-
Star
(209)
You must be signed in to star a gist -
Fork
(110)
You must be signed in to fork a gist
-
-
Save fchollet/f35fbc80e066a49d65f1688a7e99f069 to your computer and use it in GitHub Desktop.
| '''This script goes along the blog post | |
| "Building powerful image classification models using very little data" | |
| from blog.keras.io. | |
| It uses data that can be downloaded at: | |
| https://www.kaggle.com/c/dogs-vs-cats/data | |
| In our setup, we: | |
| - created a data/ folder | |
| - created train/ and validation/ subfolders inside data/ | |
| - created cats/ and dogs/ subfolders inside train/ and validation/ | |
| - put the cat pictures index 0-999 in data/train/cats | |
| - put the cat pictures index 1000-1400 in data/validation/cats | |
| - put the dogs pictures index 12500-13499 in data/train/dogs | |
| - put the dog pictures index 13500-13900 in data/validation/dogs | |
| So that we have 1000 training examples for each class, and 400 validation examples for each class. | |
| In summary, this is our directory structure: | |
| ``` | |
| data/ | |
| train/ | |
| dogs/ | |
| dog001.jpg | |
| dog002.jpg | |
| ... | |
| cats/ | |
| cat001.jpg | |
| cat002.jpg | |
| ... | |
| validation/ | |
| dogs/ | |
| dog001.jpg | |
| dog002.jpg | |
| ... | |
| cats/ | |
| cat001.jpg | |
| cat002.jpg | |
| ... | |
| ``` | |
| ''' | |
| import numpy as np | |
| from keras.preprocessing.image import ImageDataGenerator | |
| from keras.models import Sequential | |
| from keras.layers import Dropout, Flatten, Dense | |
| from keras import applications | |
| # dimensions of our images. | |
| img_width, img_height = 150, 150 | |
| top_model_weights_path = 'bottleneck_fc_model.h5' | |
| train_data_dir = 'data/train' | |
| validation_data_dir = 'data/validation' | |
| nb_train_samples = 2000 | |
| nb_validation_samples = 800 | |
| epochs = 50 | |
| batch_size = 16 | |
| def save_bottlebeck_features(): | |
| datagen = ImageDataGenerator(rescale=1. / 255) | |
| # build the VGG16 network | |
| model = applications.VGG16(include_top=False, weights='imagenet') | |
| generator = datagen.flow_from_directory( | |
| train_data_dir, | |
| target_size=(img_width, img_height), | |
| batch_size=batch_size, | |
| class_mode=None, | |
| shuffle=False) | |
| bottleneck_features_train = model.predict_generator( | |
| generator, nb_train_samples // batch_size) | |
| np.save(open('bottleneck_features_train.npy', 'w'), | |
| bottleneck_features_train) | |
| generator = datagen.flow_from_directory( | |
| validation_data_dir, | |
| target_size=(img_width, img_height), | |
| batch_size=batch_size, | |
| class_mode=None, | |
| shuffle=False) | |
| bottleneck_features_validation = model.predict_generator( | |
| generator, nb_validation_samples // batch_size) | |
| np.save(open('bottleneck_features_validation.npy', 'w'), | |
| bottleneck_features_validation) | |
| def train_top_model(): | |
| train_data = np.load(open('bottleneck_features_train.npy')) | |
| train_labels = np.array( | |
| [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2)) | |
| validation_data = np.load(open('bottleneck_features_validation.npy')) | |
| validation_labels = np.array( | |
| [0] * (nb_validation_samples / 2) + [1] * (nb_validation_samples / 2)) | |
| model = Sequential() | |
| model.add(Flatten(input_shape=train_data.shape[1:])) | |
| model.add(Dense(256, activation='relu')) | |
| model.add(Dropout(0.5)) | |
| model.add(Dense(1, activation='sigmoid')) | |
| model.compile(optimizer='rmsprop', | |
| loss='binary_crossentropy', metrics=['accuracy']) | |
| model.fit(train_data, train_labels, | |
| epochs=epochs, | |
| batch_size=batch_size, | |
| validation_data=(validation_data, validation_labels)) | |
| model.save_weights(top_model_weights_path) | |
| save_bottlebeck_features() | |
| train_top_model() |
Update :
Fixed the UnicodeDecodeError by following @ryanchase1987 solution to remove the open() functions.
After that got another error mentioned by @rk-ka - can't multiply sequence by non-int of type 'float'
Fixed the new error by following @jamiejwsmith's solution posted above !
