Anders dataders
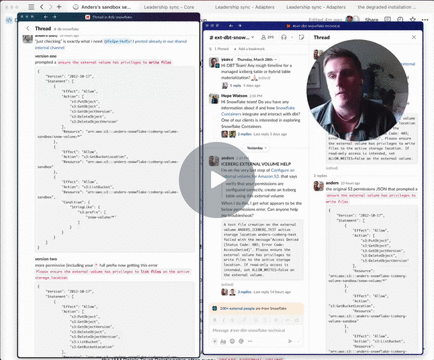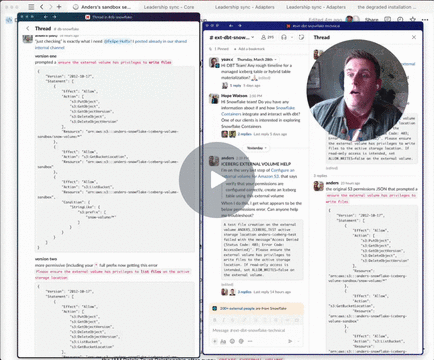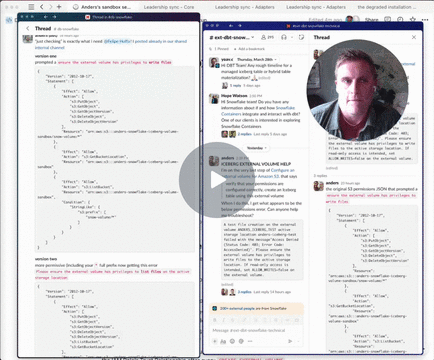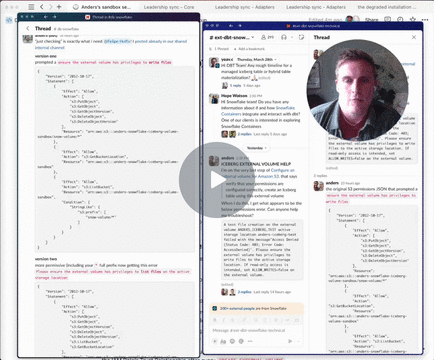
Info gotten from here
brew install unixodbc
export LDFLAGS="-L/opt/homebrew/Cellar/unixodbc/2.3.9_1/lib"
export CPPFLAGS="-I/opt/homebrew/Cellar/unixodbc/2.3.9_1/include"source: agilemanifesto.org/principles
Writing these up in a numbered, markdown-friendly list, because I'm nitpicky
Codd, Chomsky, McKinney, and Wickham walk into a bar… (maybe Chamberlain and Wittgenstein should also be included?)
- the dream of substrait is true separation b/w query engines and transformation APIs
- previously, particular APIs would give better performance due to their inextricable link to the architecture of the underlying compute engine
- if the above benefit is removed, folks could use the API with which they are most familiar
- given this, we could see an industry consolidation around the “best” transformation API.
| // Remove all drafts from your drafts view | |
| // Navigate to drafts | |
| // F12 to raise dev console | |
| // Paste the below | |
| (async function(x) { | |
| for (let e = document.querySelector('[type="trash"]'); e != null; e = document.querySelector('[type="trash"]')) { | |
| e.click(); | |
| await new Promise(resolve => setTimeout(resolve, 500)) | |
| document.querySelector('[data-qa="drafts_page_draft_delete_confirm"]').click(); | |
| await new Promise(resolve => setTimeout(resolve, 1500)) |
Tracking issue: #10600
Some things to consider:
Although sources and sinks are inverse concepts, sources have a one-to-many relationship with downstream relations, while sinks have a one-to-one relationship with upstream relations. Relations have a zero-to-many relationship with downstream sinks, though, which gets in the way of implementing them as inverse dbt concepts (e.g. using pre- and post-hooks).
Something else to consider is that source and sink configuration might have different ownership than model development in the wild (e.g. data engineers vs. analytics engineers), so it'd be preferable not to tightly couple them.
In order to keep filters up to date, please use this repo.
Make sure everyone in your household has signed up for these two things. They'll prolly take a few months to kick in.
DMA Choice Pay $2 for 10 years of opt-outs
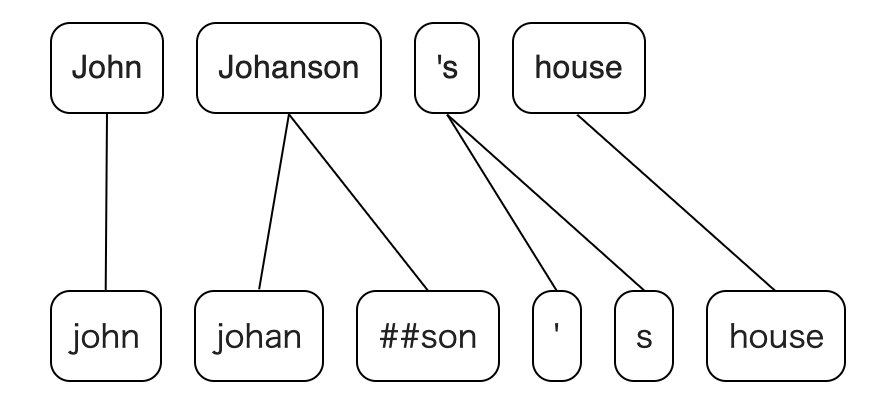
site: https://tamuhey.github.io/tokenizations/
Natural Language Processing (NLP) has made great progress in recent years because of neural networks, which allows us to solve various tasks with end-to-end architecture. However, many NLP systems still require language-specific pre- and post-processing, especially in tokenizations. In this article, I describe an algorithm that simplifies calculating correspondence between tokens (e.g. BERT vs. spaCy), one such process. And I introduce Python and Rust libraries that implement this algorithm. Here are the library and the demo site links: