- 深層強化学習で 連続行動 と 視覚入力 を使ったものをまとめる
- 特に重要なテクニックが書かれていればそれも書き出す
- マルチモーダルな強化学習もあれば書いておく
- SAC のような形で、完全に actor と critic でネットワークを分けて CNN を2つ利用する
- actor と critic で CNN は共有するが、CNNの更新はcriticでのみしてactorはそれを利用する
- actor と critic で CNN を利用するが、CNNの更新はAuto encoderなど別のLossをつかう
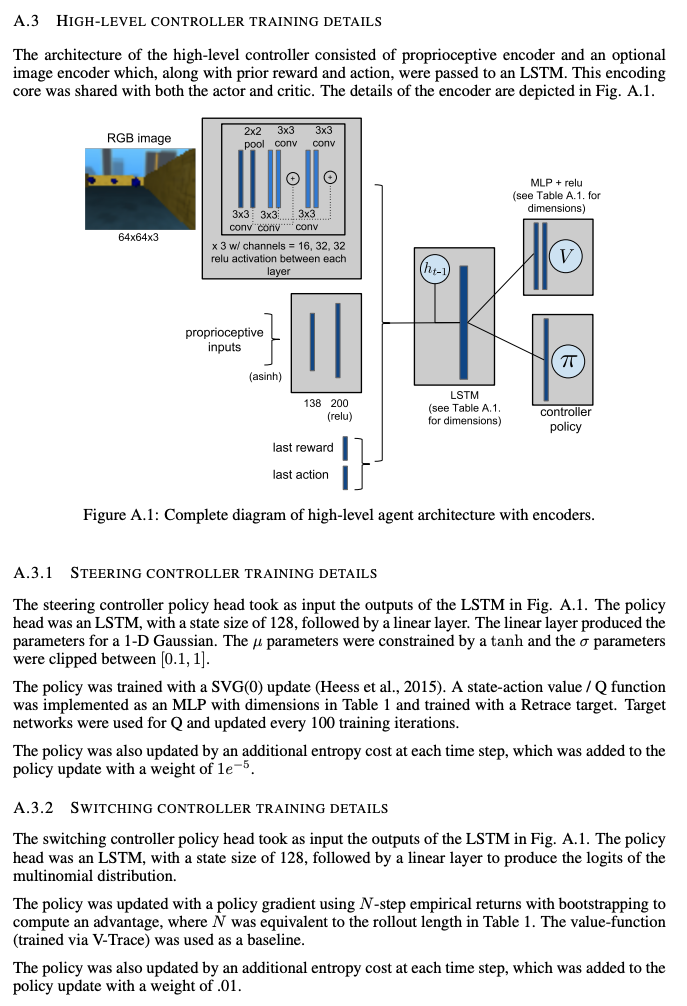
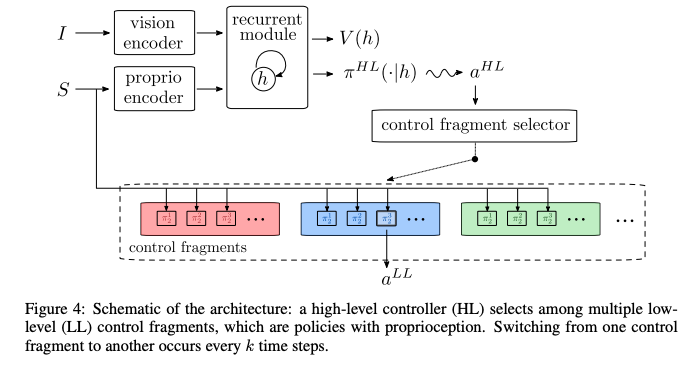




