Chronological list of the "systemd for Administrators" series published on 0pointer.net/blog:
jashkenas
/ wait-google-sent-me.js
Created
April 27, 2015 21:22
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| var active = false; | |
| function changeRefer(details) { | |
| if (!active) return; | |
| for (var i = 0; i < details.requestHeaders.length; ++i) { | |
| if (details.requestHeaders[i].name === 'Referer') { | |
| details.requestHeaders[i].value = 'http://www.google.com/'; | |
| break; | |
| } |
ZeccaLehn
/ pythonActualPrice.ipynb
Last active
July 10, 2023 10:10
Py: Adjust Splits and Dividends from Real Prices using Quandl Finance Data
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Daenyth
/ SlickUpsert.scala
Created
February 26, 2018 20:59
A slick profile extension to allow native postgres batch upsert
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import com.github.tminglei.slickpg.ExPostgresProfile | |
| import slick.SlickException | |
| import slick.ast.ColumnOption.PrimaryKey | |
| import slick.ast.{ColumnOption, FieldSymbol, Insert, Node, Select} | |
| import slick.compiler.{InsertCompiler, Phase, QueryCompiler} | |
| import slick.dbio.{Effect, NoStream} | |
| import slick.jdbc.InsertBuilderResult | |
| import slick.lifted.Query | |
| // format: off |
piyueh
/ tf_keras_tfp_lbfgs.py
Last active
April 28, 2025 04:09
Optimize TensorFlow & Keras models with L-BFGS from TensorFlow Probability
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #! /usr/bin/env python | |
| # -*- coding: utf-8 -*- | |
| # vim:fenc=utf-8 | |
| # | |
| # Copyright © 2019 Pi-Yueh Chuang <[email protected]> | |
| # | |
| # Distributed under terms of the MIT license. | |
| """An example of using tfp.optimizer.lbfgs_minimize to optimize a TensorFlow model. |
tamuhey
/ tokenizations_post.md
Last active
July 27, 2024 14:46
How to calculate the alignment between BERT and spaCy tokens effectively and robustly
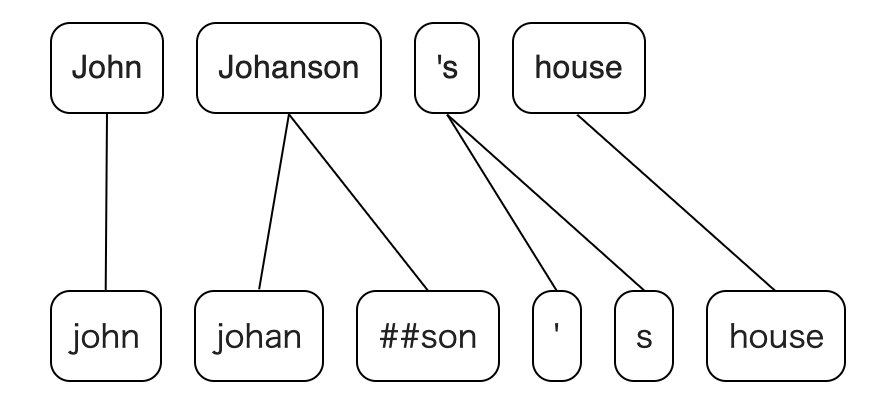
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links: