- 深層強化学習で 連続行動 と 視覚入力 を使ったものをまとめる
- 特に重要なテクニックが書かれていればそれも書き出す
- マルチモーダルな強化学習もあれば書いておく
- SAC のような形で、完全に actor と critic でネットワークを分けて CNN を2つ利用する
- actor と critic で CNN は共有するが、CNNの更新はcriticでのみしてactorはそれを利用する
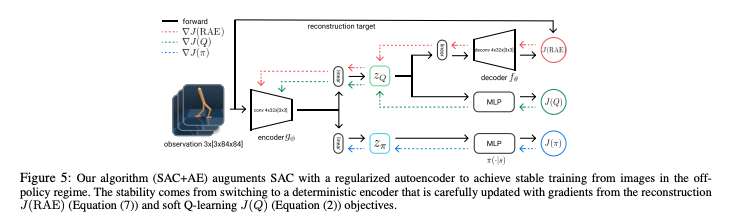
- actor と critic で CNN を利用するが、CNNの更新はAuto encoderなど別のLossをつかう


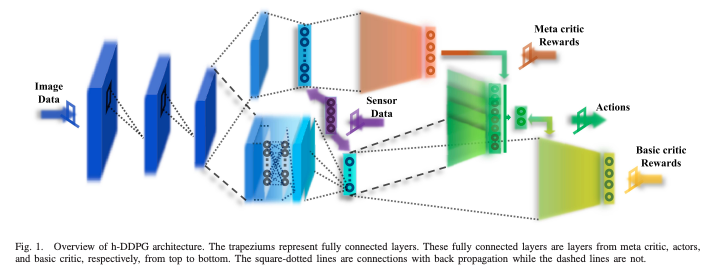



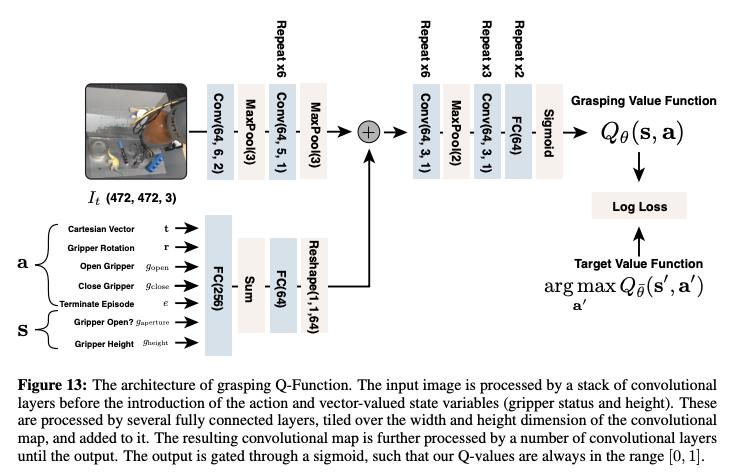
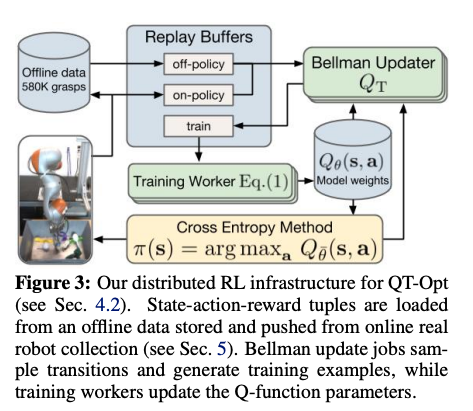