Code ran fine after this.
Original:
hey @ryanchase1987 and everyone i received this error..
UnicodeDecodeError Traceback (most recent call last)
in ()
----> 1 train_top_model()
in train_top_model()
1 def train_top_model():
----> 2 train_data = np.load(open('bottleneck_features_train.npy'))
3 train_labels = np.array(
4 [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
5
/usr/local/lib/python3.6/dist-packages/numpy/lib/npyio.py in load(file, mmap_mode, allow_pickle, fix_imports, encoding)
400 _ZIP_PREFIX = b'PK\x03\x04'
401 N = len(format.MAGIC_PREFIX)
--> 402 magic = fid.read(N)
403 # If the file size is less than N, we need to make sure not
404 # to seek past the beginning of the file
/usr/lib/python3.6/codecs.py in decode(self, input, final)
319 # decode input (taking the buffer into account)
320 data = self.buffer + input
--> 321 (result, consumed) = self._buffer_decode(data, self.errors, final)
322 # keep undecoded input until the next call
323 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x93 in position 0: invalid start byte
VGG-16 uses 224 by 224 as input image size. But the size of image is 150 by 150 here. Does this not throw error ?
@orrimoch it can take up to 10 minutes, here's the expected output using a macbook pro - https://asciinema.org/a/rYD3A5TIpfKyOh0x3alQPFTqr
I stuck to the encoding problem.
train_data = np.load(open('bottleneck_features_train.npy')) #on this line
so please help me.....need any extra arguments for encoding
I use Windows platform.
So there seem to be a lot of people struggling to predict using the model. It's simple, just use the following code:
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input, decode_predictions
# assuming that model is your saved and trained model
model1 = applications.VGG16(include_top=False, weights='imagenet')
img = image.load_img('imagename.jpg', target_size=(img_width, img_height))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
features = model1.predict(x)
# this is where you get your prediction
prediction = model.predict(features)
@fchollet I think there is a typo on lines 56 and 110?
bottlebeck should be bottleneck
I am struggling with a problem with the line:
def train_top_model():
train_data = np.load(open('bottleneck_features_train.npy')
It gives me an error:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x93 in position 0: invalid start byte
I already went through the comments and changed:
np.save(open('bottleneck_features_train.npy', 'w'), bottleneck_features_train)
to
np.save(open('bottleneck_features_train.npy', 'wb'), bottleneck_features_train)
Can anyone guide me on this? Thanks in advance.
@dAmnation69 you would better save it with p.save('bottleneck_features_train.npy', bottleneck_features_train)
I have the problem of : AssertionError: Model weights not found (see "weights_path" variable in script). How can I solve it?
i did not understand what exactly is the output of model.predict_generator() . As far as i understand it returns probabilities of the predicted output. If this is the case it should give two probabilities( because in my case i have just two classes , CTAS and DOGS). Below is the code.
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense
from keras import applications
# dimensions of our images.
img_width, img_height = 150, 150
top_model_weights_path = 'bottleneck_fc_model.h5'
train_data_dir = 'data/train'
validation_data_dir = 'data/validation'
nb_train_samples = 2000
nb_validation_samples = 800
epochs = 1
batch_size = 16
def save_bottlebeck_features():
datagen = ImageDataGenerator(rescale=1. / 255)
# build the VGG16 network
model = applications.VGG16(include_top=False, weights='imagenet')
generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_train = model.predict_generator(generator, nb_train_samples // batch_size)
print bottleneck_features_train[0]
print len(bottleneck_features_train[0])
#np.save(open('bottleneck_features_train.npy', 'w'),bottleneck_features_train)
generator = datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_validation = model.predict_generator(generator, nb_validation_samples // batch_size)
np.save(open('bottleneck_features_validation.npy', 'w'),bottleneck_features_validation)
OUTPUT-
Found 2000 images belonging to 2 classes.