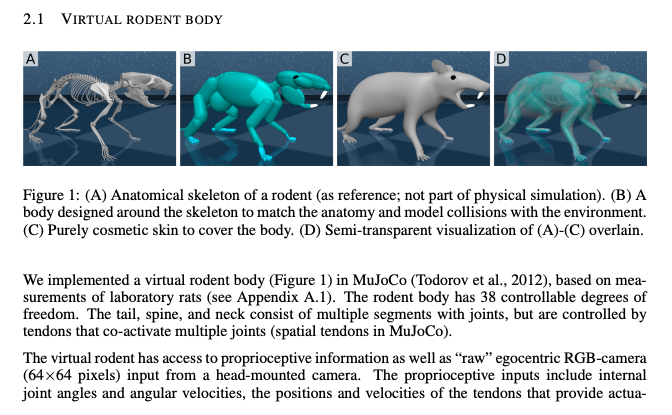

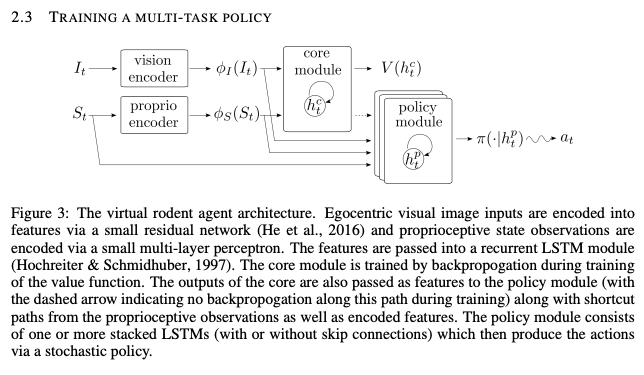


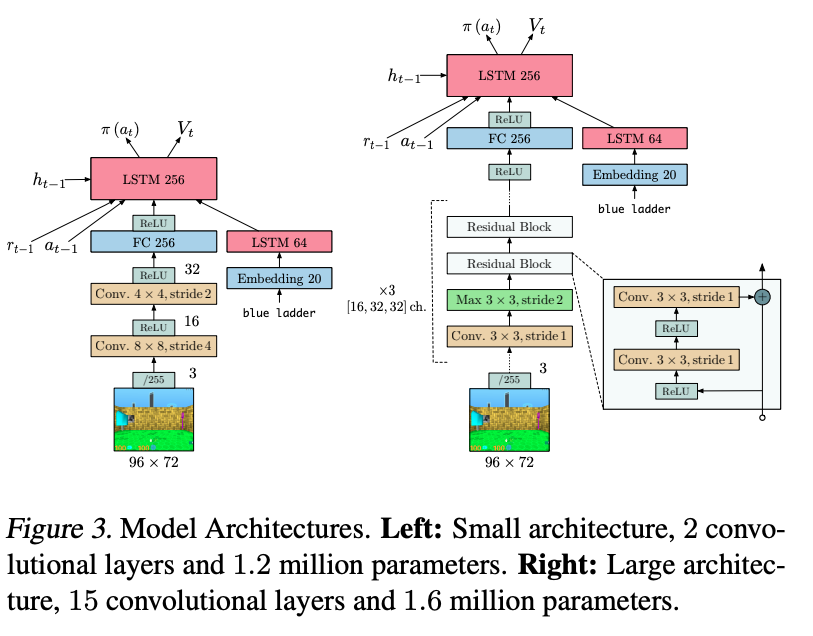

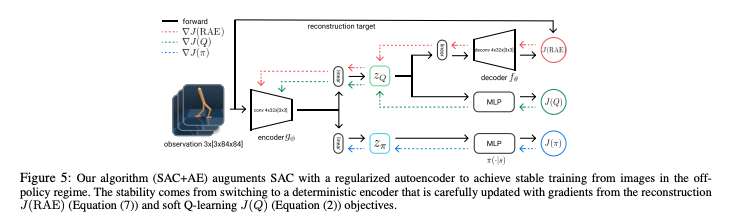










Yarats, Denis, et al. "Mastering Visual Continuous Control: Improved Data-Augmented Reinforcement Learning." arXiv preprint arXiv:2107.09645 (2021).
データのAugmentationで学習を向上させたDDPG(TD3)らしい
While some methods [Hafner et al., 2020] employ more sophisticated techniques such as TD(λ) or
Retrace(λ) [Munos et al., 2016], they are often computationally demanding when n is large. We find
that using simple n-step returns, without an importance sampling correction, strikes a good balance
between performance and efficiency