九章は前回に終わらなかった分を軽く取り上げる。
{lazy,segmented}-binary-numbersを使って、inc/decをO(1)で実行する方法を見てきた:
- 三番目の方法を紹介: skew-binary-numbers
- 通常は、より簡潔かつ効率的だが、普通の二進数からはよりradicalに離れることになる
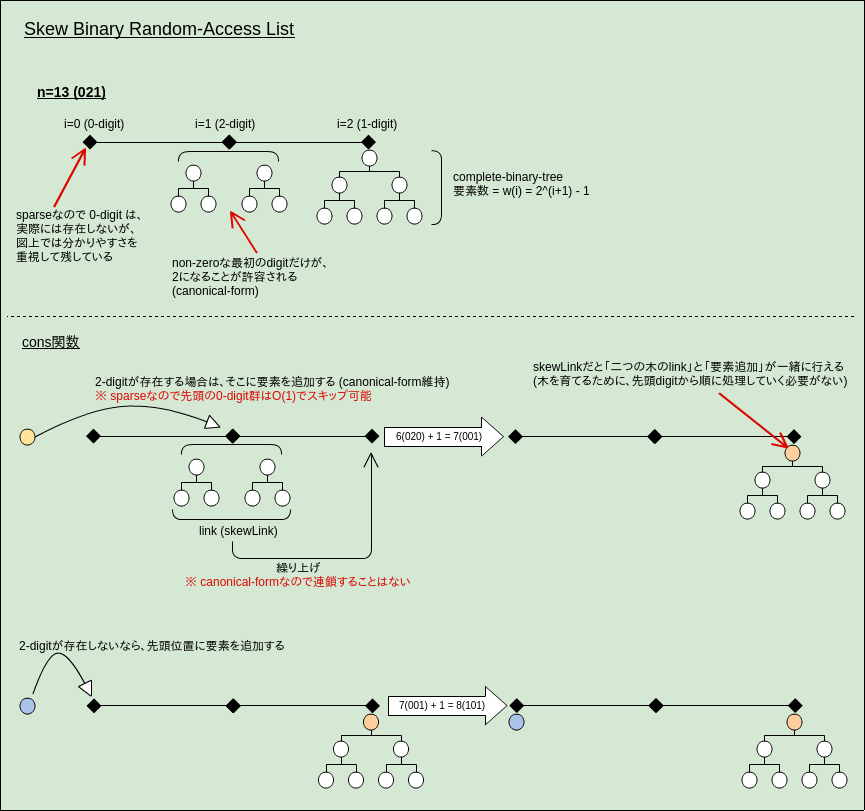
skew-binary-numbers:
- w(i):
2^(i+1) - 1(!2^iではない) - D(i):
{0,1,2}- e.g. 92 = 002101
- この数値システムは冗長:
- 制限を加えることで冗長ではなくなる
- 「zeroを除いた最下位digitのみがtwoになり得る」 (正規表現:
0*2?[01]*) - このような数はcanonical-formと呼ばれる (以後はこれのみを仮定)
- 定理9.1: 全ての自然数はcanonical-formのskew-binary-numbersで一意に表現可能
skew-binary-numbersを使ったランダムアクセスリストの実装:
- 詳細は図を参照
- 構成:
- digit列はsparseで保持 (head/tail/consを
O(1)にするため) - 木には、
- complete-binary-tree を使用 (要素数がweightと一致するため)
- left-to-rightなpreorderで木に要素を保持 (headの
O(1)にするため)
- digit列はsparseで保持 (head/tail/consを
- 最悪計算量:
- head/tail/cons:
O(1) - lookup/update:
O(log n)
- head/tail/cons:
- 実践者へのヒント: リストと配列の両方の性質が欲しいなら、この実装は良い選択
概要と計算量だけ列挙:
- skew-binary-numbersとordinary-binary-numbersを組み合わせることで効率的なヒープ実装が可能
- increment(insert)には前者の特性を利用
- addition(merge)には後者の特性を利用 (skewはmergeがawkward)
- 最悪計算量:
- insertは
O(1), findMin/deleteMin/mergeはO(log n) - 10.2.2では、mergeを
O(1)にする
- insertは
ブートストラッピング:
- ある問題の解法が、同じ問題(のより簡単なインスタンス)を解くことを要求するような状況
- e.g. OSの起動、コンパイル対象の言語自身で実装されたコンパイラ
- 最小単位だけは特別な方法で用意して、それを(再帰的に)組み合わせて徐々に大きくしていき、最終的な目的を達成する
本章ではdata-structural-bootstrappingと呼ばれるアルゴリズムのデザインテクニックを三つ紹介する:
-
- structural-decomposition
- 不完全なデータ構造から完全なデータ構造をブートストラップする
-
- structural-abstraction
- 非効率なデータ構造から効率的なデータ構造をブートストラップする
-
- bootstrapping-to-aggregate-types
- アトミック要素用のデータ構造からaggregate要素用のデータ構造をブートストラップする