[[[0.33781648 0. 0. ... 0. 0.7219057 0. ]
[0.6693659 0. 0.6385117 ... 0.62694895 0.46536803 0. ]
[0.21631269 0. 1.5491495 ... 0.5128077 0.7058175 0. ]
[0. 0. 1.315388 ... 0. 0.5579962 0. ]]
[[0. 0. 0.00883913 ... 0.40895757 0.44412684 0. ]
[1.2532105 0. 0.53495556 ... 1.2629622 0. 0. ]
[1.778625 0. 1.4503732 ... 1.0395253 0.5776423 0. ]
[0.9886073 0. 1.4642671 ... 0.03808051 0.4825947 0.10377243]]
[[0.8991803 0. 0.21461597 ... 0. 0. 0. ]
[1.5715331 0. 0. ... 0. 0. 0. ]
[1.8199116 0. 0.55331445 ... 0. 0.7841213 0. ]
[0.9930389 0. 0.7045922 ... 0. 0.7249537 0. ]]
[[1.3933742 0. 0.21758774 ... 0. 0.69323623 0. ]
[1.6905686 0. 0.35357752 ... 0. 0. 0. ]
[1.4850118 0. 0.35679144 ... 0. 0.4410386 0. ]
[1.5115308 0. 0.3655101 ... 0. 0.33810174 0. ]]]
print("length is":4)
i do not understand what is this output of print bottleneck_features_train[0] represents.
This is the code that could be executed successfully after all above modifications. (Updated at 2018-09-23 16:47:09 UTC+8)
# This script goes along the blog post
# "Building powerful image classification models using very little data"
# from blog.keras.io.
# It uses data that can be downloaded at:
# https://www.kaggle.com/c/dogs-vs-cats/data
# In our setup, we:
# - created a data/ folder
# - created train/ and validation/ subfolders inside data/
# - created cats/ and dogs/ subfolders inside train/ and validation/
# - put the cat pictures index 0-999 in data/train/cats
# - put the cat pictures index 1000-1400 in data/validation/cats
# - put the dogs pictures index 12500-13499 in data/train/dogs
# - put the dog pictures index 13500-13900 in data/validation/dogs
# So that we have 1000 training examples for each class, and 400 validation examples for each class.
# In summary, this is our directory structure:
#
# data/
# train/
# dogs/
# dog001.jpg
# dog002.jpg
# ...
# cats/
# cat001.jpg
# cat002.jpg
# ...
# validation/
# dogs/
# dog001.jpg
# dog002.jpg
# ...
# cats/
# cat001.jpg
# cat002.jpg
# ...
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Flatten, Dense
from keras import applications
# dimensions of our images.
img_width, img_height = 150, 150
top_model_weights_path = 'bottleneck_fc_model.h5'
train_data_dir = 'data/train'
validation_data_dir = 'data/validation'
nb_train_samples = 2000
nb_validation_samples = 800
epochs = 50
batch_size = 16
def save_bottlebeck_features():
datagen = ImageDataGenerator(rescale=1. / 255)
# build the VGG16 network
model = applications.VGG16(include_top=False, weights='imagenet')
generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_train = model.predict_generator(
generator, nb_train_samples // batch_size)
np.save('bottleneck_features_train.npy',bottleneck_features_train)
generator = datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
bottleneck_features_validation = model.predict_generator(
generator, nb_validation_samples // batch_size)
np.save('bottleneck_features_validation.npy',bottleneck_features_validation)
def train_top_model():
train_data = np.load('bottleneck_features_train.npy')
train_labels = np.array([0] * (nb_train_samples // 2) + [1] * (nb_train_samples // 2))
validation_data = np.load('bottleneck_features_validation.npy')
validation_labels = np.array([0] * (nb_validation_samples // 2) + [1] * (nb_validation_samples // 2))
model = Sequential()
model.add(Flatten(input_shape=train_data.shape[1:]))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy', metrics=['accuracy'])
model.fit(train_data, train_labels,
epochs=epochs,
batch_size=batch_size,
validation_data=(validation_data, validation_labels))
model.save_weights(top_model_weights_path)
save_bottlebeck_features()
train_top_model()Hi @fchollet I have a doubt about how to use pre-trained models in Keras.
After reading a little bit on StackOverflow I got to the understanding that in order to extract the "bottleneck features" for a pre-trained model, one has to preprocess the images using the function preprocess_input that comes with the "application".
I think this is in agreement with what you explain in the documentation for the Applications module in the section "Extract features with VGG16"; in this example you import preprocess_input with the command from keras.applications.vgg16 import preprocess_input
and use it to pre-process the images before getting the predictions.
In the code for this tutorial, however, you simply divide the input by 255 (which as much as I understood is different from what the preprocess_input function does).
As I am a newbie to keras, this left me a bit confused. Can you please confirm that the right way is indeed to use preprocess_input?
If this is the case, I think that adding a note in the documentation for the "Applications" module and fixing this it in the tutorial would greatly help new keras users. I would be happy to give a small contribute by doing it myself if you let me know how to propose modifications to the documentation.