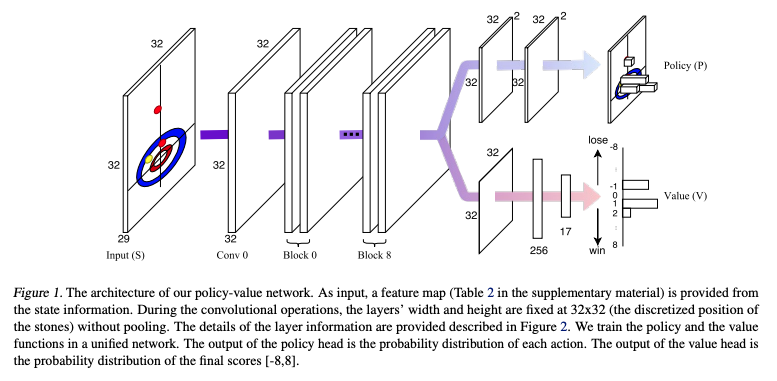
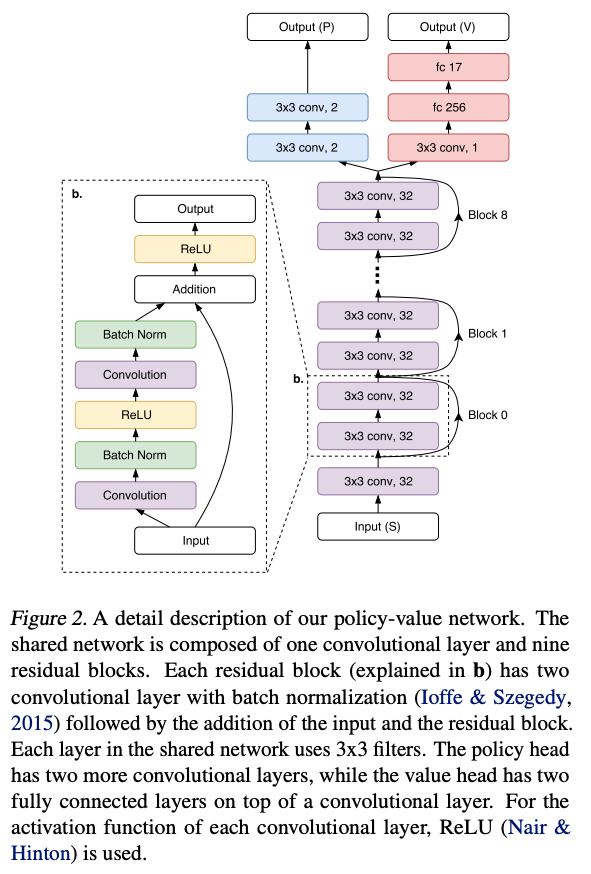
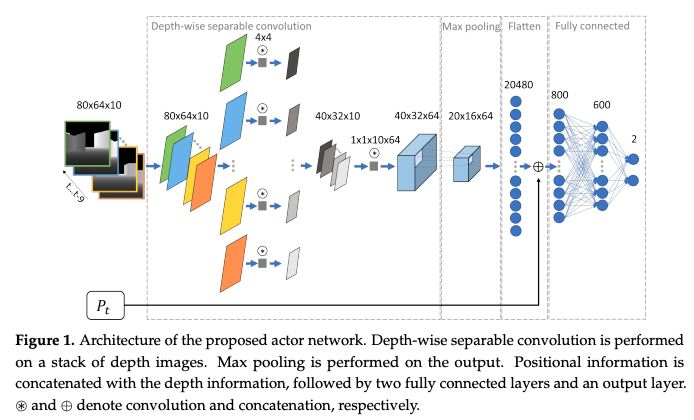
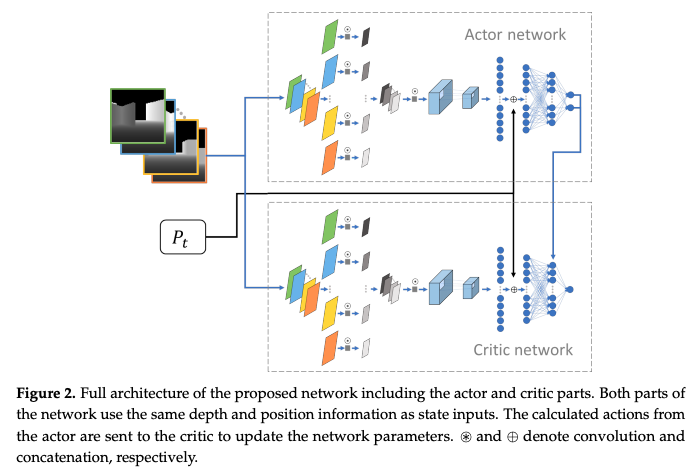
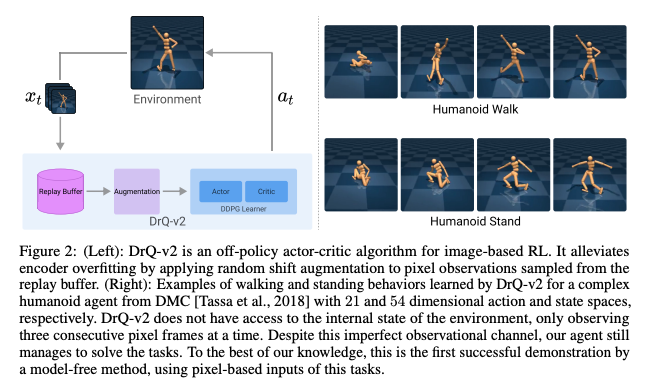




