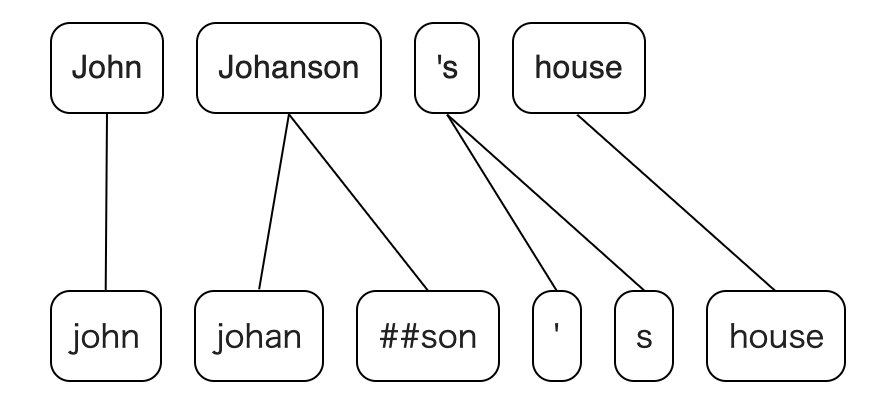
I wrote this answer on stackexchange, here: https://stackoverflow.com/posts/12597919/
It was wrongly deleted for containing "proprietary information" years later. I think that's bullshit so I am posting it here. Come at me.
Amazon is a SOA system with 100s of services (or so says Amazon Chief Technology Officer Werner Vogels). How do they handle build and release?