After some more brainstorming(and a lot more googling) I decided to move to the third part, BUT I got error
ValueError: The shape of the input to "Flatten" is not fully defined (got (None, None, 512). Make sure to pass a complete "input_shape" or "batch_input_shape" argument to the first layer in your model.
On this line
top_model.add(Flatten(input_shape=model.output_shape[1:]))Any help would be great and thankful
I get the same, have you found the solution?
@fchollet, other contributors
thanks to author for this highly useful tutorial, and the contributors to the discussion who made this workable.
One observation: when using MobileNet instead of VGG16, while leaving all other settings constant (2.000 training samples) the results are dramatically better --> beyond 97% accuracy without fine-tuning !
Despite MobileNet beeing a much smaller model.
Similarly when working on kaggles humpback whales I whitnessed Mobilenet outperforming all other (much larger) models.
My computer (CPU running) takes 30 minutes from reading the training data:
Found 2000 images belonging to 2 classes.
to the validation data:
Found 800 images belonging to 2 classes
and then 15 more minutes till it start the epochs. Any idea why it's sooo slow? thanks!
ValueError: Error when checking target: expected dense_2 to have shape (10,) but got array with shape (1,)
I am doing multi classification and changed like below but getting error like above.
model.add(Dense(10, activation='softmax'))
Also , using categorical_crossentropy and class_mode = "categorical"
Need help to fix the error .
I am running this exact code on the exact same data set, and the training accuracy increases as it should. However, the validation accuracy doesn't really change, but fluctuates at around 0.9 throughout the epochs as shown below.
I have set the correct nb_train_samples and nb_validation_samples. Has anyone encountered the same problem?
Epoch 1/50
2000/2000 [==============================] - 2s 1ms/step - loss: 0.8605 - acc: 0.7485 - val_loss: 0.2768 - val_acc: 0.8950
Epoch 2/50
2000/2000 [==============================] - 2s 762us/step - loss: 0.3825 - acc: 0.8425 - val_loss: 0.3534 - val_acc: 0.8525
Epoch 3/50
2000/2000 [==============================] - 2s 789us/step - loss: 0.3081 - acc: 0.8770 - val_loss: 0.2941 - val_acc: 0.9000
Epoch 4/50
2000/2000 [==============================] - 1s 424us/step - loss: 0.2840 - acc: 0.9010 - val_loss: 0.2561 - val_acc: 0.9038
Epoch 5/50
2000/2000 [==============================] - 2s 796us/step - loss: 0.2271 - acc: 0.9120 - val_loss: 0.2567 - val_acc: 0.9050
Epoch 6/50
2000/2000 [==============================] - 2s 781us/step - loss: 0.1999 - acc: 0.9275 - val_loss: 0.2762 - val_acc: 0.8912
Epoch 7/50
2000/2000 [==============================] - 2s 770us/step - loss: 0.1734 - acc: 0.9330 - val_loss: 0.4476 - val_acc: 0.8775
Epoch 8/50
2000/2000 [==============================] - 1s 419us/step - loss: 0.1598 - acc: 0.9450 - val_loss: 0.3374 - val_acc: 0.9050
Epoch 9/50
2000/2000 [==============================] - 2s 821us/step - loss: 0.1670 - acc: 0.9385 - val_loss: 0.3741 - val_acc: 0.8962
Epoch 10/50
2000/2000 [==============================] - 2s 770us/step - loss: 0.1374 - acc: 0.9445 - val_loss: 0.3605 - val_acc: 0.8850
Epoch 11/50
2000/2000 [==============================] - 2s 765us/step - loss: 0.1342 - acc: 0.9545 - val_loss: 0.3615 - val_acc: 0.9000
Epoch 12/50
2000/2000 [==============================] - 1s 336us/step - loss: 0.1187 - acc: 0.9605 - val_loss: 0.5038 - val_acc: 0.8738
Epoch 13/50
2000/2000 [==============================] - 1s 432us/step - loss: 0.0953 - acc: 0.9645 - val_loss: 0.8728 - val_acc: 0.8400
Epoch 14/50
2000/2000 [==============================] - 1s 633us/step - loss: 0.0849 - acc: 0.9745 - val_loss: 0.5279 - val_acc: 0.8875
Epoch 15/50
2000/2000 [==============================] - 2s 813us/step - loss: 0.0827 - acc: 0.9690 - val_loss: 0.5119 - val_acc: 0.8962
Epoch 16/50
2000/2000 [==============================] - 2s 819us/step - loss: 0.0663 - acc: 0.9755 - val_loss: 0.5435 - val_acc: 0.8938
Epoch 17/50
2000/2000 [==============================] - 1s 351us/step - loss: 0.0643 - acc: 0.9770 - val_loss: 0.5382 - val_acc: 0.9025
Hi, I am having dataset of 48 classes with 1000 images in each. With epoch memory in ram is slowly increasing and training is halting when my ram get full. Please help me out.
