-
Star
(209)
You must be signed in to star a gist -
Fork
(110)
You must be signed in to fork a gist
-
-
Save fchollet/f35fbc80e066a49d65f1688a7e99f069 to your computer and use it in GitHub Desktop.
| '''This script goes along the blog post | |
| "Building powerful image classification models using very little data" | |
| from blog.keras.io. | |
| It uses data that can be downloaded at: | |
| https://www.kaggle.com/c/dogs-vs-cats/data | |
| In our setup, we: | |
| - created a data/ folder | |
| - created train/ and validation/ subfolders inside data/ | |
| - created cats/ and dogs/ subfolders inside train/ and validation/ | |
| - put the cat pictures index 0-999 in data/train/cats | |
| - put the cat pictures index 1000-1400 in data/validation/cats | |
| - put the dogs pictures index 12500-13499 in data/train/dogs | |
| - put the dog pictures index 13500-13900 in data/validation/dogs | |
| So that we have 1000 training examples for each class, and 400 validation examples for each class. | |
| In summary, this is our directory structure: | |
| ``` | |
| data/ | |
| train/ | |
| dogs/ | |
| dog001.jpg | |
| dog002.jpg | |
| ... | |
| cats/ | |
| cat001.jpg | |
| cat002.jpg | |
| ... | |
| validation/ | |
| dogs/ | |
| dog001.jpg | |
| dog002.jpg | |
| ... | |
| cats/ | |
| cat001.jpg | |
| cat002.jpg | |
| ... | |
| ``` | |
| ''' | |
| import numpy as np | |
| from keras.preprocessing.image import ImageDataGenerator | |
| from keras.models import Sequential | |
| from keras.layers import Dropout, Flatten, Dense | |
| from keras import applications | |
| # dimensions of our images. | |
| img_width, img_height = 150, 150 | |
| top_model_weights_path = 'bottleneck_fc_model.h5' | |
| train_data_dir = 'data/train' | |
| validation_data_dir = 'data/validation' | |
| nb_train_samples = 2000 | |
| nb_validation_samples = 800 | |
| epochs = 50 | |
| batch_size = 16 | |
| def save_bottlebeck_features(): | |
| datagen = ImageDataGenerator(rescale=1. / 255) | |
| # build the VGG16 network | |
| model = applications.VGG16(include_top=False, weights='imagenet') | |
| generator = datagen.flow_from_directory( | |
| train_data_dir, | |
| target_size=(img_width, img_height), | |
| batch_size=batch_size, | |
| class_mode=None, | |
| shuffle=False) | |
| bottleneck_features_train = model.predict_generator( | |
| generator, nb_train_samples // batch_size) | |
| np.save(open('bottleneck_features_train.npy', 'w'), | |
| bottleneck_features_train) | |
| generator = datagen.flow_from_directory( | |
| validation_data_dir, | |
| target_size=(img_width, img_height), | |
| batch_size=batch_size, | |
| class_mode=None, | |
| shuffle=False) | |
| bottleneck_features_validation = model.predict_generator( | |
| generator, nb_validation_samples // batch_size) | |
| np.save(open('bottleneck_features_validation.npy', 'w'), | |
| bottleneck_features_validation) | |
| def train_top_model(): | |
| train_data = np.load(open('bottleneck_features_train.npy')) | |
| train_labels = np.array( | |
| [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2)) | |
| validation_data = np.load(open('bottleneck_features_validation.npy')) | |
| validation_labels = np.array( | |
| [0] * (nb_validation_samples / 2) + [1] * (nb_validation_samples / 2)) | |
| model = Sequential() | |
| model.add(Flatten(input_shape=train_data.shape[1:])) | |
| model.add(Dense(256, activation='relu')) | |
| model.add(Dropout(0.5)) | |
| model.add(Dense(1, activation='sigmoid')) | |