- 不完全なデータ構造から完全なデータ構造をブートストラップするためのテクニック
- 典型的には「サイズに上限(perhaps even zero)があるオブジェクト」を使って、上限がないものに拡張する
- e.g. リストの定義:
datatype a List = NIL | CONS of a * a List - 上の例はいくつかの点で structural-decomposition のインスタンスと見做すことができる
- bounded-sizeのオブジェクト(NIL)がある
- 大きなオブジェクトもdecomposeしていけば、最終的にbounded-sizeなケースで扱うことが可能
- この例は定義内の再帰的なコンポーネント(
a List)が、定義された型に等しいのでシンプル- __uniformaly-recursive__と呼ばれる
- e.g. リストの定義:
- 一般的には、structural-decompositionは__non-uniform__な再帰データ型のために予約されている
- e.g. 列の定義:
datatype a Seq = NIL' | CONS' of a * (a * a) Seq- NOTE: 列のサイズは
2^k-1に限定
- NOTE: 列のサイズは
- 再帰コンポーネントは
(a * a) Seqとなっており、もともとの定義であるa Seqとは異なる
- e.g. 列の定義:
不幸なことに、SMLでstructurl-decompositionを直接実装することは不可能:
- non-uniformな型を定義することはできるが、型システムはその興味深い使い方の大半を許可しない
- e.g. 10.1のsizeS関数(一部):
fun sizeS (CONS' (x, ps)) = 1 + 2 * sizeS ps- 再帰する度に型が変わるので怒られる
a sizeS => (a * a) sizeS => ((a * a) * (a * a)) sizeS => ...
- e.g. 10.1のsizeS関数(一部):
- non-uniformをuniformに機械的に変換することは常に可能:
- e.g. Seqのuniform版: non-unformになっていた部分を
EQとして切り出すdatatype a EP = ELEM of a | PAIR of a EP * a EPdatatype a Seq = NIL' | CONS' of a EP * a Seq
- structural-decompositionは、データ型に対する視点の問題
- e.g. Seqは「木のリスト(uniform)」とも「(倍々に増える)ペアの列(non-uniform)」とも見なせる
- どちらがより適切(or 自然)かは、適用対象の問題に依存する
- e.g. Seqのuniform版: non-unformになっていた部分を
- non-uniformな実装を優先する現実的ないくつかの理由がある:
-
- より簡潔 (型定義がひとつ減る)
-
- 言語実装によるが、おそらくより効率的
- 型コンストラクタ(上の例なら
EPのそれ)に対するパターンマッチが不要 - タグの情報(e.g.
ELEM | PAIR)をメモリに持つ必要もない
-
- プログラムエラーを型システムが検出可能(一番重要):
- non-uniformのSeqなら、以下をコンパイラが保証
- バランスしているか
- 各ネストでレベルが一つずつ深くなるか:
pair => pair of pair => ...
