
@malharlakdawala
Updated the formula.
These formulas were supposed to be temporary but fortunately they are still working after 6 months and I am yet to see an error/incorrect output. If I ever change the formula, aka make the formulas more flexible I'll share them here.
One good example of making the sheet better is in the formula of B2. Instead of looking for the " cr" in the whole sentence, I should rather look for " cr" using the RIGHT function.
Alternative formula for cell B2
=NOT(RIGHT($A2,3)=" Cr")
Regards.
@sethia
Thank you for the suggestion but IIRC, I did try tabula or something similar, it was too much work and didn't really work. My current setup is much easier and user friendly, at least for me.
So currently, I have no need to look for further options.
Bank statement is already being updated daily since it is a necessity. So a combined statement won't help much as I'll have to get in touch with the bank once again and they are not working at their full potential for many months now. It took multiple reminder phone calls and three weeks just to switch our banking e-statement from monthly to daily.
Thanks for this @nikhilweee
For windows, I modified the code as below and ran it on Jupyter. I just directly mentioned the filepaths in the code, instead of feeding through the function, which was causing the issues. You can change the actual paths as per your own system. I used a sample folder on the desktop to check if this works. Thanks @nikhilweee :)
import os
import argparse
import camelot
import pandas as pd
from collections import defaultdict
def extract_df(path, password=None):
# The default values from pdfminer are M = 2.0, W = 0.1 and L = 0.5
laparams = {'char_margin': 2.0, 'word_margin': 0.2, 'line_margin': 1.0}
# Extract all tables using the lattice algorithm
lattice_tables = camelot.read_pdf(path, password=password,
pages='all', flavor='lattice', line_scale=50, layout_kwargs=laparams)
# Extract bounding boxes
regions = defaultdict(list)
for table in lattice_tables:
bbox = [table._bbox[i] for i in [0, 3, 2, 1]]
regions[table.page].append(bbox)
df = pd.DataFrame()
# Extract tables using the stream algorithm
for page, boxes in regions.items():
areas = [','.join([str(int(x)) for x in box]) for box in boxes]
stream_tables = camelot.read_pdf(path, password=password, pages=str(page),
flavor='stream', table_areas=areas, row_tol=5, layout_kwargs=laparams)
dataframes = [table.df for table in stream_tables]
dataframes = pd.concat(dataframes)
df = df.append(dataframes)
return df
pdf_path = 'C:\\Users\\<Your_name>\\Desktop\\HDFCCredit\\HDFCJan.PDF'
print(f'Processing: {pdf_path}')
df = extract_df(pdf_path)
excel_name = 'export.xlsx'
excel_path = 'C:\\Users\\<Your_name>\\Desktop\\HDFCCredit\\export.xlsx'
df.to_excel(excel_path)
print(f'Processed : {excel_path}')
@cstambay glad that I could be of help :)
I had to install Ghostscript along with camelot-py[cv] after that it worked perfectly fine - Thank you @nikhilweee
@simplyrahul I got the same error
ValueError: min() arg is an empty sequence
in my Windows system. After some debugging, I found a fix by changing the _text_bbox(t_bbox) method in camelot-py's file 'stream.py' as below. It works for me now. Hope it helps.
`
def _text_bbox(t_bbox):
"""Returns bounding box for the text present on a page.
Parameters
----------
t_bbox : dict
Dict with two keys 'horizontal' and 'vertical' with lists of
LTTextLineHorizontals and LTTextLineVerticals respectively.
Returns
-------
text_bbox : tuple
Tuple (x0, y0, x1, y1) in pdf coordinate space.
"""
xmin = 0
ymin = 0
xmax = 0
ymax = 0
if len([t.x0 for direction in t_bbox for t in t_bbox[direction]])>0:
xmin = min([t.x0 for direction in t_bbox for t in t_bbox[direction]])
ymin = min([t.y0 for direction in t_bbox for t in t_bbox[direction]])
xmax = max([t.x1 for direction in t_bbox for t in t_bbox[direction]])
ymax = max([t.y1 for direction in t_bbox for t in t_bbox[direction]])
text_bbox = (xmin, ymin, xmax, ymax)
return text_bbox
`
Thanks a lot, @nikhilweee for this! Been using it from the last three years.
While running on a new system, got the following error:
PyPDF2.errors.DeprecationError: PdfFileReader is deprecated and was removed in PyPDF2 3.0.0. Use PdfReader insteadRefer camelot-dev/camelot#339
What worked for me
python3.8 -m pip uninstall PyPDF2
python3.8 -m pip install PyPDF2~=2.0The code is not working, kindly check...