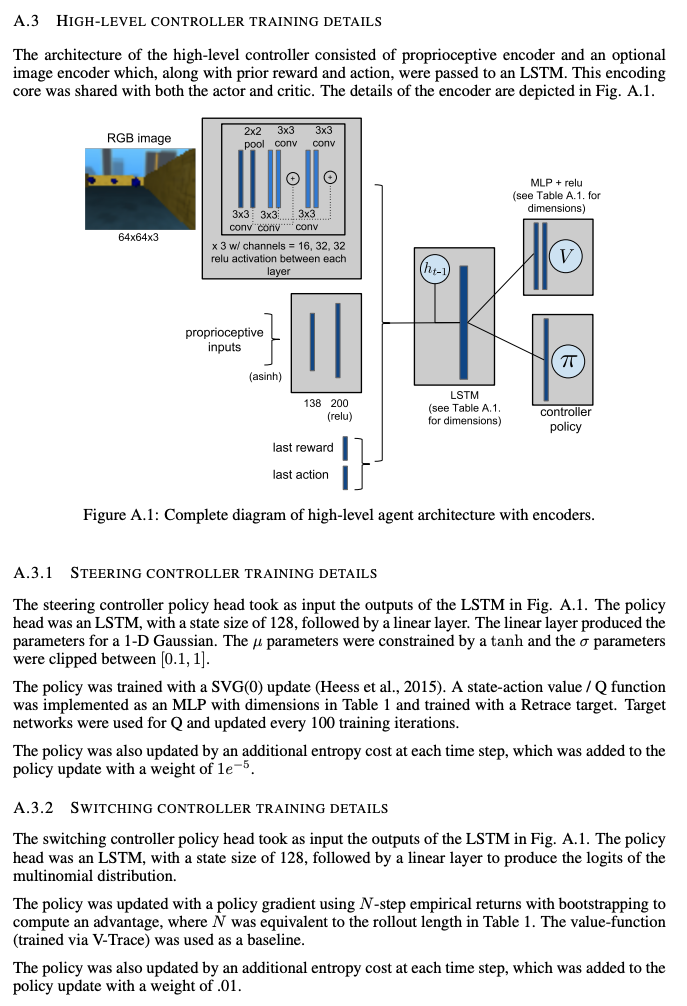
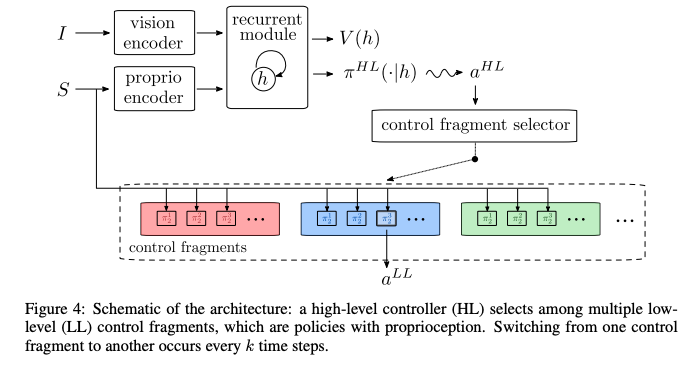