Thanks in advance.
please help me to rectify this following errors. because i am new to python.
thank you sir/madam
InvalidArgumentError Traceback (most recent call last)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in _create_c_op(graph, node_def, inputs, control_inputs)
1658 try:
-> 1659 c_op = c_api.TF_FinishOperation(op_desc)
1660 except errors.InvalidArgumentError as e:
InvalidArgumentError: Negative dimension size caused by subtracting 2 from 1 for 'max_pooling2d_2/MaxPool' (op: 'MaxPool') with input shapes: [?,1,148,32].
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
in ()
2 model.add(Conv2D(32, (3, 3), input_shape=(3, 150, 150)))
3 model.add(Activation('relu'))
----> 4 model.add(MaxPooling2D(pool_size=(2, 2)))
5
6 model.add(Conv2D(32, (3, 3)))
/usr/local/lib/python3.6/dist-packages/keras/engine/sequential.py in add(self, layer)
179 self.inputs = network.get_source_inputs(self.outputs[0])
180 elif self.outputs:
--> 181 output_tensor = layer(self.outputs[0])
182 if isinstance(output_tensor, list):
183 raise TypeError('All layers in a Sequential model '
/usr/local/lib/python3.6/dist-packages/keras/engine/base_layer.py in call(self, inputs, **kwargs)
455 # Actually call the layer,
456 # collecting output(s), mask(s), and shape(s).
--> 457 output = self.call(inputs, **kwargs)
458 output_mask = self.compute_mask(inputs, previous_mask)
459
/usr/local/lib/python3.6/dist-packages/keras/layers/pooling.py in call(self, inputs)
203 strides=self.strides,
204 padding=self.padding,
--> 205 data_format=self.data_format)
206 return output
207
/usr/local/lib/python3.6/dist-packages/keras/layers/pooling.py in _pooling_function(self, inputs, pool_size, strides, padding, data_format)
266 output = K.pool2d(inputs, pool_size, strides,
267 padding, data_format,
--> 268 pool_mode='max')
269 return output
270
/usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py in pool2d(x, pool_size, strides, padding, data_format, pool_mode)
3976 x = tf.nn.max_pool(x, pool_size, strides,
3977 padding=padding,
-> 3978 data_format=tf_data_format)
3979 elif pool_mode == 'avg':
3980 x = tf.nn.avg_pool(x, pool_size, strides,
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/nn_ops.py in max_pool(value, ksize, strides, padding, data_format, name)
2746 padding=padding,
2747 data_format=data_format,
-> 2748 name=name)
2749
2750
/usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/gen_nn_ops.py in max_pool(input, ksize, strides, padding, data_format, name)
5135 _, _, _op = _op_def_lib._apply_op_helper(
5136 "MaxPool", input=input, ksize=ksize, strides=strides, padding=padding,
-> 5137 data_format=data_format, name=name)
5138 _result = _op.outputs[:]
5139 _inputs_flat = _op.inputs
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/op_def_library.py in _apply_op_helper(self, op_type_name, name, **keywords)
786 op = g.create_op(op_type_name, inputs, output_types, name=scope,
787 input_types=input_types, attrs=attr_protos,
--> 788 op_def=op_def)
789 return output_structure, op_def.is_stateful, op
790
/usr/local/lib/python3.6/dist-packages/tensorflow/python/util/deprecation.py in new_func(*args, **kwargs)
505 'in a future version' if date is None else ('after %s' % date),
506 instructions)
--> 507 return func(*args, **kwargs)
508
509 doc = _add_deprecated_arg_notice_to_docstring(
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in create_op(failed resolving arguments)
3298 input_types=input_types,
3299 original_op=self._default_original_op,
-> 3300 op_def=op_def)
3301 self._create_op_helper(ret, compute_device=compute_device)
3302 return ret
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in init(self, node_def, g, inputs, output_types, control_inputs, input_types, original_op, op_def)
1821 op_def, inputs, node_def.attr)
1822 self._c_op = _create_c_op(self._graph, node_def, grouped_inputs,
-> 1823 control_input_ops)
1824
1825 # Initialize self._outputs.