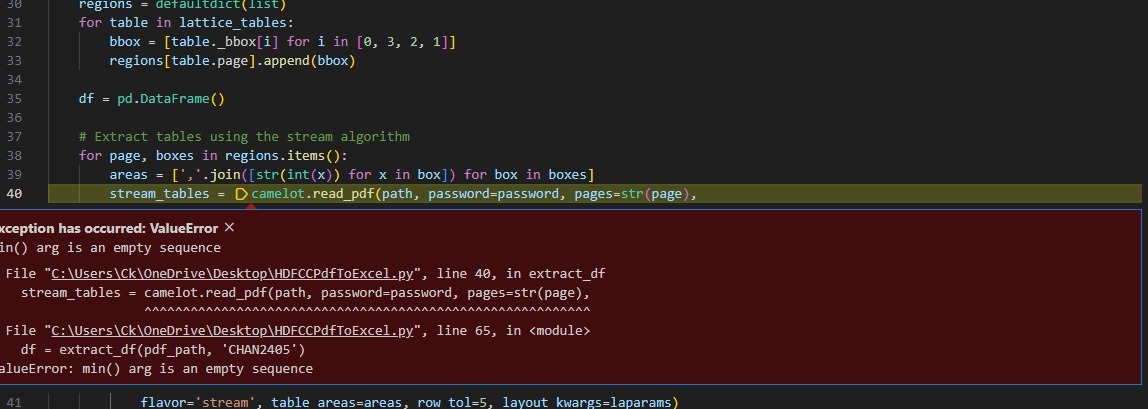
Looks like the method append has been removed from the pandas module a long time ago
$ python3 ~/scripts/statement-to-excel.py --in-dir . --out-dir .
Processing: ./2024-04.PDF
Traceback (most recent call last):
File "/Users/nowalekar/scripts/statement-to-excel.py", line 68, in <module>
main(args)
File "/Users/nowalekar/scripts/statement-to-excel.py", line 54, in main
df = extract_df(pdf_path, args.password)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/nowalekar/scripts/statement-to-excel.py", line 42, in extract_df
df = df.append(dataframes)
^^^^^^^^^
File "/Users/nowalekar/scripts/hdfc-cc-statement/lib/python3.12/site-packages/pandas/core/generic.py", line 6299, in __getattr__
return object.__getattribute__(self, name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'DataFrame' object has no attribute 'append'. Did you mean: '_append'?
Fix on line #42:
df = pd.concat([df, dataframes])
Hello Nikhil, I'm amateur user of mint linux. recently moved from Windows. I was looking for this code for long time as I wanted to move all my HDFC credit card transaction moved to moneymanager for tracking my expense. Tried running your code from the command promont however I got below error. Appreciate any guidance on the same
python3 /home/vivek/Downloads/HDFC_St/statement-to-excel.py --in-dir /home/vivek/Documents/Statements --out-dir /home/vivek/Documents/Excels --password V%$&*Ghe
/home/vivek/.local/lib/python3.10/site-packages/pypdf/_crypt_providers/_cryptography.py:32: CryptographyDeprecationWarning: ARC4 has been moved to cryptography.hazmat.decrepit.ciphers.algorithms.ARC4 and will be removed from cryptography.hazmat.primitives.ciphers.algorithms in 48.0.0.
from cryptography.hazmat.primitives.ciphers.algorithms import AES, ARC4
Processing: /home/vivek/Documents/Statements/April2025.PDF
Traceback (most recent call last):
File "/home/vivek/Downloads/HDFC_St/statement-to-excel.py", line 68, in
main(args)
File "/home/vivek/Downloads/HDFC_St/statement-to-excel.py", line 54, in main
df = extract_df(pdf_path, args.password)
File "/home/vivek/Downloads/HDFC_St/statement-to-excel.py", line 38, in extract_df
stream_tables = camelot.read_pdf(path, password=password, pages=str(page),
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/io.py", line 134, in read_pdf
tables = p.parse(
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/handlers.py", line 257, in parse
t = self._parse_page(
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/handlers.py", line 301, in _parse_page
tables = parser.extract_tables()
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/parsers/base.py", line 238, in extract_tables
cols, rows, v_s, h_s = self._generate_columns_and_rows(bbox, user_cols)
File "/home/vivek/.local/lib/python3.10/site-packages/camelot/parsers/stream.py", line 135, in _generate_columns_and_rows
text_x_min, text_y_min, text_x_max, text_y_max = bbox_from_textlines(
TypeError: cannot unpack non-iterable NoneType object
UPDATE: Replaced the formula for Narration.
@simplyrahul
yeah but like I said in my last reply. you can use the windows software named, A-PDF RESTRICTION REMOVER (a-pdf.com) to remove the copy-protection (SECURED) settings from the PDF and then you can manually copy the data into excel, but there's still a small issue that the data is copied into just one column.
To solve that issue, that is, to differentiate DATE, DESCRIPTION and Credit/Debit Amount, I have made a small excel file and with the help of few basic formulas, my excel does the work in a second.
Pasting the formulas I'm using below, assuming data is copied into A2 and below.
Cell B2
=ISERROR(SEARCH(" cr",$A2,LEN($A2)-3))Cell C2
=TRIM(RIGHT(SUBSTITUTE(SUBSTITUTE(A2," Cr","")," ",REPT(" ",255)),255))Cell D2 (For Date)
=DATE(MID($A2,7,4),MID($A2,4,2),LEFT($A2,2))Cell E2 (For Narration/Description)
=MID($A2,12,IF($B2,LEN($A2)-LEN($C2)-12,LEN($A2)-LEN($C2)-12-3))Cell F2 (For Purchase transactions)
=NUMBERVALUE(IF($B2,$C2,0))Cell G2 (For Payment transactions)
=NUMBERVALUE(IF($B2,0,$C2))Hope this helps.
Pushkar