- uniformの場合は、これらの制約(不変項)をプログラマが担保する必要がある
- プログラマがうっかり間違っても型システムは助けてくれない
-
本書ではSMLがnon-uniformal(a.k.a. polymorphic-recursion)をサポートしているかのように記述する
a Seqは列を表現するには不適切:
- 要素数が
2^k - 1に限定されるため - 9章の数値表現が利用可能:
datatype a Seq = NIL | ZERO of (a * a) Seq | ONE of a * (a * a) Seq- 0..10の列は
ONE(0, ONE((1,2), ZERO, (ONE((((3,4),(5,6)),(7,8),(9,10))), NIL))) - ペアは完全にバランスしている => complete-binary-leaf-treeと同じ構造
- 9.2.1のバイナリランダムアクセスリストと本質的には同等の構造
- ただし、構造の不変項がマニュフェストとなった (! 重要)
バイナリランダムアクセスリストの関数を再実装する:
- 「complete-binary-leaf-treeのリスト」ではなく「要素とペアの列」と考える
- 各関数の計算量は変わらない(
O(log n))けど、より短く理解が容易- cons/tail/headの
O(1)も達成可能 (演習10.2: zerolessやlazyを使う)
- cons/tail/headの
(* cons関数だけ抜粋 *)
fun cons (x, NIL) = ONE (x, NIL)
| cons (x, ZERO ps) = ONE (x, ps)
| cons (x, ONE (y, ps)) = ZERO (cons ((x y), ps)) (* polymorphic recursion *)! 軽く流す
6.3.2の銀行員のキューを考える:
- ローテート時の結合処理は無駄では?
((f ++ reverse r1) ++ reverse r2) ++ ... ++ reverse rk- 前半部分が何度も結合対象になる
- サイズが倍々になるので償却はされる
- ただし、オーダーは同じでも、現実的にはこれによって若干遅くなる可能性がある
- この非効率性をstructural-decompositionを使って除去する
実装:
- 図で軽く説明
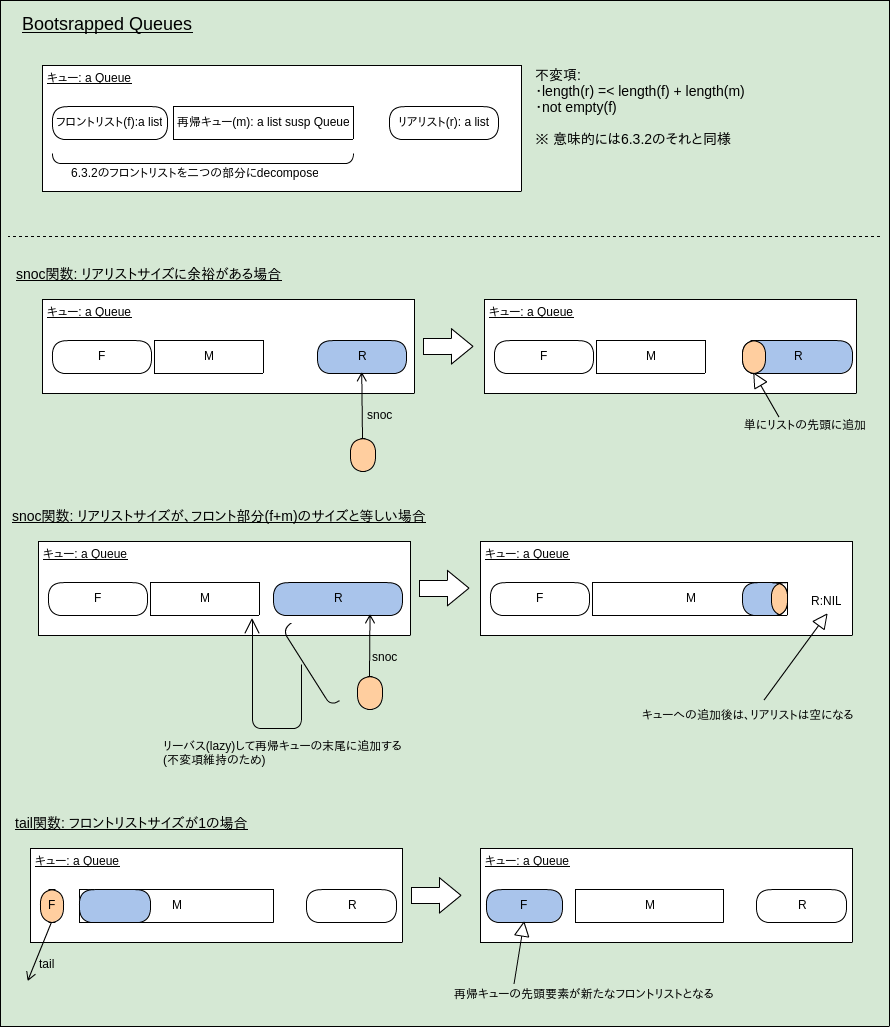
計算量:
- headは最悪
O(1) - snoc/tailは償却
O(log* n)mへの再帰呼出しが連鎖する可能性があるため- ただし現実的には償却