| model.compile(optimizer='rmsprop', | |
| loss='binary_crossentropy', metrics=['accuracy']) | |
| model.fit(train_data, train_labels, | |
| epochs=epochs, | |
| batch_size=batch_size, | |
| validation_data=(validation_data, validation_labels)) | |
| model.save_weights(top_model_weights_path) | |
| save_bottlebeck_features() | |
| train_top_model() |
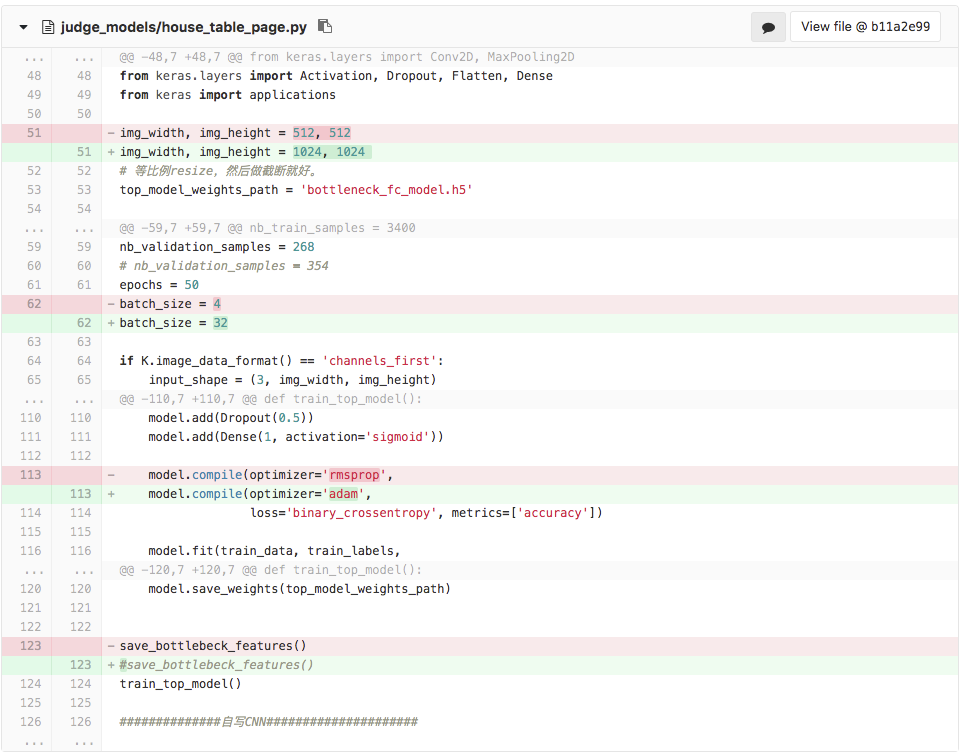
when change the optimizer to adam , it works fine
Sometimes my accuracy is coming around 90 to 94 % but most of the after running the same code it is coming exact 50%. I don'
t know what i wrong with my code
from keras.applications.vgg19 import VGG19
from keras.preprocessing import image
from keras.applications.vgg19 import preprocess_input
from keras.models import Model
import numpy as np
from keras_preprocessing.image import ImageDataGenerator, img_to_array,array_to_img, load_img
from keras.models import Sequential
from keras.metrics import binary_crossentropy
from keras.layers import Conv2D, Dense, MaxPool2D, Flatten, Activation, Dropout,MaxPooling2D
import matplotlib.pyplot as plt
base_model = VGG19(weights='imagenet')
model= Model(input=base_model.input, output=base_model.get_layer('block5_pool').output)
batch_size= 16
train_datagen= ImageDataGenerator(
rescale=1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip= True,
)
test_datagen= ImageDataGenerator(
rescale=1./255
)
train_generator = train_datagen.flow_from_directory(
'/home/kavita/Desktop/vision/datasets/dataset/training_set', # this is the target directory
target_size=(224, 224), # all images will be resized to 150x150
batch_size=batch_size,
class_mode='binary',
shuffle= False)
validation_generator = test_datagen.flow_from_directory(
'/home/kavita/Desktop/vision/datasets/dataset/test_set',
target_size=(224, 224),
batch_size=batch_size,
class_mode='binary',
shuffle= False)
predictvalidation=model.predict_generator(validation_generator,steps= 2000//batch_size)
predicttraining=model.predict_generator(train_generator,steps= 8000//batch_size)
validation_labels = np.array(
[0] * (1000) + [1] * (1000))
training_labels = np.array(
[0] * (4000) + [1] * (4000))
model= Sequential()
model.add(Flatten(input_shape=(7,7,512)))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model_history= model.fit(predicttraining, training_labels,
epochs=100,
batch_size=batch_size,
validation_data=(predictvalidation, validation_labels))
I am using this code for classifying ten class of faces using vgg facenet but getting a error can someone help
TypeError Traceback (most recent call last)
in
71
72 save_bottlebeck_features()
---> 73 train_top_model()
in train_top_model()
51 train_data = np.load(open('bottleneck_features_train.npy','rb'))
52 train_labels = np.array(
---> 53 [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
54
55 validation_data = np.load(open('bottleneck_features_validation.npy','rb'))
TypeError: can't multiply sequence by non-int of type 'float'
I am using this code for classifying ten class of faces using vgg facenet but getting a error can someone help
TypeError Traceback (most recent call last)
in
71
72 save_bottlebeck_features()
---> 73 train_top_model()in train_top_model()
51 train_data = np.load(open('bottleneck_features_train.npy','rb'))
52 train_labels = np.array(
---> 53 [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
54
55 validation_data = np.load(open('bottleneck_features_validation.npy','rb'))TypeError: can't multiply sequence by non-int of type 'float'