/usr/local/lib/python3.6/dist-packages/tensorflow/python/framework/ops.py in _create_c_op(graph, node_def, inputs, control_inputs)
1660 except errors.InvalidArgumentError as e:
1661 # Convert to ValueError for backwards compatibility.
-> 1662 raise ValueError(str(e))
1663
1664 return c_op
ValueError: Negative dimension size caused by subtracting 2 from 1 for 'max_pooling2d_2/MaxPool' (op: 'MaxPool') with input shapes: [?,1,148,32].
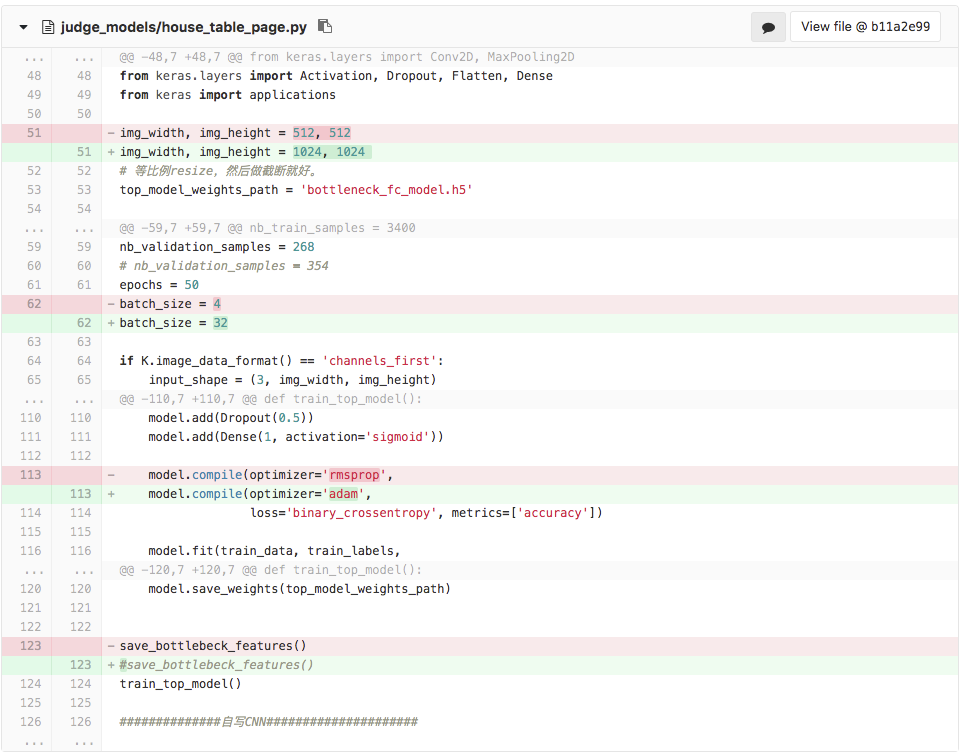
when change the optimizer to adam , it works fine
Sometimes my accuracy is coming around 90 to 94 % but most of the after running the same code it is coming exact 50%. I don'
t know what i wrong with my code
from keras.applications.vgg19 import VGG19
from keras.preprocessing import image
from keras.applications.vgg19 import preprocess_input
from keras.models import Model
import numpy as np
from keras_preprocessing.image import ImageDataGenerator, img_to_array,array_to_img, load_img
from keras.models import Sequential
from keras.metrics import binary_crossentropy
from keras.layers import Conv2D, Dense, MaxPool2D, Flatten, Activation, Dropout,MaxPooling2D
import matplotlib.pyplot as plt
base_model = VGG19(weights='imagenet')
model= Model(input=base_model.input, output=base_model.get_layer('block5_pool').output)
batch_size= 16
train_datagen= ImageDataGenerator(
rescale=1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip= True,
)
test_datagen= ImageDataGenerator(
rescale=1./255
)
train_generator = train_datagen.flow_from_directory(
'/home/kavita/Desktop/vision/datasets/dataset/training_set', # this is the target directory
target_size=(224, 224), # all images will be resized to 150x150
batch_size=batch_size,
class_mode='binary',
shuffle= False)
validation_generator = test_datagen.flow_from_directory(
'/home/kavita/Desktop/vision/datasets/dataset/test_set',
target_size=(224, 224),
batch_size=batch_size,
class_mode='binary',
shuffle= False)
predictvalidation=model.predict_generator(validation_generator,steps= 2000//batch_size)
predicttraining=model.predict_generator(train_generator,steps= 8000//batch_size)
validation_labels = np.array(
[0] * (1000) + [1] * (1000))
training_labels = np.array(
[0] * (4000) + [1] * (4000))
model= Sequential()
model.add(Flatten(input_shape=(7,7,512)))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model_history= model.fit(predicttraining, training_labels,
epochs=100,
batch_size=batch_size,
validation_data=(predictvalidation, validation_labels))
I am using this code for classifying ten class of faces using vgg facenet but getting a error can someone help
TypeError Traceback (most recent call last)
in
71
72 save_bottlebeck_features()
---> 73 train_top_model()
in train_top_model()
51 train_data = np.load(open('bottleneck_features_train.npy','rb'))
52 train_labels = np.array(
---> 53 [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
54
55 validation_data = np.load(open('bottleneck_features_validation.npy','rb'))
TypeError: can't multiply sequence by non-int of type 'float'
I am using this code for classifying ten class of faces using vgg facenet but getting a error can someone help
TypeError Traceback (most recent call last)
in
71
72 save_bottlebeck_features()
---> 73 train_top_model()in train_top_model()
51 train_data = np.load(open('bottleneck_features_train.npy','rb'))
52 train_labels = np.array(
---> 53 [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
54
55 validation_data = np.load(open('bottleneck_features_validation.npy','rb'))TypeError: can't multiply sequence by non-int of type 'float'