O(1)と考えて問題がないlog* n = 5ならn=2^65536となるため (remark参照)
- 計算量の証明などは省略
- 実践者へのヒント: 永続性をsparinglyに使うなら最も速い実装として知られている
- 非効率なデータ構造から効率的なデータ構造をブートストラップするテクニック
- 典型的には、コレクションを効率的なjoinが実行可能なように拡張するために使用される
- NOTE: joinの対応物は、リストならappend、ヒープならmerge
- 効率的なinsertをデザインするのは容易だけど、joinは難しい
- insertを使ってjoinを実現すれば良い
- 他のコレクションを要素とするコレクションを作成し、join時は後者へのinsertとして実装
具体的には:
- 効率的な挿入関数を備えたコレクション型(primitive-typeと呼称)があるとする
Prim.insert(x, xs)
- 効率的なinsert/joinを備えた型(bootstrapped-typeと呼称)を導き出す
Boot.insert(x, xs) = Boot.join(single x, xs)Boot.join(xs, ys) = Prim.insert(xs, ys)(!Prim.insertを利用しているのが重要)
- 上のテンプレートの亜種を作るのは簡単
- e.g. 要素比較を入れれば、ヒープが作れる
- ただし、deleteは若干難しいこともある (後続の例を参照)
最初の例として連結可能リストを実装する:
- シグネチャは図10.3:
head/tail/cons/snoc/++- output-restricted-dequeとも見なせる
- 全操作で
O(1)償却時間を目指す
実装:
- 型:
datatype a Cat = E | C of a * a Cat susp Q.QueueQ.Queueは、a Catを要素に持つprimitive-typeなキューQの実装は、永続対応の定数時間キューなら何でも可 (最悪 or 償却)Q.snoc(insert)を使って、O(1)の++(join)を実現する
- 詳細は図を参照
- 補足:
- cons/snocは、
++を使って実装可能:cons = [x] ++ xs, snoc = xs ++ [x] - tailは最悪
O(n)(for linkAll):- linkAll関数の各呼び出しを遅延させて、償却
O(1)にする
- linkAll関数の各呼び出しを遅延させて、償却
- cons/snocは、
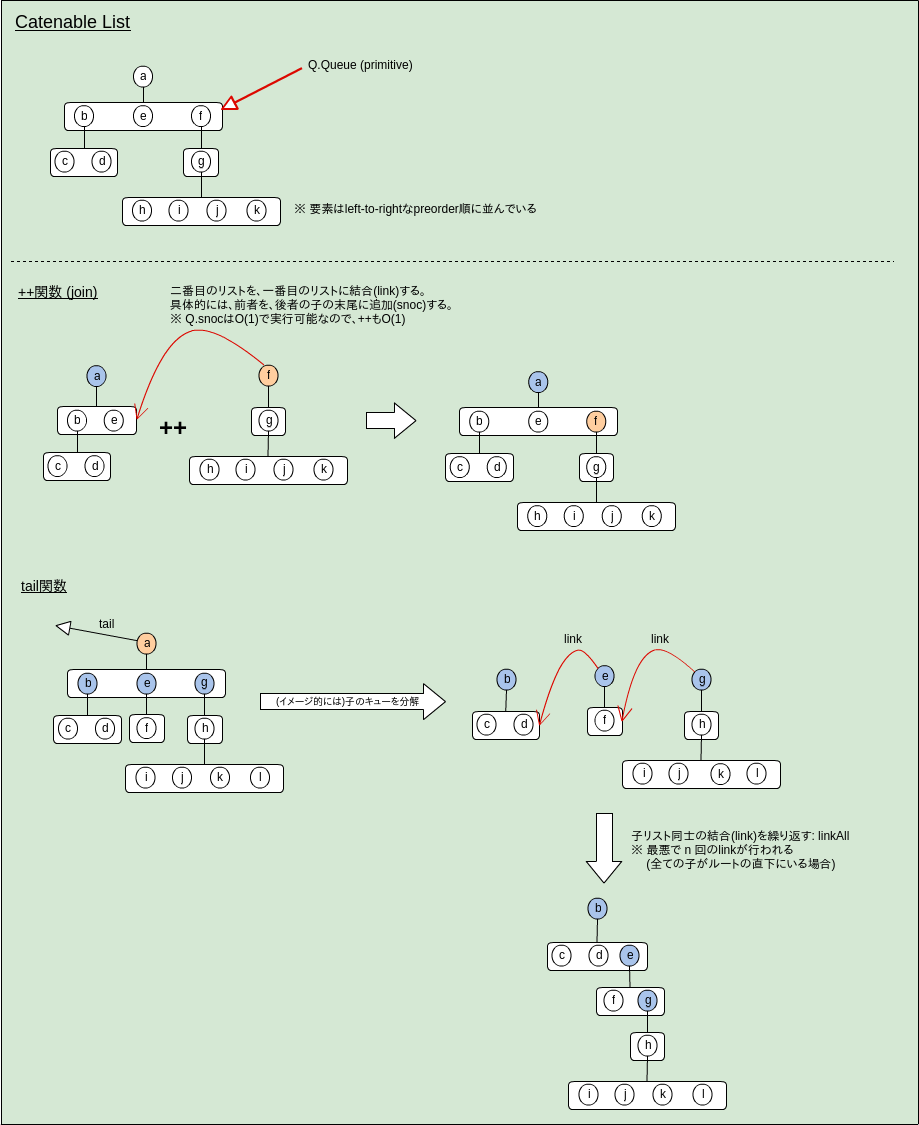