problem solved actually I created labels for two classes whereas my model has to clasify among 10 classes, so changed the train_label= np.array([0]*nb_train_samples/10+.......[9]*nb_train_samples/10)
Do we need an equal number of images in each class
Dears @biswagsingh @srikar2097 @drewszurko @aspiringguru
I run this but the network is clearly OVERFITTING. what is your idea to prevent it? I saw some folks said that the way to prevent it is to augment train data or increment train samples or add dropout layer.
I just wanna know what is your idea? did you find a way?
Fine tuned models' Prediction code
This codes were checked by myself. They all worked fine.
- If someone want to predict image classes in same model script where model were trained, here is the code :
img_width, img_height = 224, 224
batch_size = 1
datagen = ImageDataGenerator(rescale=1. / 255)
test_generator = datagen.flow_from_directory(
test_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
test_generator.reset()
pred= model.predict_generator(test_generator, steps = no_of_images/batch_size)
predicted_class_indices=np.argmax(pred, axis =1 )
labels = (train_generator.class_indices)
labels = dict((v, k) for k, v in labels.items())
predictions = [labels[k] for k in predicted_class_indices]
print(predicted_class_indices)
print (labels)
print (predictions)
This code is inspired by stack overflow answer. click here
- If someone want to predict image classes in different script (separate from training script file), here is the code :
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
import json
import os
from tensorflow.keras.models import model_from_json
#Just give below lines parameters
best_weights = 'path to .h5 weight file'
model_json = 'path to saved model json file'
test_dir = 'path to test images'
img_width, img_height = 224, 224
batch_size = 1
nb_img_samples = #no of testing images
with open(model_json, 'r') as json_file:
json_savedModel= json_file.read()
model = tf.keras.models.model_from_json(json_savedModel)
model.summary()
model.load_weights(best_weights)
datagen = ImageDataGenerator(rescale=1. / 255)
test_generator = datagen.flow_from_directory(
folder_path,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
test_generator.reset()
pred= model.predict_generator(test_generator, steps = nb_img_samples/batch_size)
predicted_class_indices=np.argmax(pred,axis=1)
labels = {'cats': 0, 'dogs': 1} #if you have more classes, just add like this in correct order where your training folder order.
labels = dict((v,k) for k,v in labels.items())
predictions = [labels[k] for k in predicted_class_indices]
print(predicted_class_indices)
print (labels)
print (predictions)
'''
I am using this code for classifying ten class of faces using vgg facenet but getting a error can someone help
TypeError Traceback (most recent call last)
in
71
72 save_bottlebeck_features()
---> 73 train_top_model()
in train_top_model()
51 train_data = np.load(open('bottleneck_features_train.npy','rb'))
52 train_labels = np.array(
---> 53 [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
54
55 validation_data = np.load(open('bottleneck_features_validation.npy','rb'))
TypeError: can't multiply sequence by non-int of type 'float'
'''
My solution: you can use '//' instead of '/', the last one would make the result be 'float',while the former one will get the result in 'int' type,which is required by the program.