problem solved actually I created labels for two classes whereas my model has to clasify among 10 classes, so changed the train_label= np.array([0]*nb_train_samples/10+.......[9]*nb_train_samples/10)
Do we need an equal number of images in each class
Dears @biswagsingh @srikar2097 @drewszurko @aspiringguru
I run this but the network is clearly OVERFITTING. what is your idea to prevent it? I saw some folks said that the way to prevent it is to augment train data or increment train samples or add dropout layer.
I just wanna know what is your idea? did you find a way?
Fine tuned models' Prediction code
This codes were checked by myself. They all worked fine.
- If someone want to predict image classes in same model script where model were trained, here is the code :
img_width, img_height = 224, 224
batch_size = 1
datagen = ImageDataGenerator(rescale=1. / 255)
test_generator = datagen.flow_from_directory(
test_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
test_generator.reset()
pred= model.predict_generator(test_generator, steps = no_of_images/batch_size)
predicted_class_indices=np.argmax(pred, axis =1 )
labels = (train_generator.class_indices)
labels = dict((v, k) for k, v in labels.items())
predictions = [labels[k] for k in predicted_class_indices]
print(predicted_class_indices)
print (labels)
print (predictions)
This code is inspired by stack overflow answer. click here
- If someone want to predict image classes in different script (separate from training script file), here is the code :
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
import json
import os
from tensorflow.keras.models import model_from_json
#Just give below lines parameters
best_weights = 'path to .h5 weight file'
model_json = 'path to saved model json file'
test_dir = 'path to test images'
img_width, img_height = 224, 224
batch_size = 1
nb_img_samples = #no of testing images
with open(model_json, 'r') as json_file:
json_savedModel= json_file.read()
model = tf.keras.models.model_from_json(json_savedModel)
model.summary()
model.load_weights(best_weights)
datagen = ImageDataGenerator(rescale=1. / 255)
test_generator = datagen.flow_from_directory(
folder_path,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode=None,
shuffle=False)
test_generator.reset()
pred= model.predict_generator(test_generator, steps = nb_img_samples/batch_size)
predicted_class_indices=np.argmax(pred,axis=1)
labels = {'cats': 0, 'dogs': 1} #if you have more classes, just add like this in correct order where your training folder order.
labels = dict((v,k) for k,v in labels.items())
predictions = [labels[k] for k in predicted_class_indices]
print(predicted_class_indices)
print (labels)
print (predictions)
'''
I am using this code for classifying ten class of faces using vgg facenet but getting a error can someone help
TypeError Traceback (most recent call last)
in
71
72 save_bottlebeck_features()
---> 73 train_top_model()
in train_top_model()
51 train_data = np.load(open('bottleneck_features_train.npy','rb'))
52 train_labels = np.array(
---> 53 [0] * (nb_train_samples / 2) + [1] * (nb_train_samples / 2))
54
55 validation_data = np.load(open('bottleneck_features_validation.npy','rb'))
TypeError: can't multiply sequence by non-int of type 'float'
'''
My solution: you can use '//' instead of '/', the last one would make the result be 'float',while the former one will get the result in 'int' type,which is required by the program.