計算量に関して:
- headが最悪
O(1)なのは自明 - tail/cons/snoc/++が償却
O(1)なのは、銀行員の手法を使って証明する(! 省略) - 実践者へのヒント: 永続性をヘビーに使う連結可能リストの実装としては、これが最速として知られている
次の例はマージが効率的に行えるヒープの開発:
- ! そこまで新しい知見は出てこないので省略 (基本的な流れは10.2.1と同様)
これまで:
- aggregate-dataのコレクションを使って、non-aggregate-dataのコレクションを実装する例を見てきた
- e.g. heaps-of-heapsを使ってheaps-of-elementsを実装
しかしながら、aggregate-dataのコレクションは、それ自体で有用:
- e.g. strings(i.e. sequences-of-characters)は、setの要素の型や、mapのキーの型としてよく使われる
- この節では、
- some-simple-type(e.g. char)をキーとするfinite-mapを、listやtreeをキーとするfinite-mapにブートストラップする
- e.g. 「charをキーとするmap」を使って、「stringをキーとするmap(実際にはtrie)」を実装する (10.3.1)
- 10.3.2ではそれを汎用化し、任意のaggreate型のキーが利用可能なようにする
- some-simple-type(e.g. char)をキーとするfinite-mapを、listやtreeをキーとするfinite-mapにブートストラップする
トライの話:
- ! トライの基本的な説明は省略 (必要なら口頭で補足)
- 二分探索木はキーの比較が安価(e.g. integer)なら良いが、長い文字列とかならトライの方が良いかも
- トライならaggregate-typeの型の特徴を活かせる (e.g. キー内の要素の比較回数が最小限にできる)
- 図10.9の
FINITESTATEMAP抽象を実装するためにトライを使用: empty/lookup/bind関数を実装 - キーにはstring(list of charactersで表現)を仮定
characterのようなedge-labelを表現する型はbase-typeと呼称listやcharacterの部分の実装を、他の型へ置き換えるのは容易
トライの表現方法:
- 値の有無(valid or invalid)はオプションで表現:
datatype a option = NONE | SOME of a(組み込み型)
- エッジをどう表現するか?