Do we need an equal number of images in each class
Yes, because if we provide equal no of images then the model would be able to generalize well
Fine tuned models' Prediction code
This codes were checked by myself. They all worked fine.
- If someone want to predict image classes in same model script where model were trained, here is the code :
img_width, img_height = 224, 224 batch_size = 1 datagen = ImageDataGenerator(rescale=1. / 255) test_generator = datagen.flow_from_directory( test_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode=None, shuffle=False) test_generator.reset() pred= model.predict_generator(test_generator, steps = no_of_images/batch_size) predicted_class_indices=np.argmax(pred, axis =1 ) labels = (train_generator.class_indices) labels = dict((v, k) for k, v in labels.items()) predictions = [labels[k] for k in predicted_class_indices] print(predicted_class_indices) print (labels) print (predictions)This code is inspired by stack overflow answer. click here
- If someone want to predict image classes in different script (separate from training script file), here is the code :
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator import json import os from tensorflow.keras.models import model_from_json #Just give below lines parameters best_weights = 'path to .h5 weight file' model_json = 'path to saved model json file' test_dir = 'path to test images' img_width, img_height = 224, 224 batch_size = 1 nb_img_samples = #no of testing images with open(model_json, 'r') as json_file: json_savedModel= json_file.read() model = tf.keras.models.model_from_json(json_savedModel) model.summary() model.load_weights(best_weights) datagen = ImageDataGenerator(rescale=1. / 255) test_generator = datagen.flow_from_directory( folder_path, target_size=(img_width, img_height), batch_size=batch_size, class_mode=None, shuffle=False) test_generator.reset() pred= model.predict_generator(test_generator, steps = nb_img_samples/batch_size) predicted_class_indices=np.argmax(pred,axis=1) labels = {'cats': 0, 'dogs': 1} #if you have more classes, just add like this in correct order where your training folder order. labels = dict((v,k) for k,v in labels.items()) predictions = [labels[k] for k in predicted_class_indices] print(predicted_class_indices) print (labels) print (predictions)
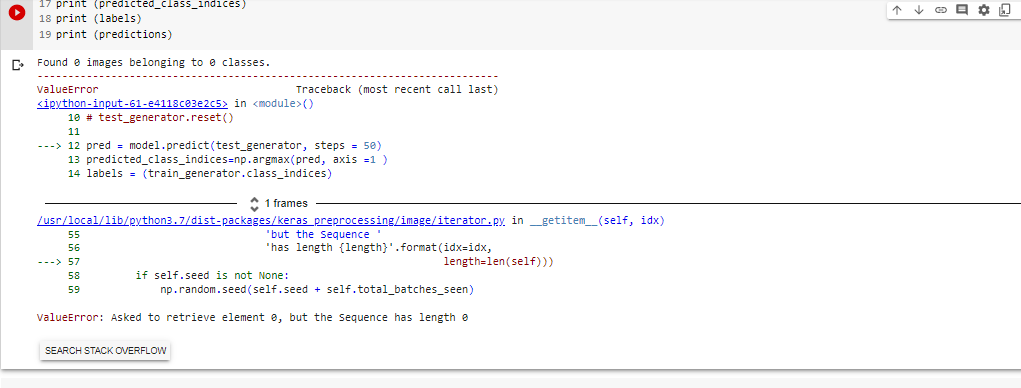
please help me, I got this error when running that codes, I want to predict image classes in same model script
please help me to rectify this following errors. because i am new to python.
thank you sir/madam
InvalidArgumentError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in _create_c_op(graph, node_def, inputs, control_inputs)
1658 try:
-> 1659 c_op = c_api.TF_FinishOperation(op_desc)
1660 except errors.InvalidArgumentError as e:
InvalidArgumentError: Negative dimension size caused by subtracting 2 from 1 for 'max_pooling2d_2/MaxPool' (op: 'MaxPool') with input shapes: [?,1,148,32].