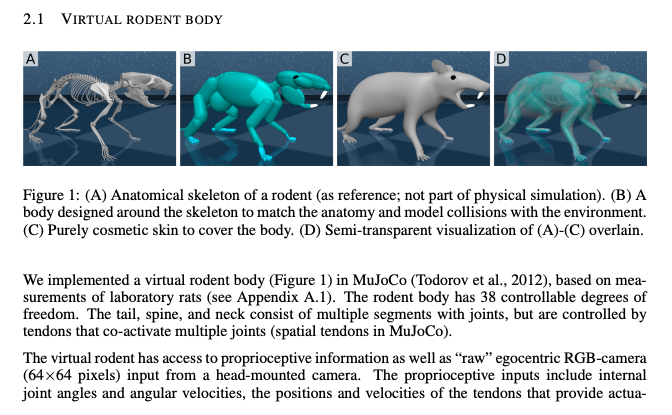

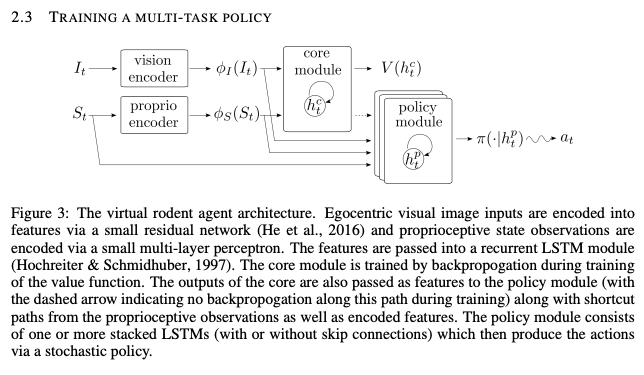


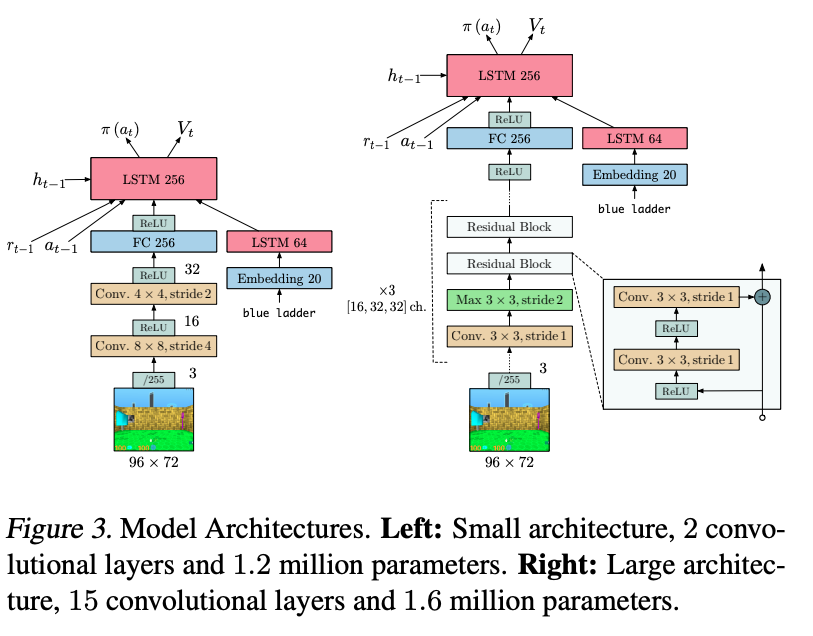
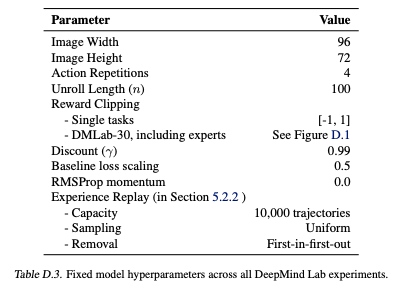











Mnih, Volodymyr, et al. "Asynchronous methods for deep reinforcement learning." International conference on machine learning. PMLR, 2016.
A3Cの論文
TORCS カーシミュレータ
Mujoco (pendulum, pointmass2D, and gripper)