- いろいろな選択肢があり得る: 例えば「連想リスト」、「配列」、「二分探索木」、etc
- 全てが
edge-label => triesへのfinite-mapだというのは共通している - 特定の表現から離れて
Mというbase-typeをキーとしたfinite-mapがあるものとする
- 最終的な型:
datatype a Map = TRIE of a option * a Map M.Map- empty/lookup/bindの実装は自明 (トライを実装したことがある人なら)
(* lookup関数の実装だけ抜粋 *)
fun lookup ([], TRIE (NOE, m)) = raise NOTFOUND
| lookup ([], TRIE (SOME x, m)) = x
| lookup (k :: ks, TRIE (v, m)) = lookup (ks, M.lookup (k, m))! 軽く流す
前節ではトライのキーとしてstringを扱ったが、他のaggregate-type(e.g. trees)のキーに汎用化が可能:
- いくつかの単純なルールのみが必要:
- キーの型を、どう(base-typeの)マップに対応させるか
- ルール: product/sum
- キーの型はproductとsumの部分に分解でき、それぞれがトライの型の異なる部分に対応する
- sum: (本では
+と表記)- キーの型の
|部分:datatype Hoge = A | B | ... - 各構築子は、トライの型の各フィールドに対応
- キーの要素の種類に対応する、ノード内のデータはどれか
- e.g. リストの場合:
datatype a List = NIL(* A *) | CONS of ...(* B *)- 対応するトライの型:
TRIE of a option(* A *) * a Map M.Map(* B *) - lookup時等には、キーの各構築子に対応する、トライのフィールドを参照する:
- A部分:
lookup (NIL, TRIE(Option, _)) = do_something - B部分:
lookup (CONS(x, xs), TRIE(_, map)) = do_something
- A部分:
- 対応するトライの型:
- ルール:
r1 | r2 | ... | rk => a Map(r1) * a Map(r2) * ... * a Map(rk)a optionはa Mapの極端なケースとして考えられる (i.e. サイズが1までのマップ)
- キーの型の
- product: (本では
xと表記)- キーの型の
*部分:datatype Hoge = Fuga of A * B * C - 各フィールドは、トライの型の(中の対応するフィールドの)マップのネストに対応する
- キーの要素を検索するためには、全てのフィールド群を考慮する必要があるので、その階層関係をマップにも反映
- e.g. リストの場合:
CONS of a(* A *) * a List(* B *)- 対応するトライの型:
a Map(* B *) M.Map(* A *) - lookup関数:
lookup(ks, M.lookup(k, m)) - NOTE: NIL部分に関しては上述の通りなので省略 (optionがマップの一種と見做せる)
- 対応するトライの型:
- e.g. 木の場合:
NODE of a(* A *) * a Tree(* B *) * a Tree(* C *)- 対応するトライの型:
a Map(* C *) Map(* B *) M.Map(* A *) - lookup関数:
lookup(rgt, lookup(lft, M.lookup(k, m)))
- 対応するトライの型:
- ルール:
r1 * r2 * ... * rk => a Map(rk) ... Map(r2) Map(r1)
- キーの型の
- aggregateなキーの具体的な型に応じて、上のproduct/sumルールを適用していけば、任意のキーに対するトライ型が実装可能
これまでの章で扱った以下の二つのテクニックをimplicit-recursive-slowdownと呼ばれるものに一般化する:
- a. lazy-redundant-binary-numbers (9.2.3)
- 償却
O(1)のinc/decをサポート - !
lazy + safe-digitによって、再帰時に処理が連鎖しないようにした
- 償却
- b. non-uniform-types/polymorphic-recursion (10.1.2)
- 数値表現(e.g. ランダムアクセスリスト)の極めてシンプルな実装に寄与
- ! structural-decomposition: 再帰型を使うことでデータ型全体を簡潔に表現可能
- 補足: recursive-slowdownについて
- segmented-binary-numbersに基づくテクニック
- implicitとの差異は、{lazy,segmented}-binary-numbers間のそれと同様
! 実例はあるけど implicit-recursive-slowdown 自体についての説明が少ないような気がする
この章の主張の予測メモ:
-
- structural-decompositionにより簡潔かつ効率的な実装が可能
-
- binary-numbersを利用することにより、特性に応じたデータ構造のカスタマイズが容易
-
- lazyとsafe-digit管理により、再帰の連鎖をなくすことが可能 =>
O(1)達成!