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
in ()
2 model.add(Conv2D(32, (3, 3), input_shape=(3, 150, 150)))
3 model.add(Activation('relu'))
----> 4 model.add(MaxPooling2D(pool_size=(2, 2)))
5
6 model.add(Conv2D(32, (3, 3)))
/usr/local/lib/python3.6/dist-packages/keras/engine/sequential.py in add(self, layer)
179 self.inputs = network.get_source_inputs(self.outputs[0])
180 elif self.outputs:
--> 181 output_tensor = layer(self.outputs[0])
182 if isinstance(output_tensor, list):
183 raise TypeError('All layers in a Sequential model '
/usr/local/lib/python3.6/dist-packages/keras/engine/base_layer.py in call(self, inputs, **kwargs)
455 # Actually call the layer,
456 # collecting output(s), mask(s), and shape(s).
--> 457 output = self.call(inputs, **kwargs)
458 output_mask = self.compute_mask(inputs, previous_mask)
459
/usr/local/lib/python3.6/dist-packages/keras/layers/pooling.py in call(self, inputs)
203 strides=self.strides,
204 padding=self.padding,
--> 205 data_format=self.data_format)
206 return output
207
/usr/local/lib/python3.6/dist-packages/keras/layers/pooling.py in _pooling_function(self, inputs, pool_size, strides, padding, data_format)
266 output = K.pool2d(inputs, pool_size, strides,
267 padding, data_format,
--> 268 pool_mode='max')
269 return output
270
/usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py in pool2d(x, pool_size, strides, padding, data_format, pool_mode)
3976 x = tf.nn.max_pool(x, pool_size, strides,
3977 padding=padding,
-> 3978 data_format=tf_data_format)
3979 elif pool_mode == 'avg':
3980 x = tf.nn.avg_pool(x, pool_size, strides,
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/nn_ops.py in max_pool(value, ksize, strides, padding, data_format, name)
2746 padding=padding,
2747 data_format=data_format,
-> 2748 name=name)
2749
2750
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gen_nn_ops.py in max_pool(input, ksize, strides, padding, data_format, name)
5135 _, _, _op = _op_def_lib._apply_op_helper(
5136 "MaxPool", input=input, ksize=ksize, strides=strides, padding=padding,
-> 5137 data_format=data_format, name=name)
5138 _result = _op.outputs[:]
5139 _inputs_flat = _op.inputs
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py in _apply_op_helper(self, op_type_name, name, **keywords)
786 op = g.create_op(op_type_name, inputs, output_types, name=scope,
787 input_types=input_types, attrs=attr_protos,
--> 788 op_def=op_def)
789 return output_structure, op_def.is_stateful, op
790
/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/deprecation.py in new_func(*args, **kwargs)
505 'in a future version' if date is None else ('after %s' % date),
506 instructions)
--> 507 return func(*args, **kwargs)
508
509 doc = _add_deprecated_arg_notice_to_docstring(
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in create_op(failed resolving arguments)
3298 input_types=input_types,
3299 original_op=self._default_original_op,
-> 3300 op_def=op_def)
3301 self._create_op_helper(ret, compute_device=compute_device)
3302 return ret
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in init(self, node_def, g, inputs, output_types, control_inputs, input_types, original_op, op_def)
1821 op_def, inputs, node_def.attr)
1822 self._c_op = _create_c_op(self._graph, node_def, grouped_inputs,
-> 1823 control_input_ops)
1824
1825 # Initialize self._outputs.
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in _create_c_op(graph, node_def, inputs, control_inputs)
1660 except errors.InvalidArgumentError as e:
1661 # Convert to ValueError for backwards compatibility.
-> 1662 raise ValueError(str(e))
1663
1664 return c_op
ValueError: Negative dimension size caused by subtracting 2 from 1 for 'max_pooling2d_2/MaxPool' (op: 'MaxPool') with input shapes: [?,1,148,32].