Do we need an equal number of images in each class
Yes, because if we provide equal no of images then the model would be able to generalize well
Fine tuned models' Prediction code
This codes were checked by myself. They all worked fine.
- If someone want to predict image classes in same model script where model were trained, here is the code :
img_width, img_height = 224, 224 batch_size = 1 datagen = ImageDataGenerator(rescale=1. / 255) test_generator = datagen.flow_from_directory( test_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode=None, shuffle=False) test_generator.reset() pred= model.predict_generator(test_generator, steps = no_of_images/batch_size) predicted_class_indices=np.argmax(pred, axis =1 ) labels = (train_generator.class_indices) labels = dict((v, k) for k, v in labels.items()) predictions = [labels[k] for k in predicted_class_indices] print(predicted_class_indices) print (labels) print (predictions)This code is inspired by stack overflow answer. click here
- If someone want to predict image classes in different script (separate from training script file), here is the code :
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator import json import os from tensorflow.keras.models import model_from_json #Just give below lines parameters best_weights = 'path to .h5 weight file' model_json = 'path to saved model json file' test_dir = 'path to test images' img_width, img_height = 224, 224 batch_size = 1 nb_img_samples = #no of testing images with open(model_json, 'r') as json_file: json_savedModel= json_file.read() model = tf.keras.models.model_from_json(json_savedModel) model.summary() model.load_weights(best_weights) datagen = ImageDataGenerator(rescale=1. / 255) test_generator = datagen.flow_from_directory( folder_path, target_size=(img_width, img_height), batch_size=batch_size, class_mode=None, shuffle=False) test_generator.reset() pred= model.predict_generator(test_generator, steps = nb_img_samples/batch_size) predicted_class_indices=np.argmax(pred,axis=1) labels = {'cats': 0, 'dogs': 1} #if you have more classes, just add like this in correct order where your training folder order. labels = dict((v,k) for k,v in labels.items()) predictions = [labels[k] for k in predicted_class_indices] print(predicted_class_indices) print (labels) print (predictions)
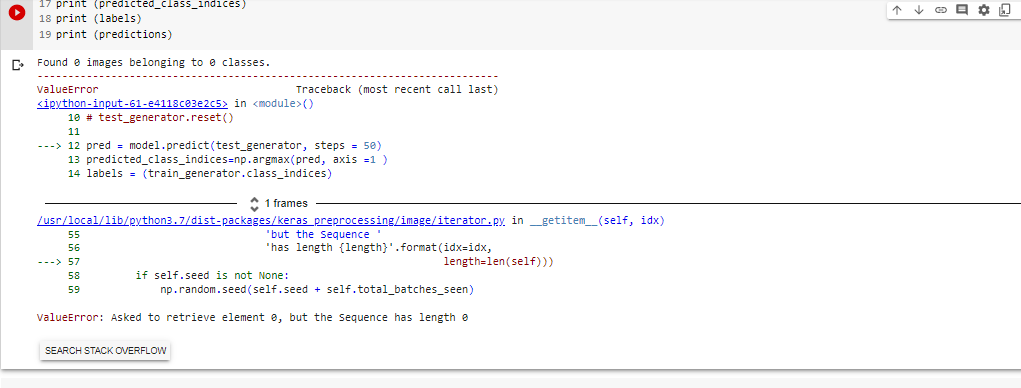
please help me, I got this error when running that codes, I want to predict image classes in same model script
Hi all,
I just got this script running using python 3.6. Wanted to provide some guidance as I ran into some of the same errors that others did.
The first error I got was:
"TypeError: write() argument must be str, not bytes"
…to avoid this error, just remove the open() functions nested in the np.save() function and np.load() function.
For example, replace:
Np.save(open('bottleneck_features_validation.npy', 'w'), bottleneck_features_validation)With:
Np.save('bottleneck_features_validation.npy', bottleneck_features_validation)And replace:
train_data = np.load(open('bottleneck_features_train.npy'))
With:
train_data = np.load('bottleneck_features_train.npy')
The second error I received was:
"ValueError: Input arrays should have the same number of samples as target arrays....""ValueError: Input arrays should have the same number of samples as target arrays...."
…this can be solved by ensuring the number of sample images that you set up in the directory for both the training and the test sets are wholly divisible by the number you select for you batch size, so that there is a whole number of iterations.