- 実質、implicit-recursive-slowdownに直接関係するのはこれ(3)だけ?
- 1と2は、データ構造の実装や設計の際の補佐的な位置づけ?
- lazyとsafe-digit管理により、再帰の連鎖をなくすことが可能 =>
これまでの手法を組み合わせて、用途に応じた効率的なキューやデックが簡単に作れるという例:
- ベースには、10.1.2のランダムアクセスリストの変換版を用いる:
datatype a Digit = ZERO | ONE of adatatype a RList = SHALLOW of a Digit | DEEP of a Digit * (a * a) RList- NOTE: Digit専用の型を定義することで、(若干無駄だが)digitの値の調整等が行いやすくなる
- これに必要な特性を追加していく(以下は型の関係有る部分のみ記述):
- headの
O(1)が必要ならzeroless表現:a Digit = ONE of a | TWO of a * a - cons/headの
O(1)が必要ならlazy表現:a RList = DEEP of a Digit * (a * a) RList susp - キューやデックならリアリスト追加:
a RList = DEEP of a Digit * (a * a) RList * a Digit
- headの
- 今回はキューが欲しい:
- 要求: snoc/head/tailが
O(1)で実行可能 (償却 or 最悪) - 上の記述と下の表を参考に、構成を選択する
- 構成:
フロントデジット * ミドルキュー(再帰) * リアデジット - フロントデジットはONE/TWO, リアデジットはZERO/ONE、が適切
- NOTE: デックなら、リアもONE/TWOにする (for 効率的な要素取り出し用)
- 構成:
- 要求: snoc/head/tailが
- 最終的な型:
datatype a Digit = ZERO | ONE of a | TWO of a * adatatype a Queue = SHALLOW of a Digit | DEEP of a Digit * (a * a) Queue susp * a Digit
| O(1) supported functions | allowable digits |
|---|---|
| cons | ZERO, ONE |
| cons/head | ONE, TWO |
| head/tail | ONE, TWO |
| cons/head/tail | ONE, TWO, THREE |
(* snoc関数だけ抜粋: *)
(* - 数値表現の素直な実装なのは変わらず *)
(* - SHALLOWとDEEPの分岐が増えているのが若干冗長な印象 *)
fun snoc (SHALLOW ZERO, y) = SHALLOW (ONE y)
| snoc (SHALLOW (ONE x), y) = DEEP (TWO (x,y), $empty, ZERO)
| snoc (DEEP (f, m, ZERO), y) = DEEP (f, m, ONE y)
| snoc (DEEP (f, m, ONE x), y) = DEEP (f, $snoc (force m, (x,y)), ZERO)計算量:
- snoc/tail/headが
O(1)(head以外は償却) - 証明などは省略 (本を参照)
最後の例:
- ! 長いし複雑だしそれほど新しい概念は出てこなさそうなので省略
- 流れメモ:
- 要求: 効率的に結合可能なデックが欲しい!
-
- safe用の再帰デックを真ん中に挟むことで、cons/snoc/tail/initを償却
O(1)にする
datatype a Cat = Shallow of a D.Queue | DEEP of a D.Queue * a D.Queue Cat susp * a D.Queue- まだ
++が償却O(log n) - ! 再帰デックが、結合対象の両方のデックにとってdangerousだから連鎖する?
- safe用の再帰デックを真ん中に挟むことで、cons/snoc/tail/initを償却
-
- 真ん中の再帰デックをさらに三つに分割することで、
++も償却O(1)になる
- 結合対象の二つのデックの操作領域(dangerous)が競合しなくなったのて、処理(再帰)が連鎖しない (! おそらく)
datatype a CmpdElem = SIMPLE of a D.Queue | CMPD of a D.Queue * a CmpdElem Cat susp * a D.Queuedatatype a Cat = SHALLOW of a D.Queue | DEEP of a D.Queue * a CmpdElem Cat susp * a D.Queue * a CmpdElem Cat susp * a D.Queue
- 真ん中の再帰デックをさらに三つに分割することで、